
Abstract
Although vocabulary tree based algorithm has high efficiency for image retrieval, it still faces a dilemma when dealing with large data. In this paper, we show that image indexing is the main bottleneck of vocabulary tree based image retrieval and then propose how to exploit the GPU hardware and CUDA parallel programming model for efficiently solving the image index phase and subsequently accelerating the remaining retrieval stage. Our main contributions include tree structure transformation, image package processing and task parallelism. Our GPU-based image index is up to around thirty times faster than the original method and the whole GPU-based vocabulary tree algorithm is improved by twenty percentage in speed.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Image retrieval is to search for similar images in a large scale database given a query image. Bag of Features (BOF) image representation and its many variants [1, 2, 4,5,6,7, 11, 15, 16] are well known for addressing the image search problem, which quantized local invariant features such as SIFT (Scale Invariant Feature Transform) [3] to visual words. Then, combining with the inverted file retrieval method, visual words can become more discriminative and be accessed faster. Generally speaking, there exists more than hundreds of thousands of visual words for each individual retrieval. In order to speed up the assignment of individual feature descriptors to its corresponding visual words, David Nistér and Henrik Stewénius [2] introduced the vocabulary tree algorithm which leverages the hierarchical structure of tree. Although this method has gained a lot efficiency in image retrieval, it still suffers from the great challenge in large-scale image database.
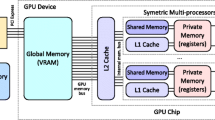
Meanwhile, with the popularity of GPU (Graphics Processing Units) hardware, CUDA parallel programming method has drawn much attentions to accelerate processing massive data, such as SiftGPU [8] and MCBA [9], which make 3D reconstruction in the large much faster. It leverages thousands of threads to execute the same instructor simultaneously. Although CUDA parallel programming method succeeds in regular applications, such as dense linear algebra, it will face a dilemma due to the irregular program of vocabulary tree, which performs unpredictable and data-driven access, and memory restrictions of GPU when compared to the amount of RAM available to CPU.
In this paper, we design and implement a GPU-based vocabulary tree algorithm for efficient large-scale image search. We first analyze the original vocabulary tree algorithm and draw the conclusion that the main bottleneck of vocabulary tree is image index. Then, we show how to transform the original tree structure to linear continuous array to fit the GPU architecture and how to organize the large-scale data to maximize the usage of memory width. Meanwhile, we explore the task parallelism (that is, asynchronism of CPU and GPU) to further boost the speedup performance.
The rest of this paper is organized as follows. We begin in Sect. 2 by analysing the original vocabulary tree algorithm and conclude some matters and challenges to be noted in GPU architecture. In Sect. 3 we describe the explicit implementation of the GPU-based vocabulary tree algorithm including the transformation of tree structure, the organization of massive data and task parallelism for SIFT descriptor search and histogram compression. In Sect. 4 we report the performance of our algorithm, and conclude with a discussion and directions for future work in Sect. 5.
2 Theoretical Background of Vocabulary Tree
Given a query image, image retrieval aims to search for similar images with common objects or scenes from a database. Denote the query images as \(\mathcal {Q_{\varvec{i}}},i=1,\ldots ,m\) and the database images as \(\mathcal {D_{\varvec{i}}},i=1,\ldots ,n\). SIFT feature descriptors are extracted from every query image and database image. The content of each image is represented by the Bag of Features (BOF) model, which draws an image as a point in a high dimensional feature space. However, directly searching for nearest neighbors in such a space is time consuming. In order to have a fast and high accuracy performance, vocabulary tree is introduced [2]. Different from the traditional visual words of BOF, which are learned by \(\varvec{k}\)-means algorithm, the visual words of vocabulary tree are built by hierarchical \(\varvec{k}\)-means clustering. In the vocabulary tree algorithm, \(\varvec{k}\) is no longer on behalf of the final number of visual words, it defines the branch factor (number of children of each node) of the tree. Before arriving at the pre-defined level \(L \), the \(\varvec{k}\)-means clustering is recursively applied to each group of descriptors in the last layer, which splits each group of descriptors into finer \(\varvec{k}\) new parts. Eventually the internal nodes represent the centroids of each clustering, while the all leaf nodes are the final visual words.

