
Abstract
Zero-shot learning (ZSL) improves the scalability of conventional image classification systems by allowing some testing categories having no training data. One key component is to learn a shared embedding space where both side information of object categories and visual representation of object images can be projected to for nearest neighbor search. Although great progress has been made, existing approaches mainly focus on shallow models, which cannot learn a strong generalized embedding space. To this end, this paper proposes a novel deep embedding model for ZSL, which formulates the embedding space with Deep Canonical Correlation Analysis (DCCA). Specifically, the side information and the visual representation are transformed via two independent deep neural networks, and then they are highly linearly correlated in the final output layer. Extensive experiments on two publicly popular datasets demonstrated the effectiveness and superiority the proposed approach.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Image classification technique has made great progress owing to the prosperous progress of Convolutional Neural Networks (CNN) and large scale annotated datasets. However, one obstacle it must face is that there must be enough annotation data for training. It is impractical to provide the labels for all categories since there are so many categories in the real world. Moreover, labeling all the classes for training is expensive and time-consuming.
In contrast, we human beings have the ability to recognize new categories without having to look at actual visual samples. Imaging that a child has never seen a zebra, however, he/she has been told that the zebra looks like a horse but with black and white stripes. When this child sees a zebra in the first time, he/she may recognize the zebra with his/her own inferential capability. To imitate this ability, Zero-Shot Learning (ZSL) technique is proposed and received increasingly attention recently [1,2,3,4,5].
ZSL predicts new unseen categories by transferring the knowledge obtained from seen categories with labeled data and side information such as attributes [6] and word vectors [7]. Specifically, attributes define a few properties of an object, such as the color, the shape, and the presence or absence of a certain body part. Word vectors represent category names as vectors with a distributed language representation, which is constructed by a linguistic base, such as Wikipedia. Both attributes and word vectors are shared across both seen and unseen categories. In this way, both categories are associated with semantic vectors in the category embedding space spanned by the side information. In another words, the side information acts as a bridge to make the knowledge transferred from the seen categories to the unseen categories.

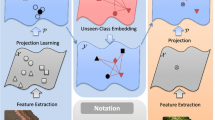
The pipeline of the proposed DCCA-ZSL approach
Since the visual features and the side information are different modalities, a shared embedding space is required to compute their interaction. Actually, the construction of the embedding space is one of the key components in ZSL. Many attempts have been made to build an effective embedding model, such as CCA [8], LatEm [2], MCME [3], ReCMR [4] and SJE [9]. However, these approaches are based on shallow models, which cannot learn the strong generalized embedding models. To this end, this paper proposes a novel deep embedding model based on Deep Canonical Correlation Analysis (DCCA), and the proposed approach is called DCCA-ZSL. Figure 1 shows its pipeline.
This paper is structured as follows. Section 2 introduces the related work of ZSL. Section 3 presents the detail of the proposed DCCA-ZSL approach. Experimental results and analyses are given in Sects. 4 and 5 concludes this paper.
2 Related Work
From the perspective of embedding space, most existing ZSL approaches can be grouped into linear-based, bilinear-based, and nonlinear-based methods. Specifically, the linear-based methods generally embed the visual space to the side information space, or vice versa. For example, Linear Regression (LR) is one of the representative methods [10]. It is a straightforward cross-modality method using L2-regularized least-square loss to build an objective function to map knowledge from the one space to the other space. The authors in [10] also demonstrated that the embedding from the visual space to side information space is more effective than the inverse embedding.
