
Abstract
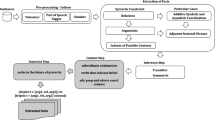
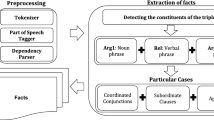
This paper proposes an information extraction model that identifies text patterns representing relations between two entities. It is proposed that, given a set of entity pairs representing a specific relation, it is possible to find text patterns representing such relation within sentences from documents containing those entites. After those text patterns are identified, it is possible to attempt the extraction of a complementary entity, considering the first entity of the relation and the related text patterns are provided. The pattern selection relies on regular expressions, frequency and identification of less relevant words. Modern search engines APIs and HTML parsers are used to retrieve and parse web pages in real time, eliminating the need of a pre-established corpus. The retrieval of document counts within a timeframe is also used to aid in the selection of the entities extracted.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others

References
Brin, S.: Extracting patterns and relations from the world wide web. In: Atzeni, P., Mendelzon, A.O., Mecca, G. (eds.) WebDB 1998. LNCS, vol. 1590, pp. 172–183. Springer, Heidelberg (1999)
Zhu, J., Nie, Z., Liu, X., Zhang, B., Wen, J.R.: StatSnowball: a statistical approach to extracting entity relationships. In: Proceedings of the 18th International Conference on World Wide Web, WWW 2009, pp. 101–110. ACM, New York (2009)
Etzioni, O., Cafarella, M., Downey, D., Popescu, A.M., Shaked, T., Soderland, S., Weld, D.S., Yates, A.: Unsupervised named-entity extraction from the web: An experimental study. Artif. Intell. 165(1), 91–134 (2005)
Yates, A., Cafarella, M., Banko, M., Etzioni, O., Broadhead, M., Soderland, S.: TextRunner: open information extraction on the web. In: Proceedings of Human Language Technologies: The Annual Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations. NAACL-Demonstrations 2007, Stroudsburg, PA, USA, pp. 25–26. Association for Computational Linguistics (2007)
Wu, F., Weld, D.S.: Open information extraction using Wikipedia. In: ACL, pp. 118–127 (2010)
Etzioni, O., Fader, A., Christensen, J., Soderland, S.: Mausam: Open information extraction: The second generation. In: Walsh, T. (ed.) IJCAI, IJCAI/AAAI, pp. 3–10 (2011)
Brucksen, M., Souza, J.G.C., Vieira, R., Rigo, S.: Sistema SeRELeP para o reconhecimento de relações entre entidades mencionadas. In: Mota, C., Santos, D. (eds.) Segundo HAREM, ch. 14, pp. 247–260. Linguateca (2008)
Cardoso, N.: REMBRANDT – Reconhecimento de entidades mencionadas baseado em relações e análise detalhada do texto. In: Mota, C., Santos, D. (eds.) Segundo HAREM, ch. 11, pp. 195–211. Linguateca (2008)
Santos, D., Seco, N., Cardoso, N., Vilela, R.: Harem: An advanced ner evaluation contest for portuguese. In: Odjik, Tapias, D. (eds.) Proceedings of LREC 2006 (LREC 2006), Genoa, pp. 22–28 (2006)
Lappin, S., Leass, H.J.: An algorithm for pronominal anaphora resolution. Comput. Linguist. 20(4), 535–561 (1994)
Interbrand: 2011 ranking of the top 100 brands, http://www.interbrand.com/en/best-global-brands/best-global-brands-2008/best-global-brands-2011.aspx (January 2012) (acessado: June 12, 2012)
CIA: The world factbook 2009. Central Intelligence Agency, Washington D.C (2009)
Corporation, G.: Google Custom Search API (January 2012), https://developers.google.com/custom-search/v1/overview (acessado: November 19, 2012)
Mourier, S.: Htmlagilitypack (October 2012), http://htmlagilitypack.codeplex.com (acessado: November 14, 2012)
Branco, A., Silva, J.A.: Evaluating Solutions for the Rapid Development of State-of-the-Art POS Taggers for Portuguese. In: Lino, M.T., Xavier, M.F., Ferreira, F., Costa, R., Silva, R. (eds.) LREC 2004, pp. 507–510 (2004)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2013 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Bonamigo, T.L., Vieira, R. (2013). A Model for Information Extraction in Portuguese Based on Text Patterns. In: Gelbukh, A. (eds) Computational Linguistics and Intelligent Text Processing. CICLing 2013. Lecture Notes in Computer Science, vol 7817. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-37256-8_30
Download citation
DOI: https://doi.org/10.1007/978-3-642-37256-8_30
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-642-37255-1
Online ISBN: 978-3-642-37256-8
eBook Packages: Computer ScienceComputer Science (R0)