
Abstract
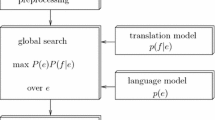
This paper presents a method for improving phrase-based Statistical Machine Translation systems by enriching the original translation model with information derived from a multilingual lexical knowledge base. The method proposed exploits the Multilingual Central Repository (a group of linked WordNets from different languages), as a domain-independent knowledge database, to provide translation models with new possible translations for a large set of lexical tokens. Translation probabilities for these tokens are estimated using a set of simple heuristics based on WordNet topology and local context. During decoding, these probabilities are softly integrated so they can interact with other statistical models. We have applied this type of domain-independent translation modeling to several translation tasks obtaining a moderate but significant improvement in translation quality consistently according to a number of standard automatic evaluation metrics. This improvement is especially remarkable when we move to a very different domain, such as the translation of Biblical texts.
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others

References
Sekine, S.: The Domain Dependence of Parsing. In: Proceedings of the Fifth Conference on Applied Natural Language Processing, pp. 96–102 (1997)
Escudero, G., Marquez, L., Rigau, G.: An Empirical Study of the Domain Dependence of Supervised Word Disambiguation Systems. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 172–180 (2000)
He, S., Gildea, D.: Self-training and Co-training for Semantic Role Labeling: Primary Report. Technical report, TR 891, Department of Computer Science, University of Rochester (2006)
Callison-Burch, C., Fordyce, C., Koehn, P., Monz, C., Schroeder, J.: (Meta-) Evaluation of Machine Translation. In: Proceedings of the ACL Workshop on Statistical Machine Translation, pp. 136–158 (2007)
Giménez, J., Màrquez, L.: Low-cost Enrichment of Spanish WordNet with Automatically Translated Glosses: Combining General and Specialized Models. In: Proceedings of COLING-ACL (2006)
Atserias, J., Villarejo, L., Rigau, G., Agirre, E., Carroll, J., Magnini, B., Vossen, P.: The MEANING Multilingual Central Repository. In: Proceedings of the 2nd Global WordNet Conference (GWC) (2004)
Fellbaum, C. (ed.): WordNet. An Electronic Lexical Database. The MIT Press, Cambridge (1998)
Giménez, J., Màrquez, L., Rigau, G.: Automatic Translation of WordNet Glosses. In: Proceedings of Cross-Language Knowledge Induction Workshop, EUROLAN Summer School (2005)
Brown, P.F., Cocke, J., Pietra, S.A.D., Pietra, V.J.D., Jelinek, F., Lafferty, J.D., Mercer, R.L., Roossin, P.S.: A statistical approach to machine translation. Computational Linguistics 16(2), 76–85 (1990)
Och, F.J., Ney, H.: Discriminative Training and Maximum Entropy Models for Statistical Machine Translation. In: Proceedings of the 40th ACL, pp. 295–302 (2002)
Koehn, P., Och, F.J., Marcu, D.: Statistical Phrase-Based Translation. In: Proceedings of the Joint Conference on Human Language Technology and the North American Chapter of the Association for Computational Linguistics (HLT-NAACL) (2003)
Och, F.J., Ney, H.: A Systematic Comparison of Various Statistical Alignment Models. Computational Linguistics 29(1), 19–51 (2003)
Och, F.J.: Statistical Machine Translation: From Single-Word Models to Alignment Templates. PhD thesis, RWTH Aachen, Germany (2002)
Stolcke, A.: SRILM - An Extensible Language Modeling Toolkit. In: Proceedings of ICSLP (2002)
Koehn, P.: Pharaoh: a Beam Search Decoder for Phrase-Based Statistical Machine Translation Models. In: Proceedings of AMTA (2004)
Giménez, J., Màrquez, L.: Context-aware Discriminative Phrase Selection for Statistical Machine Translation. In: Proceedings of the ACL Workshop on Statistical Machine Translation, pp. 159–166 (2007)
Giménez, J., Màrquez, L.: SVMTool: A general POS tagger generator based on Support Vector Machines. In: Proceedings of 4th LREC, pp. 43–46 (2004)
Carreras, X., Chao, I., Padró, L., Padró, M.: FreeLing: An Open-Source Suite of Language Analyzers. In: Proceedings of the 4th LREC, pp. 239–242 (2004)
Koehn, P.: Europarl: A Multilingual Corpus for Evaluation of Machine Translation. Technical report (2003), http://people.csail.mit.edu/people/koehn/publications/europarl/
Giménez, J., Amigó, E.: IQMT: A Framework for Automatic Machine Translation Evaluation. In: Proceedings of the 5th LREC, pp. 685–690 (2006)
Papineni, K., Roukos, S., Ward, T., Zhu, W.J.: Bleu: a method for automatic evaluation of machine translation, rc22176. Technical report, IBM T.J. Watson Research Center (2001)
Doddington, G.: Automatic evaluation of machine translation quality using n-gram co-occurrence statistics. In: Proceedings of the 2nd Internation Conference on Human Language Technology, pp. 138–145 (2002)
Nießen, S., Och, F.J., Leusch, G., Ney, H.: An Evaluation Tool for Machine Translation: Fast Evaluation for MT Research. In: Proceedings of the 2nd LREC (2000)
Tillmann, C., Vogel, S., Ney, H., Zubiaga, A., Sawaf, H.: Accelerated DP based Search for Statistical Translation. In: Proceedings of European Conference on Speech Communication and Technology (1997)
Melamed, I.D., Green, R., Turian, J.P.: Precision and Recall of Machine Translation. In: Proceedings of the Joint Conference on Human Language Technology and the North American Chapter of the Association for Computational Linguistics (HLT-NAACL) (2003)
Lin, C.Y., Och, F.J.: Automatic Evaluation of Machine Translation Quality Using Longest Common Subsequence and Skip-Bigram Statics. In: Proceedings of the 42nd ACL (2004)
Banerjee, S., Lavie, A.: METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. In: Proceedings of ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for MT and/or Summarization (2005)
Snover, M., Dorr, B., Schwartz, R., Micciulla, L., Makhoul, J.: A Study of Translation Edit Rate with Targeted Human Annotation. In: Proceedings of AMTA, pp. 223–231 (2006)
Giménez, J., Màrquez, L.: Discriminative Phrase Selection for Statistical Machine Translation. In: Learning Machine Translation. NIPS Workshop. MIT Press, Cambridge (2008)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2009 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
García, M., Giménez, J., Màrquez, L. (2009). Enriching Statistical Translation Models Using a Domain-Independent Multilingual Lexical Knowledge Base. In: Gelbukh, A. (eds) Computational Linguistics and Intelligent Text Processing. CICLing 2009. Lecture Notes in Computer Science, vol 5449. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-00382-0_25
Download citation
DOI: https://doi.org/10.1007/978-3-642-00382-0_25
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-642-00381-3
Online ISBN: 978-3-642-00382-0
eBook Packages: Computer ScienceComputer Science (R0)