
Abstract
The attention-based image caption framework has been widely explored in recent years. However, most techniques generate next word conditioned on previous words and current visual contents, while the relationship between the semantic and visual contents is not considered. In this paper, we present a novel framework which can explore the relevance and coherence at the same time. The relevance tries to explore the relationship between the semantic and visual contents in a semantic-visual embedding space, and the coherence is introduced to maximize the probability of generating the next word according to previous words and the current visual contents. The performance of our model is tested with three benchmark datasets: Flickr8k, Flickr30k and MS COCO. The experimental results show that the proposed approach can improve the performance of attention-based image caption method.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Image Caption is an integrated problem that integrates computer vision and natural language processing. The main task is given an image, the computer will generate a reasonable sentence to describe it. This task is easy for people but difficult for computers. Because it requires computers not only to know what objects and scene in the picture, but also to capture the relationships between objects and objects, also the relationships between objects and scene. Here, relationships include spatial location, attributes, actions and so on. Also, it needs a language model that is strong enough to generate reasonable sentences to describe a picture after fully understanding it. The generated sentences should be reasonable enough without any grammatical and logical errors. Image caption can be used in many scenes. For examples, it can be used to assist visually impaired people and report incident of surveillance. Moreover, it also can be applied to robotic vision and multi-media search tasks.

An example of image caption.
Figure 1 shows an example of attention-based image caption generation. Given an image, we first use a convolution neural network to obtain a set of feature maps (from low-level) which can preserve much visual information, then utilize attention model to generate a visual representation from those feature maps and last we use Multi-Layer Perception to decode this visual representation to generate next word.
Recently, most existing image caption language models mainly maximize the probability of next word given the image and previous words. This describes how the image and previous words influences the next. The context relationships among the generated words can be guaranteed by this way. However, those models do not explore the relationships between the semantic and visual contents. As a result, the generated sentences from those existing approaches may be logically correct but the semantics (e.g. subjects, verbs or objects) in the sentences are wrong. For example, the sentence generated by existing approaches model for the image in Fig. 1 may be ‘a man is hitting a volleyball’, which is correct in logic but the subject ‘man’ (‘woman’ or ‘girl’ is correct) is not relevant to the image contents.
In [12], the context relationships mentioned above are defined as coherence, while the relationships between the semantic and visual contents are defined as relevance. In [12], the coherence and relevance were explored simultaneously for video description task. However, for image caption task, most existing methods only explored the coherence, while the relevance has not been explored. Specifically, as video description is similar to image description, so we first extend the work of [12] to image caption task which can explore the coherence and relevance simultaneously. Moreover, our method is also based on [21], which will be compared with, to validate the effectiveness of relevance.
2 Related Work
Recently, inspired by the successful use of sequence to sequence training with neural networks for machine translation, several methods based on deep neural networks have been proposed for image caption task. The first to use neural networks for image caption generation was Kiros et al. [8], who used a multi-modal log-bilinear model. Mao et al. [11] used a new approach to generate descriptions which is similar to [8], but Mao used a recurrent neural network as language model instead of a feed-forward one. Similarly, Vinyals et al. [19] and Donahue et al. [3] used LSTM as their language models.
All of above works encoder input image as a single feature vector. But Karpathy and Fei-Fei [6] proposed a method to create a joint embedding space to explore the similarity between the semantic and visual contents, and then generate description sentences. Fang et al. [4] proposed a model incorporating object detections. This model divided the caption generation into several parts: word detection through a CNN, caption candidates through a maximum entropy model, and sentence re-ranking through a deep multi-modal semantic model. Tran et al. [18] followed Fang’s work [4]. They tried to address the challenges of describing images in the wild by adding an entity recognition model. The entity recognition model was used to identify celebrities and landmarks.
In [21], Xu et al. first added attention mechanisms to encoder-decoder image caption model conditions on the next word generation at each time step. Lu et al. [10] proposed an adaptive attention model via a visual sentinel. This model learnt to decide when and where to attend to the image for word generation at each time step.
