
Abstract
SimRank is a well-known algorithm for similarity calculation based on link analysis. However, it suffers from high computational cost. It has been shown that the world web graph is a “small world graph”. In this paper, we observe that for this kind of small world graph, node pairs whose similarity scores are zero after first several iterations will remain zero in the final output. Based on this observation, we proposed a novel algorithm calledSW-SimRank to speed up similarity calculation by avoiding recalculating those unreachable pairs’ similarity scores. Our experimental results on web datasets showed the efficiency of our approach. The larger the proportion of unreachable pairs is in the relationship graph, the more improvement the SW-SimRank algorithm will achieve. In addition, SW-SimRank can be integrated with other SimRank acceleration methods.
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others

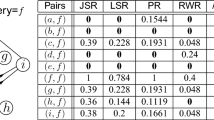
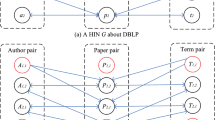
References
Jeh, G., Widom, J.: SimRank: A measure of structural-context similarity. In: SIGKDD, pp. 538–543 (2002)
Small, H.: Co-citation in the scientific literature: A new measure of the relationship between two documents. Journal of the American Society for Information Science 24(4), 265–269 (1973)
Kessler, M.M.: Bibliographic coupling between scientific papers. American Documentation 14(1), 10–25 (1963)
Amsler, R.: Applications of citation-based automatic classification. Linguistic Research Center (1972)
Fogaras, D., Racz, B.: Scaling link-based similarity search. In: WWW, pp. 641–650 (2005)
Yin, X.X., Han, J.W., Yu, P.S.: LinkClus: Efficient Clustering via Heterogeneous Semantic Links. In: VLDB, pp. 427–438 (2006)
Dmitry, L., Pavel, V., Maxim, G., Denis, T.: Accuracy Estimate and Optimization Techniques for SimRank Computation. In: VLDB, pp. 422–433 (2008)
Xi, W., Fox, E.A., Zhang, B., Cheng, Z.: SimFusion: Measuring Similarity Using Unified Relationship Matrix. In: SIGIR, pp. 130–137 (2005)
Pool, I., Kochen, M.: Contacts and influence, Social Network (1978)
Lada, A.A.: The Small World Web. In: Abiteboul, S., Vercoustre, A.-M. (eds.) ECDL 1999, vol. 1696, p. 443. Springer, Heidelberg (1999)
Langville, A.N., Meyer, C.D.: Deeper Inside PageRank. Internet Mathematics 1(3), 335–400 (2004)
Broder, A., Kumar, R., Maghoul, F., Raghavan, P., Rajagopalan, S., Stata, R., Tomkins, A., Wiener, J.: Graph Structure in the Web. In: WWW (2000)
CMU four university data set, http://www.cs.cmu.edu/afs/cs/project/theo-20/www/data/
Han, J.W., Kamber, M.: Data Mining Concepts and Techniques. Morgan Kaufmann Publishers, San Francisco (2001)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2009 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Jia, X., Cai, Y., Liu, H., He, J., Du, X. (2009). Calculating Similarity Efficiently in a Small World. In: Huang, R., Yang, Q., Pei, J., Gama, J., Meng, X., Li, X. (eds) Advanced Data Mining and Applications. ADMA 2009. Lecture Notes in Computer Science(), vol 5678. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-03348-3_19
Download citation
DOI: https://doi.org/10.1007/978-3-642-03348-3_19
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-642-03347-6
Online ISBN: 978-3-642-03348-3
eBook Packages: Computer ScienceComputer Science (R0)