
Abstract
We investigate the performance of our audio-visual speech recognition system in both English and Greek under the influence of audio noise. We present the architecture of our recently built system that utilizes information from three streams including 3-D distance measurements. The feature extraction approach used is based on the discrete cosine transform and linear discriminant analysis. Data fusion is employed using state-synchronous hidden Markov models. Our experiments were conducted on our recently collected database under a multi-speaker configuration and resulted in higher performance and robustness in comparison to an audio-only recognizer.
Chapter PDF
Similar content being viewed by others

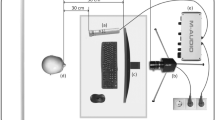

Keywords
References
Iwano, K., Tamura, S., Furui, S.: Bimodal speech recognition using lip movement measured by optical-flow analysis. In: Proc. HSC, pp. 187–190 (2001)
Nakamura, S., Ito, H., Shikano, K.: Stream weight optimization of speech and lip image sequence for audio-visual speech recognition. In: Proc. ICSLP, vol. 3, pp. 20–24 (2000)
Goecke, R., Millar, B.: The audio-video Australian English speech data corpus AVOZES. In: Proc. ICSLP, vol. 3, pp. 2525–2528 (2004)
Vorwerk, A., Wang, X., Kolossa, D., Zeiler, S., Orglmeister, R.: WAPUSK20 – a database for robust audiovisual speech recognition. In: Proc. LREC (2010)
Ortega, A., Sukno, F., Lleida, E., Frangi, A., Miguel, A., Buera, L., Zacur, E.: AV@CAR: A Spanish multichannel multimodal corpus for in-vehicle automatic audio-visual speech recognition. In: Proc. LREC., vol. 3, pp. 763–767 (2004)
The Primesensor Reference Design, http://www.primesensor.com
Galatas, G., Potamianos, G., Makedon, F.: Audio-visual speech recognition incorporating facial depth information captured by the Kinect. In: Proc. EUSIPCO, pp. 2714–2717 (2012)
Bishop, C.M.: Pattern Recognition and Machine Learning. Springer (2006)
Young, S.J., Kershaw, D., Odell, J., Ollason, D., Valtchev, V., Woodland, P.: The HTK Book version 3.4. Cambridge University Press (2006)
The HMM-based speech synthesis system (HTS), http://hts.sp.nitech.ac.jp
Galatas, G., Potamianos, G., Kosmopoulos, D., Mcmurrough, C., Makedon, F.: Bilingual corpus for AVASR using multiple sensors and depth information. In: Proc. AVSP, pp. 103–106 (2011)
Varga, A., Steeneken, H.: Assessment for automatic speech recognition: Noisex-92. A database and an experiment to study the effect of additive noise on speech recognition systems. Speech Communication 12(3), 247–251 (1993)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2013 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Galatas, G., Potamianos, G., Makedon, F. (2013). Robust Multi-Modal Speech Recognition in Two Languages Utilizing Video and Distance Information from the Kinect. In: Kurosu, M. (eds) Human-Computer Interaction. Interaction Modalities and Techniques. HCI 2013. Lecture Notes in Computer Science, vol 8007. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-39330-3_5
Download citation
DOI: https://doi.org/10.1007/978-3-642-39330-3_5
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-642-39329-7
Online ISBN: 978-3-642-39330-3
eBook Packages: Computer ScienceComputer Science (R0)