Yao et al. [22] proposed a model named Long Short-Term Memory with Attributes (LSTM-A). LSTM-A presented attribute concept and added attributes into a based image caption framework [19]. More recently, as the exposure bias [14] and non-differentiable task metric issues can be addressed by Reinforcement Learning (RL) [17], in [14], Ranzato et al. used REINFORCE algorithm [20] to directly optimize non-differentiable and sequence-based test metrics to overcome both exposure bias and non-differentiable task metric issues. Rennie et al. [15] constructed a framework which used a new optimization approach called self-critical sequence training (SCST). Now this framework obtains state-of-the-art results on the MS COCO evaluation sever.
3 Model
Our goal is to generate good description sentences for images. In this section, we first describe the basic attention image caption model, and then we present a joint loss measuring the relevance and coherence simultaneously.

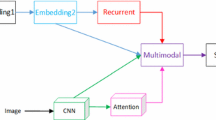
An illustration of attention-based model.
3.1 Word Embedding and Convolutional Networks
Our model takes a scaled image as input and generates a sentence S encoded as a sequence of words. We first encode each word as one-hot vector, thus the dimension of feature vector \(\mathbf{{x}}_i\), i.e. V, is the vocabulary size.
where, \(\mathbf{{E}} \in {\mathbf{{R}}^{m*V}}\) is an embedding matrix. m is embedding dimensionality and L is the length of the sentence. Then we use a 2D Convolutional Neural Network to extract a set of features. The network produces K vectors, each of which is a D-dimensional representation corresponding to parts of the input image.
3.2 Long Short Term Memory
We briefly introduce the standard Long Short-Term Memory (LSTM), a variant of RNN, which is effective and widely used in language generation model. LSTM incorporates a memory cell and non-linear gating units to effectively overcome the gradient vanishing and explosion problems. Our implementation of LSTM shown in Fig. 2. The formulas for LSTM forward pass are given below:
where, \(\mathbf{{i}}^{t}\), \(\mathbf{{f}}^{t}\), \(\mathbf{{o}}^{t}\), \(\mathbf{{g}}^{t}\), \(\mathbf{{c}}^{t}\) and \(\mathbf{{h}}^{t}\) are input gate, forget gate, output gate, cell input, cell state and hidden state of LSTM respectively. \(\sigma \) is logistic sigmoid activation. \(\phi \) is hyperbolic tangent activation. \(\mathbf{{W}}_{**}\), \(\mathbf{{U}}_{**}\), \(\mathbf{{V}}_{**}\) and \(\mathbf{{b}}_{*}\) are learned weight matrices and biases. The initializes of LSTM are given below:
3.3 Attention Model
The context vector \(\tilde{\mathbf {v}}^{t}\) is a dynamic representation corresponding to parts of input image. Attention-based model learns a vector of weights \({\mathbf{{\alpha }}_{i}}(i=1,2,...,\text {K})\) corresponding to the features extracted at different image locations from \(\mathbf{{v}}_{i}\) and previous hidden state \({\mathbf{{h}}^{t - 1}}\). \({\mathbf{{\alpha }}_{i}}\) is a scalar between 0–1 and \(\sum \nolimits _{i = 1}^K {{\mathbf{{\alpha }}_i} = 1}\).
where, \({\mathbf{{1}}}\) is a vector with all elements set to 1. Additionally, attention-based model predicts a gating scalar \({\mathbf{{\beta }}^t}\) from previous hidden state \(\mathbf{{h}}^{t - 1}\) at each time step t. This gating variable allows the decoder to decide to whether put more emphasis on language model or the context at each time step.
In this work, we use MLP to compute the output word probability conditioned on the image (the context vector), the previously generated word, and the decoder hidden state \({\mathbf{{h}}^t}\). In formula 10, \({\mathbf{{W}}_o} \in {\mathbf{{R}}^{V*n}}\), n is LSTM hidden dimensionality, \({\mathbf{{W}}_h} \in {\mathbf{{R}}^{m*n}}\) and \({\mathbf{{V}}_v} \in {\mathbf{{R}}^{m*D}}\).