Bilinear-based methods are most commonly used in ZSL. In general, a bilinear embedding is a function combining elements of two vector spaces to yield an element of a third vector space, and is linear in each of its arguments. One representative method in this group is Canonical Correlation Analysis (CCA). Lazaridou et al. [8] employs CCA to maximize the correlation between the visual feature and the semantic feature. Motivated by CCA, [3] presents a manifold regularized cross-modal embedding approach for ZSL by formulating the manifold constraint for intrinsic structure of the visual features as well as aligning pairwise consistency. ESZSL method in [1] constructs a general framework to model the relationships between visual features, class attributes and class labels with a bilinear model, and the closed-form solution makes it efficient. SJE method in [9] relates the input embedding and output embedding through a compatibility function, and implements ZSL by finding the label corresponding to the highest joint compatibility score. Recently, Yu et al. [4] developed a bilinear embedding model by employing the hinge ranking loss to exploit the structures among different modalities and devise efficient regularizers to constrain the variation of the samples in the identical modality. Xian et al. [2] presented a novel discriminative bilinear embedding model by applying multiple linear compatibility units and allowing each image to choose one of them. The model is trained with a ranking based objective function that penalizes incorrect rankings of the true class for a given image.
Nonlinear-based methods are receiving more attentions in recent years. DAP [11] and IAP [11] are the earlier attempt toward this line. They build a network to formulate the embedding relations. Specifically, DAP utilizes the class attributes as the middle layer between the input instances and the output category labels, while IAP takes the seen categories as the middle layer. Socher et al. [5] used a two-layer network to embed the visual space into a side information space. It is a simple embedding model and is not a shared space. Recently, Yang and Hospedales [12] proposed a neural network based ZSL method to build a shared space. However, the objective function is different from ours, and the network is also a two-layer one.
3 Proposed DCCA-ZSL Method
In this section, we elaborate our proposed DCCA-ZSL method. We first introduce the notations, then depict the details of DCCA-ZSL and finally analyze the optimization process briefly.
3.1 Notations
We denote the data matrix of visual feature as X = \([x_1,\cdots , x_N]\in \mathbb {R}^{D_x \times N}\)and that of side information feature as Y = \([y_1,\cdots , y_N]\in \mathbb {R}^{D_y \times N}\),where N is the sample size, \(D_x\) and \(D_y\) are the dimensionalities. The f and g are used to denote the nonlinear mapping implemented by deep networks. A deep network f of depth m implements a nested mapping with the form \(f\!(x)\! =\! f_m\!(\!(\!\cdots f_1\!(x;W_1\!,b_1\!)\! \cdots \!);\! W_m\!,b_m)\!\), where \(W_i\) are the weight parameters of layer \(i(i = 1,\cdots ,m)\) and \(f_i\) is the mapping of layer i that can be represented as \(f_i(x) = s(W^T_ix + b_i )\). And s is the activation function. The typical choices of which are sigmoid, tanh, ReLU, etc. We use \(\theta _f\) to denote the vector of all parameters \(W_m\) and \(b_m\) for visual feature X, and similarly for \(\theta _g\) to denote the parameters of semantic feature Y. The dimensionality of the embedding space, which is equal to the number of output units in the two deep networks, is denoted as d.
3.2 Canonical Correlation Analysis
Canonical Correlation Analysis (CCA) is a kind of classical statistical method. The aim of CCA is to find pairs of linear projections, \(w_x\in \mathbb {R}^{D^x}\) and \(w_y\in \mathbb {R}^{D^y}\), that are maximally correlated for the input random vectors X and Y. At the same time, the different dimensions are constrained to be uncorrelated. And if the noise in either view is uncorrelated with the other view, the learned representations should not contain the noise in the uncorrelated dimensions. The objective function can be formularized as follows:
where \(C_{xx}=XX^T\in R^{D^x\times D^x}\), \(C_{yy}=YY^T\in R^{D^y\times D^y}\) are the within-set covariance matrices and \(C_{xy}=XY^T\in R^{D^x\times D^y}\) is the between-sets covariance matrix and \(C_{xy}=C_{yx}^T\).
