
Abstract
SimRank is a well-known algorithm for similarity calculation based on object-to-object relationship. However, it suffers from high computation cost. In this paper, we find that the convergence behavior of different object pairs is different when we use SimRank to compute the similarity of objects. Many similarity scores converge fast, while others need more time before convergence. Based on this observation, we propose an adaptive method called Adaptive-SimRank to speed up similarity calculation. Using this method, we don’t need to recalculate those converged pairs’ similarity. The experiments conducted on web datasets and synthetic dataset show that our new method can reduce the running time by nearly 35%.
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others

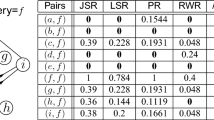
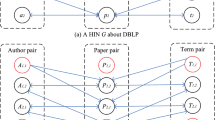
References
Jeh, G., Widom, J.: SimRank: A measure of structural-context similarity. In: SIGKDD (2002)
Small, H.: Co-citation in the scientific literature: A new measure of the relationship between two documents. Journal of the American Society for Information Science (1973)
Kessler, M.M.: Bibliographic coupling between scientific papers. American Documentation (1963)
Amsler, R.: Applications of citation-based automatic classification. Linguistic Research Center (1972)
Fogaras, D., Racz, B.: Scaling link-base similarity search. In: WWW (2005)
Yin, X.X., Han, J.W., Yu, P.S.: LinkClus: Efficient Clustering via Heterogeneous Semantic Links. In: VLDB (2006)
Jeh, G., Widom, J.: Scaling personalized web search, Technical report (2001)
Page, L., Brin, S., Motwani, R., References, T.: The PageRank citation ranking: Bringing order to the Web, Technical report (1998)
Langville, A.N., Meyer, C.D.: Deeper inside PageRank. Internet Math. J. (2003)
Kamvar, S., Haveliwala, T., Golub, G.: Adaptive Methods for the Computation of PageRank, Technical report (2003)
CMU four university data set, http://www.cs.cmu.edu/afs/cs/project/theo-20/www/data/
Han, J.W., Kamber, M.: Data Mining Concepts and Techniques. Morgan Kaufmann Publishers, San Francisco (2001)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2009 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Cai, Y., Liu, H., He, J., Du, X., Jia, X. (2009). An Adaptive Method for the Efficient Similarity Calculation. In: Zhou, X., Yokota, H., Deng, K., Liu, Q. (eds) Database Systems for Advanced Applications. DASFAA 2009. Lecture Notes in Computer Science, vol 5463. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-00887-0_31
Download citation
DOI: https://doi.org/10.1007/978-3-642-00887-0_31
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-642-00886-3
Online ISBN: 978-3-642-00887-0
eBook Packages: Computer ScienceComputer Science (R0)