3.4 Jointly Measuring Relevance and Coherence
We assume that a low dimensional embedding exists for the representations of image and sentence. To measure the relevance between the visual content and semantics, we compute their distance in the embedding space. Thus, we define the relevance loss as:
where \({\mathbf{{V}}_v} \in {\mathbf{{R}}^{m*D}}\), L is the length of sentence. Inspired by the recent success of probabilistic sequence models leveraged in machine translation, the coherence loss is defined as:
By minimizing the coherence loss, the contextual relationship among the words in the sentence can be guaranteed, making the sentence coherent and smooth. In image caption task, both the relevance and coherence loss are estimated to complete the object function. The training of our model is performed by simultaneously minimizing the relevance loss and coherence loss. Therefore, the last object function is given below:
4 Experiments
In this section, we first describe our experimental method and then quantitatively analyse the experimental results.
4.1 Experimental Preparation
Our experiments are validated on the widely used Flickr8k [5], Flickr30k [24] and MS COCO [9] datasets which have 8092, 31,783 and 123,287 images respectively.
For Flickr8k and Flickr30k datasets, each image is paired with 5 references. For Flickr8k dataset, We use the predefined splits containing 6,000 images for training, 1,000 images for validation and 1,000 images for test. For Flickr30k dataset, we use the publicly available splitsFootnote 1 containing 29,000 images for training, 1,000 images for validation and 1,000 images for test.
For COCO dataset, some images have references in excess of 5, so we only keep 5 references for each image for consistency across our dataset. We use the same data split as in [6, 21] containing 82,782 images for training, 5,000 images for validation and 5,000 images for test. However, a small part of images are not RGB format which are discard for feature extraction expediently. So the last number of images for training, validation and test are 113,079, 4989 and 4982 respectively.
We use only basic tokenization to Microsoft COCO which is same as the tokenization present in Flickr8k and Flickr30k. We don’t convert any sentences to lowercase. And we keep all non-alphanumeric characters except double quotes. In our experiment, we use a fixed vocabulary size of 10000 and others are agreed to be marked as ‘UNK’. For each sentence, we add a terminator ‘\(\mathbf {{<}eos{>}}\)’ to the end of a sentence.
We use the Oxford VGG19 [16] pretrained on ImageNet without finetuning for image feature extraction. Our model’s hyper-parameters are all the same as [21]. Also, the hyper-parameters of models training on three datsets are the same. Our model is not end to end. We pre-extract the feature of images by VGG19 pretrained on ImageNet without finetuning. We only train the parameters of the encoder LSTM and decoder MLP. All learning parameters are initialized randomly and model uses ADAM [7] optimizer with an initial learning rate of \(2 \times {10^{- 4}}\).
4.2 Experiments Analysis
Our model is based on [21] which we comparing with. By this way, we can verify that it can improve the performance of attention-based caption model significantly when considering the relationship of semantic and visual contents.
We report the results using the COCO captioning evaluation tool which reports the following metrics: BLEU [13] and Meteor [1]. Table 1 shows the results measured on Flickr8k, Flickr30k and MS COCO datasets. Compared with based-attention model [21] we can see that our model improves the performance of original attention based model significantly. When considering the relevance of visual and semantic contents, our model improves all metrics scores on Flickr8k, Flickr30k and MS COCO respectively. This means that the semantics (e.g. subjects, verbs or objects) in the sentence generated by our model are more precise. For Flickr8k dataset, our model improves BLEU-4 score from 21.3 to 22.7, METEOR score from 20.3 to 21.5 and increases by an average of 1.36 points for all metrics. BLEU-4 score improves from 19.9 to 23.2 and METEOR score from 18.5 to 20.4 on Flickr30k dataset. For COCO, BLEU-4 score increases from 25.0 to 30.4, METEOR score from 23.0 to 25.5 and average score increases by 4.36 points for all metrics. On the other hand, we can see that the improvement of all score metrics is most obvious on the COCO dataset, followed by Flickr30k dataset. This proves that the richer the data and the wider the data distribution, the better the model works.

