
Abstract
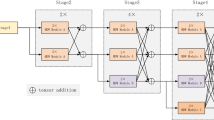
As multi-scale features are necessary for human pose estimation tasks, high-resolution networks are widely applied. To improve efficiency, lightweight modules are proposed to replace costly point-wise convolutions in high-resolution networks, including channel weighting and spatial weighting methods. However, they fail to maintain the consistency of weights and capture global spatial information. To address these problems, we present a Grouped lightweight High-Resolution Network (Greit-HRNet), in which we propose a Greit block including a group method Grouped Channel Weighting (GCW) and a spatial weighting method Global Spatial Weighting (GSW). GCW modules group conditional channel weighting to make weights stable and maintain the high-resolution features with the deepening of the network, while GSW modules effectively extract global spatial information and exchange information across channels. In addition, we apply the Large Kernel Attention (LKA) method to improve the whole efficiency of our Greit-HRNet. Our experiments on both MS-COCO and MPII human pose estimation datasets demonstrate the superior performance of our Greit-HRNet, outperforming other state-of-the-art lightweight networks.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Andriluka, M., Pishchulin, L., Gehler, P., Schiele, B.: 2d human pose estimation: New benchmark and state of the art analysis. In: Proceedings of the IEEE Conference on computer Vision and Pattern Recognition. pp. 3686–3693 (2014)
Cheng, B., Xiao, B., Wang, J., Shi, H., Huang, T.S., Zhang, L.: Higherhrnet: Scale-aware representation learning for bottom-up human pose estimation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5386–5395 (2020)
Ding, X., Zhang, X., Han, J., Ding, G.: Scaling up your kernels to 31x31: Revisiting large kernel design in cnns. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11963–11975 (2022)
Farag, M.M., Fouad, M., Abdel-Hamid, A.T.: Automatic severity classification of diabetic retinopathy based on densenet and convolutional block attention module. IEEE Access 10, 38299–38308 (2022)
Guo, M.H., Lu, C.Z., Liu, Z.N., Cheng, M.M., Hu, S.M.: Visual attention network. Computational Visual Media 9(4), 733–752 (2023)
Howard, A.G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., Andreetto, M., Adam, H.: Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861 (2017)
Huang, T., Yin, L., Zhang, Z., Shen, L., Fang, M., Pechenizkiy, M., Wang, Z., Liu, S.: Are large kernels better teachers than transformers for convnets? In: International Conference on Machine Learning. pp. 14023–14038. PMLR (2023)
Kim, J.S., Park, S.W., Kim, J.Y., Park, J., Huh, J.H., Jung, S.H., Sim, C.B.: E-hrnet: Enhanced semantic segmentation using squeeze and excitation. Electronics 12(17), 3619 (2023)
Li, Q., Zhang, Z., Xiao, F., Zhang, F., Bhanu, B.: Dite-hrnet: Dynamic lightweight high-resolution network for human pose estimation. arXiv preprint arXiv:2204.10762 (2022)
Li, X., Sun, S., Zhang, Z., Chen, Z.: Multi-scale grouped dense network for vvc intra coding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. pp. 158–159 (2020)
Lin, T.-Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft COCO: Common Objects in Context. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014. LNCS, vol. 8693, pp. 740–755. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10602-1_48
Luo, Y., Ou, Z., Wan, T., Guo, J.M.: Fastnet: Fast high-resolution network for human pose estimation. Image Vis. Comput. 119, 104390 (2022)
Ma, N., Zhang, X., Zheng, H.T., Sun, J.: Shufflenet v2: Practical guidelines for efficient cnn architecture design. In: Proceedings of the European conference on computer vision (ECCV). pp. 116–131 (2018)
Neff, C., Sheth, A., Furgurson, S., Middleton, J., Tabkhi, H.: Efficienthrnet: efficient and scalable high-resolution networks for real-time multi-person 2d human pose estimation. J. Real-Time Image Proc. 18(4), 1037–1049 (2021)
Ouyang, D., He, S., Zhang, G., Luo, M., Guo, H., Zhan, J., Huang, Z.: Efficient multi-scale attention module with cross-spatial learning. In: ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. 1–5. IEEE (2023)
Rui, L., Gao, Y., Ren, H.: Edite-hrnet: Enhanced dynamic lightweight high-resolution network for human pose estimation. IEEE Access (2023)
Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., Chen, L.C.: Mobilenetv2: Inverted residuals and linear bottlenecks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 4510–4520 (2018)
Sigal, L.: Human pose estimation. In: Computer Vision: A Reference Guide, pp. 573–592. Springer (2021)
Sun, K., Xiao, B., Liu, D., Wang, J.: Deep high-resolution representation learning for human pose estimation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5693–5703 (2019)
Tan, A., Guo, T., Zhao, Y., Wang, Y., Li, X.: Object detection based on polarization image fusion and grouped convolutional attention network. Vis. Comput. 40(5), 3199–3215 (2024)
Wang, J., Qiao, X., Liu, C., Wang, X., Liu, Y., Yao, L., Zhang, H.: Automated ecg classification using a non-local convolutional block attention module. Comput. Methods Programs Biomed. 203, 106006 (2021)
Wang, J., Sun, K., Cheng, T., Jiang, B., Deng, C., Zhao, Y., Liu, D., Mu, Y., Tan, M., Wang, X., et al.: Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 43(10), 3349–3364 (2020)
Wang, X., Girshick, R., Gupta, A., He, K.: Non-local neural networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 7794–7803 (2018)
Wang, Y., Li, M., Cai, H., Chen, W.M., Han, S.: Lite pose: Efficient architecture design for 2d human pose estimation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13126–13136 (2022)
Woo, S., Park, J., Lee, J.Y., Kweon, I.S.: Cbam: Convolutional block attention module. In: Proceedings of the European conference on computer vision (ECCV). pp. 3–19 (2018)
Xiao, B., Wu, H., Wei, Y.: Simple baselines for human pose estimation and tracking. In: Proceedings of the European conference on computer vision (ECCV). pp. 466–481 (2018)
Xu, Y., Zhang, J., Zhang, Q., Tao, D.: Vitpose: Simple vision transformer baselines for human pose estimation. Adv. Neural. Inf. Process. Syst. 35, 38571–38584 (2022)
Yu, C., Xiao, B., Gao, C., Yuan, L., Zhang, L., Sang, N., Wang, J.: Lite-hrnet: A lightweight high-resolution network. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10440–10450 (2021)
Yuan, Y., Fu, R., Huang, L., Lin, W., Zhang, C., Chen, X., Wang, J.: Hrformer: High-resolution transformer for dense prediction. arXiv preprint arXiv:2110.09408 (2021)
Zhang, X., Zhou, X., Lin, M., Sun, J.: Shufflenet: An extremely efficient convolutional neural network for mobile devices. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 6848–6856 (2018)
Zhang, X., Zeng, H., Guo, S., Zhang, L.: Efficient long-range attention network for image super-resolution. In: European conference on computer vision. pp. 649–667. Springer (2022)
Zhang, Z., Wang, M.: Convolutional neural network with convolutional block attention module for finger vein recognition. arXiv preprint arXiv:2202.06673 (2022)
Zheng, C., Wu, W., Chen, C., Yang, T., Zhu, S., Shen, J., Kehtarnavaz, N., Shah, M.: Deep learning-based human pose estimation: A survey. ACM Comput. Surv. 56(1), 1–37 (2023)
Zhou, Y., Wang, X., Xu, X., Zhao, L., Song, J.: X-hrnet: Towards lightweight human pose estimation with spatially unidimensional self-attention. In: 2022 IEEE international conference on multimedia and expo (ICME). pp. 01–06. IEEE (2022)
Acknowledgments
This study was funded by Professor Yingxia Yu. We would like to express our sincere gratitude to Professor Yanxia Wang for her invaluable guidance throughout this research. We also extend our heartfelt thanks to Shuyao Shang for his assistance and support.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Ethics declarations
Disclosure of Interests
The authors have no competing interests to declare that are relevant to the content of this article.
Rights and permissions
Copyright information
© 2025 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Han, J., Wang, Y. (2025). Greit-HRNet: Grouped Lightweight High-Resolution Network for Human Pose Estimation. In: Cho, M., Laptev, I., Tran, D., Yao, A., Zha, H. (eds) Computer Vision – ACCV 2024. ACCV 2024. Lecture Notes in Computer Science, vol 15472. Springer, Singapore. https://doi.org/10.1007/978-981-96-0885-0_15
Download citation
DOI: https://doi.org/10.1007/978-981-96-0885-0_15
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-96-0884-3
Online ISBN: 978-981-96-0885-0
eBook Packages: Computer ScienceComputer Science (R0)