3.3 The DCCA-ZSL Model
The target of DCCA is to make the output functions f(X) and g(Y) are maximally related in the embedding space (see Fig. 1). Therefore, the objective function can be represented as
Rewrite the function in the form of matrix operations and then we have:
where P and Q are the CCA directions that project the transformed features, \(r_x\) and \(r_y\) are the regularization parameters, \(P^T f(\cdot )\) and \(Q^T g(\cdot )\) are the final learned mapping for the two modalities.
Similarity metric is important in kNN search in the testing phase [16]. In our work, we select the cosine distance is used as the similarity metric to seek the nearest side information feature for each visual sample according to:
And then the corresponding category of the side information feature is chosen as the predicted result.
In addition, we make a brief introduction to the solution and optimization of DCCA-ZSL method. Let \(H_1\) and \(H_2\) be the representation matrices produced by the deep models on the two different features. \(\overline{H_1}\) and \(\overline{H_2}\) are the corresponding centered matrices. And \(\varSigma _{12}\) is the between-sets covariance matrix. \(\varSigma _{11}\) and \(\varSigma _{22}\) are within-set covariance matrices.
where n is the size of training samples. Then the total correlation of \(H_1\) and \(H_2\) can be calculated by the sum of the top k singular values of matrix T\(\,=\,\varSigma _{11}^{-1/2}\varSigma _{12}\varSigma _{22}^{1/2}\). And if k = d, the correlation is exactly the matrix trace norm of T.
Stochastic Gradient Descent (SGD) [13] algorithm is used to optimize the model. We first randomly pick a minibatch of p training pairs and feed them forward to compute the transformed matrices \(H_1\), \(H_2\) and the correlation matrix T. Then the gradient of T with respect to \(H_1\) and \(H_2\) is computed. Finally, we use back propagation algorithm to adjust the network parameters according to the gradient descent direction until the model converges.
4 Experimental Results and Analysis
4.1 Datasets and Settings
Datasets. To evaluate the effectiveness of the proposed DCCA-ZSL approach, extensive experiments are conducted on two benchmark datasets, AwA [11] and CUB [14]. Specifically, Animal with Attribute (AwA) [11] consists of 30,475 animal images, which belong to 50 categories. Each category is annotated with 85 attributes. Caltech-UCSD Bird2011 (CUB) [14] includes 11,788 images from 200 bird subspecies. And each category is annotated with 312 attributes. Moreover, CUB is a fine-grained dataset which is more challenging for image classification. For AwA and CUB datasets, we use the standard 40/10 and 150/50 split settings, respectively.
Features. VGG-verydeep-19 [15] (denoted as VGGNet for short) is used as the visual feature extraction model, and the 4096-dimensional feature of the second fully connected layer of this model is selected as the visual features of input images. Attributes and word vectors are used as side information, respectively. Particularly, we choose the Word2Vec model trained on the Wikipedia corpus as text feature extraction model, from which 1000-dimentional and 400-dimentional word vectors are used in AwA and CUB datasets, respectively.
Evaluation Metric. The average per-class top-1 accuracy [9] on the test sets is reported over 10 trials.
4.2 Results on AwA and CUB Datasets
CCA is chosen as the baseline embedding model, whose corresponding ZSL method is called CCA-ZSL. Besides, four state-of-the-art methods are selected for comparison, that is SJE [9], LatEm [10], DAP [11], and ESZSL [1]. Among these, CCA-ZSL and ESZSL are implemented by ourselves, while the results of SJE, LatEm and DAP are from the orignal papers or website. The results are summarized in Table 1.
From Table 1, we can observe that:
-
(1)
The proposed DCCA-ZSL method is competitive with the state-of-the-art methods. It beats all the copetitors in AwA dataset in different side information spaces and gains best performance in CUB when using word vectors. Compared with the CCA-ZSL, DCCA-ZSL achieves an improvement of 6.2\(\%\) and 4.7\(\%\) in AwA and CUB with word vectors, respectively. As for attribute feature, it has a 3.1\(\%\) and 1.1\(\%\) improvements, respectively.