Sentences 1–3 are ground-truth references. SAT: [21].
We also reproduce the method of [21], which we called SAT here, and generate descriptions for test-set images of MS COCO dataset (beam search size is fixed as 3). Then we compare the results with ours. Figure 3 shows some examples. We can see that the sentences, generating by our model, are more precise, reasonable and robust than SAT. In the first picture of Fig. 3, subject ‘people’ is right but ‘women’ is more precise and ‘down a street’ is more reasonable than ‘on a beach’. In the third picture, verb ‘grazing’ is more suitable for ‘walking across’. For the fourth picture, SAT generates a sentence with logical error but ours do not.
Through analysis, we also find that SAT and our model always produce the same sentence for similar pictures, both have the same trend but our model is relatively more flexible. We list some examples in Fig. 4. For 4982 test samples, the sentence of ‘A man riding a snowboard down a snow covered slope’ generated by SAT appears 36 times vs 10 times of ours, and ‘A baseball player swinging a bat at a ball’ generated by SAT appears 37 times vs 11 times of ours. From Fig. 4, we can see that the sentences generated by our model, which considers the relevance, are more diverse and precise than SAT.

Examples corresponding to the same sentence generated by SAT: [21].
In formula 13, we use tradeoff parameter \({\lambda }\) for relevance. We fixed the value of beam size as 3. Then we illustrate the performance curves with different trade of parameter values in Fig. 5(a). To make all performance curves fall into a comparable scale, all BLEU-1,2,3,4 and METEOR scores are normalized as:
where \({s'_\lambda }\) and \({s_\lambda }\) denote normalized scores and original scores with a set of \({\lambda }\), respectively. When the value of \({\lambda }\) exceeds 1.5, the corresponding value decreases rapidly. When \({\lambda }=10\), the corresponding normalized score values decrease to 0.0 for all metrics scores. So in order to be easy to observe, We do not show corresponding values greater than 3 in the chart. From Fig. 5(a) we can see that the best performance is achieved when \({\lambda }\) is about 0.8. When \({\lambda }=0.8\), all metrics scores are more concentrated and larger than others relatively. This proves that it’s reasonable to jointly learn the visual-semantic embedding space in the deep RNNs.

(a): The performances of different \({\lambda }\). (b)–(d): The performances of different beam search sizes.
Then we explore the influences on all score metrics when changing the beam search size on the three benchmark datasets. In this experiment, we fix the value tradeoff parameter \({\lambda }\) as 0.8. We illustrate the performance curves with different beam search sizes in Fig. 5(b)–(d). To make all performance curves fall into a comparable scale, all BLEU-1,2,3,4 and METEOR scores are normalized which is same as Eq. 14.
From Fig. 5(b)–(d) we can see that different datasets and models have different best beam search sizes. For Flickr8k dataset, our model obtains the best performance when beam search size is 2. But 4 is best for Flickr30k dataset and 3 is best for COCO dataset. However, our experiment need to compare with [21] who fixed beam search size as 3 for all datasets and models in experiment. In order to be persuasive, we fix beam search size as 3 for all datasets and models.
5 Conclusion
In this paper, we present a new method, which can explore the learning of semantic-visual embedding and attention-based LSTM. In particular, the semantic-embedding space is incorporated with attention-based LSTM learning. We explore the local and global relationship between the semantic and visual contents. Experimental results show that this method can improve the performances of attention-based image caption model significantly on three benchmark datasets measured by the BLEU and METEOR score metrics. We also explore the influences of different hyper-parameters on model. We will continue to explore the relationship between the visual and semantic contents from different perspectives by different methods.
