
Abstract
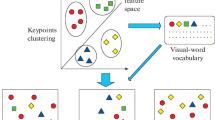
Recently, the bag-of-words (BOW) based image representation is getting popular in object categorization. However, there is no available visual vocabulary and it has to be learned. As to traditional learning methods, the vocabulary is constructed by exploring only one type of feature or simply concatenating all kinds of visual features into a long vector. Such constructions neglect distinct roles of different features on discriminating object categories. To address the problem, we propose a novel method to construct a conceptspecific visual vocabulary. First, we extract various visual features from local image patches, and cluster them separately according to different features to generate an initial vocabulary. Second, we formulate the concept-specific visual words selection and object categorization into a boosting framework. Experimental results on PASCAL 2006 challenge data set demonstrate the encouraging performance of the proposed method.
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others


References
Salton, G., McGill, M.: Introduction to Modern Information Retrieval. McGraw-Hill, New York (1981)
Lowe, D.G.: Distinctive Image Features from Scale-Invariant Keypoints. International Journal of Computer Vision 60(2), 91–110 (2004)
Sivic, J.S., Zisserman, A.: Video Google: A Text Retrieval Approach to Object Matching in Videos. In: 9th IEEE International Conference on Computer Vision, Nice, pp. 1470–1477 (2003)
Farquhar, J., Szedmak, S., Meng, H., Shawe-Taylor, J.: Improving “bag-of-keypoints” Image Categorization: Generative Models and PDF-Kernels. Technical report, University of Southampton (2005)
Perronnin, F., Dance, C., Csurka, G., Bressan, M.: Adapted Vocabularies for Generic Visual Categorization. In: Leonardis, A., Bischof, H., Pinz, A. (eds.) ECCV 2006. LNCS, vol. 3954, pp. 464–475. Springer, Heidelberg (2006)
Winn, K., Criminisi, A., Minka, T.: Object Categorization by Learned Universal Visual Dictionary. In: 10th IEEE International Conference on Computer Vision, Beijing, pp. 1800–1807 (2003)
Moosmann, F., Triggs, B., Jurie, F.: Fast Discriminative Visual Codebooks Using Randomized Clustering Forests. In: 20th Annual Conference on Neural Information Processing Systems, Hyatt, pp. 985–992 (2006)
Hsu, W.H., Chang, S.-F.: Visual Cue Cluster Construction via Information Bottleneck Principle and Kernel Density Estimation. In: 4th International Conference on Image and Video Retrieval, Singapore, pp. 82–91 (2005)
Freund, Y., Schapire, R.E.: Experiments with a New Boosting Algorithm. In: 13th International Conference on Machine Learning, Italy, pp. 148–156 (1996)
Everingham, M., Zisserman, A., Williams, C., Gool, L.: The 2006 PASCAL visual object classes challenge (2006)
Friedman, J., Hastie, T., Tibshirani, R.: Additive Logistic Regression: A Statistical View of Boosting. Annals of Statistics 28(2), 337–407 (2000)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2009 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Zhang, C., Liu, J., Ouyang, Y., Lu, H., Ma, S. (2009). Concept-Specific Visual Vocabulary Construction for Object Categorization. In: Muneesawang, P., Wu, F., Kumazawa, I., Roeksabutr, A., Liao, M., Tang, X. (eds) Advances in Multimedia Information Processing - PCM 2009. PCM 2009. Lecture Notes in Computer Science, vol 5879. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-10467-1_85
Download citation
DOI: https://doi.org/10.1007/978-3-642-10467-1_85
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-642-10466-4
Online ISBN: 978-3-642-10467-1
eBook Packages: Computer ScienceComputer Science (R0)