
Abstract
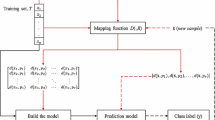
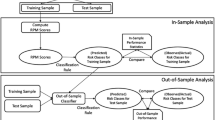
A comparative study over six learning scenarios in debt pattern recognition is presented in the paper. There are proposed new approaches for distance measure definitions in training set selection. Using those measures for training set selection the inference models are trained using distinct reference. All proposed approaches are examined in dataset selection during prediction of debt portfolio value. Finally, basic evaluation on prediction performance is conducted.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others

References
Cano, J.R., Herrera, F., Lozano, M.: Using evolutionary algorithms as instance selection for data reduction in KDD: an experimental study. IEEE Transactions on Evolutionary Computation 7(6), 561–575 (2003)
Cha, S.H.: Comprehensive survey on distance/similarity measures between probability density functions. International Journal of Mathematical Models and Methods in Applied Sciences 1(4), 300–307 (2007)
Coifman, R.R., Wickerhauser, M.V.: Entropy-based algorithms for best basis selection. IEEE Transactions on Information Theory 38, 713–718 (1992)
Demmel, J.: Applied Numerical Linear Algebra. SIAM (1997)
Deza, E., Deza, M.M.: Dictionary of Distances. Elsevier (2006)
Kajdanowicz, T., Kazienko, P.: Prediction of Sequential Values for Debt Recovery. In: Bayro-Corrochano, E., Eklundh, J.-O. (eds.) CIARP 2009. LNCS, vol. 5856, pp. 337–344. Springer, Heidelberg (2009)
Lu, Q., Getoor, L.: Link-based classification using labeled and unlabeled data. In: ICML 2003 Workshop on The Continuum from Labeled to Unlabeled Data in Machine Learning and Data Mining (2003)
Meyer, C.D.: Matrix analysis and applied linear algebra. Society for Industrial and Applied Mathematics (2000)
Rencher, A.: Methods of multivariate analysis. John Wiley & Sons (2002)
Son, S.-H., Kim, J.-Y.: Data Reduction for Instance-Based Learning Using Entropy-Based Partitioning. In: Gavrilova, M.L., Gervasi, O., Kumar, V., Tan, C.J.K., Taniar, D., Laganá, A., Mun, Y., Choo, H. (eds.) ICCSA 2006. LNCS, vol. 3982, pp. 590–599. Springer, Heidelberg (2006)
Theodoris, S., Koutroumbas, K.: Pattern Recognition. Elsevier (2009)
Toussaint, G.T.: Bibliography on estimation of misclassification. IEEE Transactions on Information Theory 20(4), 472–479 (1974)
Ullah, A.: Entropy, divergence and distance measures with econometric applications, Department of Economics, University of California - Riverside (1993)
Zhou, K., Doyle, K., Glover, K.: Robust and Optimal Control. Prentice Hall (1996)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2012 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Kajdanowicz, T., Plamowski, S., Kazienko, P. (2012). Distance Measures in Training Set Selection for Debt Value Prediction. In: Kundu, M.K., Mitra, S., Mazumdar, D., Pal, S.K. (eds) Perception and Machine Intelligence. PerMIn 2012. Lecture Notes in Computer Science, vol 7143. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-27387-2_28
Download citation
DOI: https://doi.org/10.1007/978-3-642-27387-2_28
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-642-27386-5
Online ISBN: 978-3-642-27387-2
eBook Packages: Computer ScienceComputer Science (R0)