References
Satanjeev, B., Lavie, A.: Meteor: an automatic metric for MT evaluation with improved correlation with human judgments, pp. 228–231 (2005)
Chen, X., Lawrence Zitnick, C.: Mind’s eye: a recurrent visual representation for image caption generation, pp. 2422–2431 (2015)
Donahue, J., Anne Hendricks, L., Guadarrama, S., Rohrbach, M., Venugopalan, S., Darrell, T., Saenko, K.: Long-term recurrent convolutional networks for visual recognition and description. In: CVPR, pp. 2625–2634 (2015)
Fang, H., Gupta, S., Iandola, F., Srivastava, R.K., Deng, L., Dollár, P., Gao, J., He, X., Mitchell, M., Platt, J.C., et al.: From captions to visual concepts and back. In: CVPR, pp. 1473–1482 (2015)
Hodosh, M., Young, P., Hockenmaier, J.: Framing image description as a ranking task: data, models and evaluation metrics. JAIR 47, 853–899 (2013)
Karpathy, A., Fei-Fei, L.: Deep visual-semantic alignments for generating image descriptions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3128–3137 (2015)
Kingma, D., Ba, J.: Adam: a method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
Kiros, R., Salakhutdinov, R., Zemel, R.: Multimodal neural language models. In: ICML, pp. 595–603 (2014)
Lin, T.-Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft COCO: common objects in context. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014. LNCS, vol. 8693, pp. 740–755. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10602-1_48
Lu, J., Xiong, C., Parikh, D., Socher, R.: Knowing when to look: adaptive attention via a visual sentinel for image captioning. arXiv preprint arXiv:1612.01887 (2016)
Mao, J., Xu, W., Yang, Y., Wang, J., Huang, Z., Yuille, A.: Deep captioning with multimodal recurrent neural networks (m-RNN). arXiv preprint arXiv:1412.6632 (2014)
Pan, Y., Mei, T., Yao, T., Li, H., Rui, Y.: Jointly modeling embedding and translation to bridge video and language. In: CVPR, pp. 4594–4602 (2016)
Papineni, K., Roukos, S., Ward, T., Zhu, W.J.: Bleu: a method for automatic evaluation of machine translation. In: ACL, pp. 311–318 (2002)
Ranzato, M.A., Chopra, S., Auli, M., Zaremba, W.: Sequence level training with recurrent neural networks. arXiv preprint arXiv:1511.06732 (2015)
Rennie, S.J., Marcheret, E., Mroueh, Y., Ross, J., Goel, V.: Self-critical sequence training for image captioning. arXiv preprint arXiv:1612.00563 (2016)
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. Computer Science (2014)
Sutton, R.S., Barto, A.G.: Reinforcement Learning: An Introduction, vol. 1. MIT Press, Cambridge (1998)
Tran, K., He, X., Zhang, L., Sun, J., Carapcea, C., Thrasher, C., Buehler, C., Sienkiewicz, C.: Rich image captioning in the wild. In: CVPR, pp. 49–56 (2016)
Vinyals, O., Toshev, A., Bengio, S., Erhan, D.: Show and tell: a neural image caption generator. In: CVPR, pp. 3156–3164 (2015)
Williams, R.J.: Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach. Learn. 8(3–4), 229–256 (1992)
Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A., Salakhudinov, R., Zemel, R., Bengio, Y.: Show, attend and tell: neural image caption generation with visual attention. In: ICML, pp. 2048–2057 (2015)
Yao, T., Pan, Y., Li, Y., Qiu, Z., Mei, T.: Boosting image captioning with attributes. arXiv preprint arXiv:1611.01646 (2016)
You, Q., Jin, H., Wang, Z., Fang, C., Luo, J.: Image captioning with semantic attention. In: CVPR, pp. 4651–4659 (2016)
Young, P., Lai, A., Hodosh, M., Hockenmaier, J.: From image descriptions to visual denotations: new similarity metrics for semantic inference over event descriptions. ACL 2, 67–78 (2014)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Zhang, T., Wang, W., Wang, L., Hu, Q. (2017). Relevance and Coherence Based Image Caption. In: Yang, J., et al. Computer Vision. CCCV 2017. Communications in Computer and Information Science, vol 771. Springer, Singapore. https://doi.org/10.1007/978-981-10-7299-4_21
Download citation
DOI: https://doi.org/10.1007/978-981-10-7299-4_21
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-10-7298-7
Online ISBN: 978-981-10-7299-4
eBook Packages: Computer ScienceComputer Science (R0)