Example of vocabulary tree and query SIFT feature descriptor searching. Internal nodes are centroids, while leaf nodes are visual words.
In order to assign a visual word to a feature descriptor on the query image, the algorithm will find a path from the root to a leaf node by comparing with the \(\varvec{k}\) candidate cluster centers at each layer. This results in at most \(\varvec{k}{} L \) comparisons for each feature descriptor, which is illustrated in Fig. 1. Just as David Nistér et al. pointed out in the literature [2], compared with the visual words defined by the non-hierarchical manner, the computational cost of the establishment of visual words in vocabulary tree is logarithm in the number of leaf nodes and the total number of feature descriptors that must be represented is \(\sum _{i=1}^{L}\varvec{k}^{i}=\frac{\varvec{k}^{L +1}-\varvec{k}}{\varvec{k}-1}\) \(\approx \varvec{k}^{L }\).
Moreover, to characterize the relevance between a database image and the query image better, vocabulary tree borrows ideas from the inverted file index, which is called Term Frequency Inverse Document Frequency (TF-IDF). Term Frequency describes the number of feature descriptors assigned to a specific visual word, while Inverse Document Frequency reflects the significance of a visual word. Assume that for the database images, the Term Frequency of a visual word \(\varvec{i}\) is \(N _{i}\), and the number of database images is \(N \), then the modified weight of the visual word \(\varvec{i}\) is
which makes the visual word become more discriminative. Then both the query image vector and the database image vector can be defined as
where \(\varvec{n}_{i}\) and \(\varvec{m}_{i}\) are the number of feature descriptors assigned to the visual word \(\varvec{i}\) for the query image and the database image, respectively. In order to remove the influence of the vector bias for a better similarity measure, normalization is further utilized, which means final representative vectors of both the query image and database image are modified as
Subsequently, the similarity score between the query image and the database image is given by
After obtaining similarity scores between the query image and the database images, sort algorithm is applied to get the final score list. And people can truncate the list to get the top \(\varvec{j}\) database images according to their need.
In sum, the vocabulary tree algorithm can be divided into 3 different phases, including the visual words learning, database images index and query images search. The first phase is off-line and the remaining two are online. As there exists more and more well-learned visual words, the first phase computational overhead can be ignored. However, due to the increasing of database images, the main computational overhead falls in the second image index phase, which can be verified by Tables 1, 2 and Fig. 4(a). So we need to fully exploit the modern GPU hardware to speedup the image index, which will be explicitly described in the following section.
3 GPU-Based Vocabulary Tree Algorithm
It is well-known that GPU can perform the same operation across thousands of individual data elements owing to its highly parallel architecture. In contrast to the CPU architecture where each thread execute its own set of instructions, GPU adopts the single instruction multiple threads (SIMT) model, which means that a large collection of threads can execute the same instruction simultaneously. Using this model, GPU not only achieves the massively parallel computation, but also high data throughout [10]. Based on this, we start the algorithm specially designed for vocabulary tree.
As analysed in Sect. 2, there are tremendous feature descriptors in all the database images (considering that a image of high resolution contains at least 10,000 feature descriptors), which makes the image index lower the search efficiency. An intuition is that every feature descriptor can be allocated to its respective thread to search the visual word it belongs to. Following this idea, we will further discuss the subsequent problems and solutions, which constitute the subject of our GPU-based vocabulary tree algorithm.

Structure transformation from original irregular tree to instructive array. Except for its original tree node attribute, every structured array includes the address offset of its first child and the number of its children.
What we first need to consider is that how to transplant the tree structure of visual words into the GPU platform. Because the tree structure is organized by the form of non-continuous pointers, it is impossible to transfer all the visual words by just transferring the root node. Thus the tree structure of visual words should be reorganized in the form of array. In order to maintain the search efficiency of original tree structure, all nodes should also record the address offset of its first child and the number of its children except for the original SIFT descriptors and node ID. The first information is used for SIFT descriptors to search their next corresponding node until they reach the bottom level while the function of the second information is to judge whether the search should be terminated or not. The above transformation can be executed by breadth first search combined with the stack operation. Once the instructive array of visual words is obtained, it can be transplanted into the GPU platform easily. See Fig. 2 for example.