-
(2)
The performance improvement of DCCA-ZSL with word vectors is more obvious than that with attributes. This is due to the fact that word vectors are extracted from corpus by unsupervised learning. Therefore, the learned features contain more noise than the human labeled attributes. Using deep network can further remove redundant information and achieve feature fusion, thereby improving classification performance.
-
(3)
The classification accuracy is much higher for those with attributes than those with word vectors. This is because that attributes are annotated by experts, which can better reflect class correlation than word vectors.
-
(4)
We also notice that the performance in AwA dataset is much higher than those in CUB dataset. The reason is that CUB is a fine-grained dataset, which is more challenging for image classification.

The confusion matrices of DCCA-ZSL (a) and CCA-ZSL (b).
Additionally, Fig. 2 provide the confusion matrices of DCCA-ZSL and CCA-ZSL, since they can distinctly and intuitively shown the classification performance. Each column of the matrix represents the instances in a predicted class while each row represents the instances in an actual class. All correctly predicted images are located in the reverse diagonal of the matrix. And the darker the color, the more the numbers of correctly classified images. From Fig. 2, we can observe that the overall performance of DCCA-ZSL is better than that of CCA-ZSL. The darker colors in our model are more concentrated in the reverse diagonal than in CCA-ZSL. And the classification results of four categories, i.e., chimpanzee, leopard, Persian cat, and humpback whale, are with fairly high accuracy.
4.3 Parameter Sensitivity
This subsection analyzes the following four types of parameters: common space dimensionality, number of network layers, batchsize and hyper-parameters.
Without loss of generality, we take the experiments in CUB dataset with word vectors as examples. Fix other parameters, we first evaluate the impact of the common space dimensionality (denoted as d), and the result is shown in Fig. 3.
At the beginning, the accuracy increases with d until reaching a peak. This is because that after the mapping to the common space, the redundant information is removed and the effective feature information is preserved. Thus the classification accurate will rise. Then the increasing of d will take a risk of introducing noise, resulting in decreased classification performance. This paper finally selects d = 40 for both datasets.

Impact of common space dimensionality on CUB dataset with word vectors.
Then, we evaluate the impact of number of network layers. In the experiments, we notice that increasing the layers of the visual feature mapping network (denoted as f) and keep the word vectors mapping network (denoted as g) unchanged, the classification performance does not improve significantly or even decline. This may be due to the fact that visual feature has been sufficiently extracted by CNN so that the performance improvement is not obvious with more layers. Thus, we set the layers of the visual transformation network to be 2. Under this setting, we observe the impact of word vector network depth, as shown in Fig. 3. It can be seen that the classification performance improves with the raise of the layers. Meanwhile, the convergence rate of the model slows down and the training time becomes longer. Making a compromise among these indexes, we choose 5 layers for word vector network.

Impact of the word vector network depth on CUB dataset.
Finally, we evaluate the impact of batchsize and hyper-parameters. The proposed DCCA-ZSL model is optimized by Stochastic Gradient Descent (SGD) algorithm. It randomly picks a minibatch of n training pairs, where n represents the batchsize. With the increase of batchsize, the model converges much faster and the learned gradient descent direction is more accurate. Besides, larger batchsize reduces the times of iterations and the network shock. However, oversized batchsize may make the algorithm get into local minimum values. Considering all of these factors, the batchsize in this paper is set to 200 and 150 for AwA and CUB, respectively.
It is also found that the two hyper-parameters rcov1 and rcov2 for regulation have great effects on the results. The parameters are selected from 0.0001, 0.001, 0.01, 0.1, 1, 10, 100 according to the corresponding experiments.
5 Conclusion and Future Work
In this paper, we propose an effective deep model for ZSL with the idea of DCCA. It embeds the visual and side information representations into a shared space with two independently deep neural network, and takes the CCA as the objective function. Extensive experiments on two popular datasets have demonstrated the superiority and promise of DCCA-ZSL. In the future work, we will explore other objective functions and side information in a deep model to address ZSL task.
