
Abstract
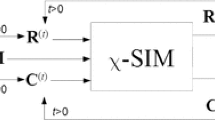
Clustering plays an important role in data mining as many applications use it as a preprocessing step for data analysis. Traditional clustering focuses on the grouping of similar objects, while two-way co-clustering can group dyadic data (objects as well as their attributes) simultaneously. Most co-clustering research focuses on single correlation data, but there might be other possible descriptions of dyadic data that could improve co-clustering performance. In this research, we extend ITCC (Information Theoretic Co-Clustering) to the problem of co-clustering with augmented matrix. We proposed CCAM (Co-Clustering with Augmented Data Matrix) to include this augmented data for better co-clustering. We apply CCAM in the analysis of on-line advertising, where both ads and users must be clustered. The key data that connect ads and users are the user-ad link matrix, which identifies the ads that each user has linked; both ads and users also have their feature data, i.e. the augmented data matrix. To evaluate the proposed method, we use two measures: classification accuracy and K-L divergence. The experiment is done using the advertisements and user data from Morgenstern, a financial social website that focuses on the advertisement agency. The experiment results show that CCAM provides better performance than ITCC since it consider the use of augmented data during clustering.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others


References
Agarwal, D., Merugu, S.: Predictive Discrete Latent Factor Models for Large Scale Dyadic Data. In: KDD 2007:Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 26–35. ACM press, San Jose (2007)
Banerjee, A., Dhillon, I.-S., Ghosh, J., Merugu, S., Modha, D.-S.: A Generalized Maximum Entropy Approach to Bregman Co-clustering and Matrix Approximation. In: KDD 2004: Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 509–514. ACM Press, Seattle (2004)
Chen, G., Wang, F., Zhang, C.: Collaborative filtering using orthogonal nonnegative matrix tri-factorization. In: Information Processing and Management, IPM, pp. 368–379 (2009)
Dai, W., Xue, G.-R., Yang, Q., Yu, Y.: Co-clustering based classification for out-of-domain documents. In: Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery And Data Mining, pp. 210–219. ACM Press, New York (2007)
Dhillon, I.-S., Mallela, S., Modha, D.-S.: Information Theoretic Co-Clustering. In: KDD 2003: Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 89–98. ACM Press, New York (2003)
Ding, C., He, X., Simon, H.-D.: On the equivalence of nonnegative matrix factorization and spectral clustering. In: Proceedings of the 5th SIAM International Conference on Data Mining, Newport Beach, CA, USA, pp. 606–610 (2005)
Ding, C., Li, T., Peng, W., Park, H.: Orthogonal nonnegative matrix tri-factorization for clustering. In: Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, pp. 126–135 (2006)
Li, B., Yang, Q., Xue, X.: Can Movies and Books Collaborate? Cross-Domain Collaborative Filtering for Sparsity Reduction. In: Proc of the 21st Int’l Joint Conf. on Artificial Intelligence (IJCAI 2009), pp. 2052–2057 (2009)
Long, B., Zhang, Z., Yu, P.-S.: Co-clustering by Block Value Decomposition. In: KDD 2005: Proceedings of the Eleventh ACM SIGKDD International Conference on Knowledge Discovery in Data Mining, pp. 635–640. ACM press, Chicago (2005)
Scott, D.-W.: Sturges’ rule. WIREs Computational Statistics 1, 303–306 (2009)
Shafiei, M., Milios, E.: Model-based Overlapping Co-Clustering. Supported by grants from the Natural Sciences and Engineering Research Council of Canada. IT Interactive Services Inc., GINIus Inc. (2005)
Shafiei, M., Milios, E.: Latent Dirichlet Co-Clustering. In: Perner, P. (ed.) ICDM 2006. LNCS (LNAI), vol. 4065, pp. 542–551. Springer, Heidelberg (2006)
Shan, H., Banerjee, A.: Bayesian Co-clustering. In: Perner, P. (ed.) ICDM 2008. LNCS (LNAI), vol. 5077, pp. 530–539. Springer, Heidelberg (2008)
Slonim, N., Tishby, N.: Document clustering using word clusters via the information bottleneck method. In: Proceedings of the 23rd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Athens, Greece, pp. 208–215 (2000)
Sugiyama, K., Hatano, K., Yoshikawa, M.: Adaptive web search based on user profile constructed without any effort from users. In: Proceedings of the 13th International Conference on World Wide Web, New York, NY, USA, pp. 675–684 (2004)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2011 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Wu, ML., Chang, CH., Liu, RZ. (2011). Co-clustering with Augmented Data Matrix. In: Cuzzocrea, A., Dayal, U. (eds) Data Warehousing and Knowledge Discovery. DaWaK 2011. Lecture Notes in Computer Science, vol 6862. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-23544-3_22
Download citation
DOI: https://doi.org/10.1007/978-3-642-23544-3_22
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-642-23543-6
Online ISBN: 978-3-642-23544-3
eBook Packages: Computer ScienceComputer Science (R0)