Next, we will arrange the SIFT descriptors more carefully. Because the computationally intensive sections of the vocabulary tree algorithm are the image index, we need to assign the visual word attribute for each SIFT descriptor in parallel. We may first want to transfer the SIFT descriptors of an image once every time to GPU platform to execute the above mission. However, it has been shown that this scheme does not fully utilize the parallelism ability of GPU hardware. In order to further dig the GPU hardware parallelism ability, we readjust the structure of SIFT descriptor. In addition to reserve the original attribute of SIFT (scale, orientation, position and descriptor), we also mark up every SIFT descriptor with the image ID attribute so that we can organize them in a larger scale, which means that we pack several images together every time and transfer all their descriptors to the GPU platform.
When we assign the visual word attribute for every SIFT descriptor, we inevitably will face the dilemma that there exists the assignment conflicts when two or more SIFT descriptors of one image contribute to the frequency of the same visual word simultaneously. In order to overcome this contradiction, we employ the Atomic operation, which protects the current operation and make the other operation to the same variable to wait. Another subsequent problem is that the visual word histogram produced in the GPU is very sparse because we break the original tree structure for the convenience of transmission. For the efficiency of subsequent operation and the reduction of memory footprint, we need to compress the sparse histogram. Instead of handling this task serially, we exploit the hybrid execution of using both CPU and GPU resources. See Fig. 3 for example. In the sequential timeline, when the \(\varvec{i}\)th image patch is indexed, then the \(\varvec{i}\)th sparse histogram is compressed sequentially. While in the asynchronous timeline, when the \(\varvec{i}\)th image patch is indexed in GPU, the (\(\varvec{i+1}\))th sparse histograms is simultaneously compressed in CPU.

The combination of data parallelism and task parallelism. The picture above shows the sequential timeline, while the picture below shows the asynchronous timeline.
Furthermore, once we finish the database image query index, query image scoring can also be executed in parallel. When a query instructor is arriving, it generally compares its own histogram to all the database image histograms sequentially. It limits the capability of GPU. Thus, we make the database images simultaneously compute their similarity scores to the query image, which can be massively done in GPU.
4 Experiments and Discussions
In this section we present experimental results on the application of our GPU-based vocabulary tree algorithm to some large-scale data sets. We test our method on datasets of Noah Snavely et al. [12] including 1DSfM_Roman_Forum and 1DSfM_Vienna_Cathedral. The first dataset contains 2360 images while the second contains 6280 images. In order to compare our GPU-based vocabulary tree algorithm performance with CPU-based vocabulary tree algorithm, we will re-implement the Noah Snavley’s CPU-based vocabulary tree algorithm [13], which is used to retrieval the most relevant image pairs for every image to produce compact subsets for large-scale 3D reconstruction [14, 17, 18].
Since there are many generic well-trained visual words for vocabulary tree, we skips the vocabulary tree training phase and test the remaining two phase. One thing that should be noted is that for most image retrieval applications, it is general to first delineate the Maximally Stale Extremal Regions (MSERs) [19] or Hessian-Affine interest points [20], which is proved to be benefit to the retrieval accuracy. However, here we only focus on the retrieval efficiency so that we extract all the SIFT features from all the database images for general purpose. Although we do not execute the abstraction of MSERs or Hessian-Affine interest points, this requires us to deal with more SIFT descriptor index missions, which can further demonstrate our GPU-based algorithm efficiency. Users can adaptively choose the abstraction of MSERs or Hessian-Affine interest points in practice according to their own requirements.
All the experiments are conducted on a machine with two Intel Xeon CPU E5-2630 v3 2.40 GHz, one NVIDIA GeForce GTX TitanX graphics card with 12 GB global memory and 64-bit Linux operating system. The CPU-based vocabulary tree algorithm is implemented using C++, and our GPU code is implemented with CUDA.

(a) The runtime ratio for the CPU-based vocabulary tree. (b) The runtime ratio for GPU-based vocabulary tree. (c) The runtime comparison between GPU-based and CPU-based vocabulary tree. The runtime of GPU-based image index is up to around thirty times faster than the CPU-based method and the whole GPU-based vocabulary tree algorithm is improved by twenty percentage.