References
Romeraparedes, B., Torr, P.H.S.: An embarrassingly simple approach to zero-shot learning. In: 32th JMLR International Conference on Machine Learning, pp. 2152–2161 (2015)
Xian, Y., Akata, Z., Sharma, G., et al.: Latent embeddings for zero-shot classification. In: 29th IEEE Conference on Computer Vision and Pattern Recognition, pp. 69–77 (2016)
Ji, Z., Yu, Y., Pang, Y., Guo, J., Zhang, Z.: Manifold regularized cross-modal embedding for zero-shot learning. Inf. Sci. 378, 48–58 (2017)
Yu, Y., Ji, Z., Pang, Y.: Zero-shot learning with regularized cross-modality ranking. Neurocomputing 259, 14–20 (2017)
Socher, R., Ganjoo, M., Sridhar, H., et al.: Zero-shot learning through cross-modal transfer. In: Advances in Neural Information Processing Systems, pp. 935–943 (2013)
Farhadi, A., Endres, I., Hoiem, D., et al.: Describing objects by their attributes. In: the 19th IEEE Conference on Computer Vision and Pattern Recognition, pp. 1778–1785 (2009)
Mikolov, T., Sutskever, I., Chen, K., et al.: Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 26, 3111–3119 (2013)
Lazaridou, A., Bruni, E., Baroni, M.: Is this a wampimuk? Cross-modal mapping between distributional semantics and the visual world. In: Proceedings of the Association for Computational Linguistics, pp. 1403–1414 (2014)
Akata, Z., Reed, S., Walter, D., et al.: Evaluation of output embeddings for fine-grained image classification. In: 27th IEEE Conference on Computer Vision and Pattern Recognition, pp. 2927–2936 (2014)
Shigeto, Y., Suzuki, I., Hara, K., Shimbo, M., Matsumoto, Y.: Ridge regression, hubness, and zero-shot learning. In: Appice, A., Rodrigues, P.P., Santos Costa, V., Soares, C., Gama, J., Jorge, A. (eds.) ECML PKDD 2015. LNCS (LNAI), vol. 9284, pp. 135–151. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-23528-8_9
Lampert, C.H., Nickisch, H., Harmeling, S.: Learning to detect unseen object classes by between-class attribute transfer. In: 19th IEEE Conference on Computer Vision and Pattern Recognition, pp. 951–958 (2009)
Yang, Y., Hospedales, T.M.: A unified perspective on multi-domain and multi-task learning. In: International Conference on Learning Representations, pp. 1–9 (2015)
Wang, W., Arora, R., Livescu K., et al.: On deep multi-view representation learning objectives and optimization. arXiv preprint arXiv:1602.01024 (2016)
Wah, C., Branson, S., Welinder, P., Perona, P., Belongie, S.: The Caltech UCSD Birds-200-2011 Dataset, Technical report (2011)
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. In: International Conference on Learning Representations (2014)
Guo, Y., Ding, G., Han, J., et al.: Robust iterative quantization for efficient lp-norm similarity search. In: International Joint Conference on Artificial Intelligence, pp. 3382–3388. AAAI Press (2016)
Acknowledgments
This work was supported by the National Natural Science Foun-dation of China under Grant 61472273, Grant 61632018 and Grant 61771329.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Ji, Z., Yu, X., Pang, Y. (2017). Zero-Shot Learning with Deep Canonical Correlation Analysis. In: Yang, J., et al. Computer Vision. CCCV 2017. Communications in Computer and Information Science, vol 773. Springer, Singapore. https://doi.org/10.1007/978-981-10-7305-2_19
Download citation
DOI: https://doi.org/10.1007/978-981-10-7305-2_19
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-10-7304-5
Online ISBN: 978-981-10-7305-2
eBook Packages: Computer ScienceComputer Science (R0)