
Abstract
In the face of the memory wall even in high bandwidth systems such as GPUs, an efficient handling of memory accesses and memory-related instructions is mandatory. Up to now, memory performance considerations were only made for GPGPU applications at source code level. This is not enough when optimizing an application towards high performance: The code has to be optimized at assembly level as well. Due to the spreading of GPGPU-capable hardware in smaller and smaller devices, the energy consumption of a program is – besides the performance – an important optimization goal.
In this paper, a novel compiler optimization technique, called FALIS (Feedback-based and memory-Aware gLobal Instruction Scheduling), is presented based on global instruction scheduling and multi-objective genetic algorithms. The approach uses a profiling-based feedback in order to take the measured performance and energy consumption values inside a compiler into account. Profiling on the real hardware platform is important in order to consider the characteristics of the underlying hardware. FALIS increases runtime performance of a GPGPU application by up to 13.02% and decreases energy consumption by up to 10.23%.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others


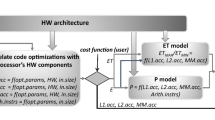
References
Banerjia, S., Havanki, W.A., Conte, T.M.: Treegion Scheduling for Highly Parallel Processors. In: Lengauer, C., Griebl, M., Gorlatch, S. (eds.) Euro-Par 1997. LNCS, vol. 1300, pp. 1074–1078. Springer, Heidelberg (1997)
De Bosschere, K., Luk, W., Martorell, X., Navarro, N., O’Boyle, M., Pnevmatikatos, D., Ramírez, A., Sainrat, P., Seznec, A., Stenström, P., Temam, O.: High-Performance Embedded Architecture and Compilation Roadmap. In: Stenström, P. (ed.) Transactions on High-Performance Embedded Architectures and Compilers I. LNCS, vol. 4050, pp. 5–29. Springer, Heidelberg (2007)
Che, S., Boyer, M., Meng, J., Tarjan, D., Sheaffer, J.W., Lee, S.H., Skadron, K.: Rodinia: A Benchmark Suite for Heterogeneous Computing. In: Proceedings of the IEEE International Symposium on Workload Characterization (IISWC), pp. 44–54 (2009)
Cho, S., Melhem, R.: Corollaries to Amdahl’s Law for Energy. IEEE Computer Architecture Letters, 25–28 (2008)
Dominguez, R., Kaeli, D.R.: Improving the open64 backend for GPUs. Poster at Google Summer School (2009)
Görlich, M.: Untersuchung und Verbesserung der Speicherzugriffsverteilung in GPGPU-Programmen unter Nutzung von lokalen Schedulingmethoden. Master’s thesis, Embedded System Group, Faculty of Computer Science, TU Dortmund (2011)
Han, T.D., Abdelrahman, T.S.: Reducing branch Divergence in GPU Programs. In: Proceedings of the Fourth Workshop on General Purpose Processing on Graphics Processing Units, pp. 1–8 (2011)
Hong, S., Kim, H.: An Analytical Model for a GPU Architecture with Memory-level and Thread-level Parallelism Awareness. In: Proceedings of the 36th Annual International Symposium on Computer Architecture (ISCA), pp. 152–163 (2009)
Kerns, D.R., Eggers, S.J.: Balanced Scheduling: Instruction Scheduling When Memory Latency is Uncertain. In: Proceedings of the ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI), pp. 278–289 (1993)
Kerr, A., Campbell, D., Richards, M.: GPU VSIPL: High-Performance VSIPL Implementation for GPUs. In: Proceedings of the 12th High Performance Embedded Computing Workshop (HPEC), Lexington, Massachusetts, USA (2008)
Kung, S.Y., Kailath, T., Whitehouse, H.J.: VLSI and Modern Signal Processing. Prentice Hall Professional Technical Reference (1984)
Leupers, R.: Instruction Scheduling for Clustered VLIW DSPs. In: Proceedings of the International Conference on Parallel Architecture and Compilation Techniques (PACT), pp. 291–300 (2000)
Machanick, P.: Approaches to Addressing the Memory Wall. Technical report, School of IT and Electrical Engineering, University of Queensland (2002)
NVIDIA Corporation: CUDA Architecture (2009)
NVIDIA Corporation: The CUDA Compiler Driver NVCC (2009)
Open64 Project at Rice University: Open64 Compiler: Whirl Intermediate Representation (2007), www.mcs.anl.gov/OpenAD/open64A.pdf
Owens, J., Luebke, D., Govindaraju, N., Harris, M., Krüger, J., Lefohn, A., Purcell, T.: A Survey of General-Purpose Computation on Graphics Hardware. Computer Graphics Forum, 80–113 (2007)
Risco-Martin, J.: Java Evolutionary COmputation library (JECO) (2012), https://sourceforge.net/projects/jeco
Rofouei, M., Stathopoulos, T., Ryffel, S., Kaiser, W., Sarrafzadeh, M.: Energy-Aware High Performance Computing with Graphic Processing Units. In: Proceedings of the Workshop on Power Aware Computing and Systems, HotPower (2008)
Timm, C., Gelenberg, A., Marwedel, P., Weichert, F.: Energy Considerations within the Integration of General Purpose GPUs in Embedded Systems. In: Proceedigns of the Annual Internation Conference on Advances in Distributed and Parallel Computing, ADPC (2010)
Timm, C., Weichert, F., Marwedel, P., Müller, H.: Multi-Objective Local Instruction Scheduling for GPGPU Applications. In: Proceedings of the International Conference on Parallel and Distributed Computing Systems, PDCS (2011)
Tseng, C.J., Siewiorek, D.: Automated Synthesis of Data Paths in Digital Systems. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 379–395 (1986)
Valluri, M., John, L.: Is Compiling for Performance == Compiling for Power? In: Proceedings oh the Workshop on Interaction between Compilers and Computer Architectures, INTERACT (2001)
Voorneveld, M.: Characterization of Pareto Dominance. Operations Research Letters, 7–11 (2003)
Wang, Z., Hu, X.S.: Energy-Aware Variable Partitioning and Instruction Scheduling for Multibank Memory Architectures. ACM Transactions on Design Automation of Electronic Systems (TODAES), 369–388 (2005)
Woo, D.H., Lee, H.H.: Extending Amdahl’s Law for Energy-Efficient Computing in the Many-Core Era. IEEE Computer, 24–31 (2008)
Zitzler, E., Giannakoglou, K., Tsahalis, D., Periaux, J., Papailiou, K., Fogarty, T., Ler, E.Z., Laumanns, M., Thiele, L.: SPEA2: Improving the Strength Pareto Evolutionary Algorithm For Multiobjective Optimization. In: Proceedings of the International Conference on Evolutionary and Deterministic Methods for Design, Optimization and Control with Applications to Industrial and Societal Problems, EUROGEN (2001)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2012 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Timm, C., Görlich, M., Weichert, F., Marwedel, P., Müller, H. (2012). Feedback-Based Global Instruction Scheduling for GPGPU Applications. In: Murgante, B., et al. Computational Science and Its Applications – ICCSA 2012. ICCSA 2012. Lecture Notes in Computer Science, vol 7333. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-31125-3_2
Download citation
DOI: https://doi.org/10.1007/978-3-642-31125-3_2
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-642-31124-6
Online ISBN: 978-3-642-31125-3
eBook Packages: Computer ScienceComputer Science (R0)