Note that here we ignore the SIFT reading time and the score sorting time because they are implemented in the same way for the compared methods. In all our experiments, we enforce the vocabulary tree with branch factor \(\varvec{k}\) = 10 and level \(L \) = 6 to test both the CPU-based and GPU-based algorithms. Figure 4(a) shows that the SIFT descriptor search occupies up to 99% of the runtime and illustrates that image index becomes the bottleneck in the overall runtime. In order to highlight the speedup performance of every stage, we explicitly record the detailed time in seconds for every stage in Tables 1 and 2. We can see that our GPU-based image index is around thirty times faster than CPU-based image index and the whole vocabulary tree algorithm is improved by twenty percentage, whilst the other stages (include weighting, normalization and scoring) also have a certain speedup. We also note that the data copying item that records the whole data transmission time is not so time-consuming owing to the package processing for large-scale images. Last but not least, from the 2nd row of both tables, search and compression stages are executed asynchronously, which makes the compression time hidden under the search time. Essentially, search stage and compact representation are tightly coupled in CPU-based vocabulary tree algorithm owing to the tree structure. This makes the compact representation time almost indiscriminate. Because we adopt the task parallelism execution, we eliminate the data redundancy problem from the another point of view. Figure 4(a)(b) shows the GPU-based algorithm runtime ratio and runtime comparison between CPU-based and GPU-based algorithm in which we can see SIFT descriptor search runtime ratio decreases from 99% to 63% of the overall runtime obviously. As illustrated in Fig. 4(c), the runtime is reduced greatly for both the image index phase and the overall algorithm.

The runtime analysis for the CPU-based and GPU-based vocabulary tree.

The accuracy of GPU-based vocabulary tree with different depth and different image scale.
We also conduct experiments to understand how the tree depth influences the speedup performance and the accuracy robustness for both algorithms. We train the vocabulary tree with different depth progressively and test the runtime performance between CPU-based and GPU-based algorithm on the 1DSfM_Roman_Forum. As shown in Fig. 5, when depth increases, the CPU-based image index runtime is increased exponentially while the GPU-based image index runtime varies linearly with a small increment. Besides, we can see that the speedup ratio is above 15. The reason why the shallow vocabulary tree speedup performance is lower than the deep is that shallow vocabulary tree has less leaf nodes and search collision occurs more frequently. We evaluate the accuracy by extracting the SIFT descriptors after detecting the Hessian-Affine regions [22] and executing CPU-based and GPU-based vocabulary tree in the dataset UKbench [21]. The UKbench dataset contains 10200 images, consisting of 2550 groups of 4 images each. All the images are 640\(\,\times \,\)480. We follow the performance measure of [21] to count how many of the 4 images which are top-4 when using a query image from the same group. Figure 6 shows the accuracy trend with different dataset number and different depth of vocabulary tree. The accuracy of GPU-based and CPU-based algorithm is no different so that we just show the GPU-based algorithm’s accuracy. We note that since a different vocabulary is used, our results are a bit different from [21]. When the size of image database increases, there is a small drop in the accuracy performance. This is because SIFT descriptor collision is more likely to happen when more images are used. Just as demonstrated in [2], our results also show that the most importance for the retrieval quality is to have a large vocabulary (large number of leaf nodes). Thus, the speedup performance in the vocabulary tree with branch factor \(\varvec{k}\) = 10 and level \(L \) = 6 is particularly import, where our GPU-based image algorithm performs well.
5 Conclusion
In this paper we present the GPU execution scheme to the problem of vocabulary tree based large-scale image retrieval. The GPU-based image indexing delivers a 30x boost in speed over the CPU-based algorithm and the whole algorithm achieves 20x faster. This is done by carefully transforming the tree structure to the array form and SIFT descriptors package processing. We also explore the task parallelism for data redundancy. Although the problem addressed in this paper is vocabulary tree image retrieval, we believe that the above speedup design here can applied to other large-scale tree-based irregular programs. In the future, we would like to further combine the GPU-based feature extraction and GPU-based sort algorithm to design an end-to-end platform to further accelerate the large scale image retrieval. We also hope to improve the retrieval accuracy by leveraging the asynchronism of GPU and CPU.
