
Zusammenfassung
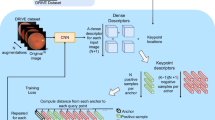
Ophthalmological imaging utilizes different imaging systems, such as color fundus, infrared, fluorescein angiography, optical coherence tomography (OCT) or OCT angiography. Multiple images with different modalities or acquisition times are often analyzed for the diagnosis of retinal diseases. Automatically aligning the vessel structures in the images by means of multi-modal registration can support the ophthalmologists in their work. Our method uses a convolutional neural network to extract features of the vessel structure in multi-modal retinal images. We jointly train a keypoint detection and description network on small patches using a classification and a cross-modal descriptor loss function and apply the network to the full image size in the test phase. Our method demonstrates the best registration performance on our and a public multi-modal dataset in comparison to competing methods.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Preview
Unable to display preview. Download preview PDF.
Similar content being viewed by others


Literatur
Chen J, Tian J, Lee N, Zheng J, Smith RT, Laine AF. A partial intensity invariant feature descriptor for multimodal retinal image registration. IEEE Trans Biomed Eng. 2010;57(7):1707–18.
Lee J, Liu P, Cheng J, Fu H. A deep step pattern representation for multimodal retinal image registration. Proc IEEE ICCV. 2019:5076–85.
Truong P, Apostolopoulos S, Mosinska A, Stucky S, Ciller C, Zanet SD. GLAMpoints: greedily learned accurate match points. Proc IEEE ICCV. 2019:10732–41.
Wang Y, Zhang J, Cavichini M, Bartsch DUG, Freeman WR, Nguyen TQ et al. Robust content-adaptive global registration for multimodal retinal images using weakly supervised deep-learning framework. IEEE Trans Image Process. 2021;30:3167–78.
DeTone D, Malisiewicz T, Rabinovich A. SuperPoint: self-supervised interest point detection and description. Proc IEEE CVPR. 2018.
Sindel A, Maier A, Christlein V. CraquelureNet: matching the crack structure in historical paintings for multi-modal image registration. Proc IEEE ICIP. 2021:994–8.
He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. Proc IEEE CVPR. 2016:770–8.
Fischler MA, Bolles RC. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography. Commun ACM. 1981;24(6):381–95.
Hajeb Mohammad Alipour S, Rabbani H, Akhlaghi MR. Diabetic retinopathy grading by digital curvelet transform. Comput Math Methods Med. 2012;2021:761901.
Jau YY, Zhu R, Su H, Chandraker M. Deep keypoint-based camera pose estimation with geometric constraints. Proc IEEE IROS. 2020:4950–7.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 Der/die Autor(en), exklusiv lizenziert an Springer Fachmedien Wiesbaden GmbH, ein Teil von Springer Nature
About this paper

Cite this paper
Sindel, A. et al. (2022). A Keypoint Detection and Description Network Based on the Vessel Structure for Multi-modal Retinal Image Registration. In: Maier-Hein, K., Deserno, T.M., Handels, H., Maier, A., Palm, C., Tolxdorff, T. (eds) Bildverarbeitung für die Medizin 2022. Informatik aktuell. Springer Vieweg, Wiesbaden. https://doi.org/10.1007/978-3-658-36932-3_12
Download citation
DOI: https://doi.org/10.1007/978-3-658-36932-3_12
Published:
Publisher Name: Springer Vieweg, Wiesbaden
Print ISBN: 978-3-658-36931-6
Online ISBN: 978-3-658-36932-3
eBook Packages: Computer Science and Engineering (German Language)