References
Sivic, J., Zisserman, A.: Video Google: a text retrieval approach to object matching in videos. In: CVPR (2003)
Nistér, D., Stewénius, H.: Scalable recognition with a vocabulary tree. In: CVPR (2006)
Lowe, D.G.: Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vision 60, 91–110 (2004)
Lazebnik, S., Schmid, C., Ponce, J.: Beyond bags of features: spatial pyramid matching for recognizing natural scene categories. In: CVPR (2006)
Philbin, J., Chum, O., Isard, M., Sivic, J., Zisserman, A.: Object retrieval with large vocabularies and fast spatial matching. In: CVPR (2007)
Jegou, H., Douze, M., Schmid, C.: Hamming embedding and weak geometric consistency for large scale image search. In: ECCV (2008)
Jgou, H., Douze, M., Schmid, C.: Improving bag-of-features for large scale image search. Int. J. Comput. Vision 87, 316–336 (2010)
Wu, C., SiftGPU: A GPU implementation of david lowe’s scale invariant feature transform (SIFT). http://cs.unc.edu/~ccwu/siftgpu/
Wu, C., Agarwal, S., Curless, B., Seitz, S.M.: Multicore bundle adjustment. In: CVPR (2011)
Farber, R.: CUDA Application Design and Development. Morgan Kaufmann, San Francisco (2011)
Arandjelović, R., Zisserman, A.: DisLocation: scalable descriptor distinctiveness for location recognition. In: ACCV (2014)
Wilson, K., Snavely, N.: Robust global translations with 1DSfM. In: ECCV (2014)
Snavely, N.: A CPU implementation of David Nistér and Henrik Stewénius’s vocabulary tree algorithm. https://github.com/snavely/VocabTree2
Agarwal, S., Snavely, N., Simon, I., Seitz, S., Szeliski, R.: Building Rome in a day. In: ICCV (2009)
Sattler, T., Havlena, M., Schindler, K., Pollefeys, M.: Large-scale location recognition and the geometric burstiness problem. In: CVPR (2016)
Koniusz, P., Yan, F., Gosselin, P.H., Mikolajczyk, K.: Higher-order occurrence pooling for bags-of-words: visual concept detection. IEEE Trans. Pattern Anal. Mach. Intell. 39, 313–326 (2017)
Schönberger, J.L., Frahm, J.-M.: Structure-from-motion revisited. In: CVPR (2016)
Shen, T., Zhu, S., Fang, T., Zhang, R., Quan, L.: Graph-based consistent matching for structure-from-motion. In: ECCV (2016)
Matas, J., Chum, O., Urban, M., Pajdla, T.: Robust wide baseline stereo from maximally stable extremal regions. In: BMVC (2002)
Mikolajczyk, K., Schmid, C.: Scale & affine invariant interest point detectors. Int. J. Comput. Vision 60, 63–86 (2004)
Stewénius, H., Nistér, D.: UKbench dataset. http://vis.uky.edu/~stewe/ukbench/
Mikolajczyk, K.: Binaries for affine covariant region descriptors. http://www.robots.ox.ac.uk/~vgg/research/affine/
Acknowledgments
The authors would like to acknowledge Henrik Stewénius, David Nistér, Mikolajczyk, K. and Noah Snavely et al. for making their related datasets and source codes publicly available to us. This work is supported by the National Natural Science Foundation of China (Grant 61772213 and 61371140) and the Special Fund CZY17011 for Basic Scientific Research of Central Colleges, South-Central University for Nationalities, also in part by Grants 2015CFA062, 2015BAA133 and 2017010201010121.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Xu, Q., Sun, K., Tao, W., Liu, L. (2017). Massively Parallel Image Index for Vocabulary Tree Based Image Retrieval. In: Yang, J., et al. Computer Vision. CCCV 2017. Communications in Computer and Information Science, vol 772. Springer, Singapore. https://doi.org/10.1007/978-981-10-7302-1_9
Download citation
DOI: https://doi.org/10.1007/978-981-10-7302-1_9
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-10-7301-4
Online ISBN: 978-981-10-7302-1
eBook Packages: Computer ScienceComputer Science (R0)