
Abstract
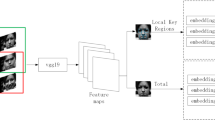
Facial Expression Recognition (FER) has received increasing attention in the computer vision community. For FER, there are two challenging issues among the facial images: large inter-class similarity and small intra-class discrepancy. To address these challenges and obtain a better performance, we propose a Local-Global Cross-Fusion Transformer network in this paper. Specifically, the method seeks to obtain a more discriminative facial representation by sufficiently considering the local features of multiple local regions of the face and global face features. In order to extract the critical local area features of the face, a local feature decomposition module based on facial landmarks is designed. In addition, a local-global cross-fusion Transformer is designed to enhance the synergistic correlation between local features and global features using the cross-attention mechanism, which can maximize the focus on key regions while considering the connection information among local regions. Extensive experiments conducted on three mainstream expression recognition datasets, RAF-DB, FERPlus, and AffectNet, show that the method outperforms many existing expression recognition methods and can significantly improve the accuracy of expression recognition.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Barsoum, E., Zhang, C., Ferrer, C.C., Zhang, Z.: Training deep networks for facial expression recognition with crowd-sourced label distribution. In: Proceedings of the 18th ACM International Conference on Multimodal Interaction, pp. 279–283 (2016)
Chen, C.F.R., Fan, Q., Panda, R.: CrossViT: cross-attention multi-scale vision transformer for image classification. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 357–366 (2021)
Chen, S., Liu, Y., Gao, X., Han, Z.: MobileFaceNets: efficient CNNs for accurate real-time face verification on mobile devices. In: Zhou, J., et al. (eds.) Biometric Recognition: 13th Chinese Conference, CCBR 2018, Urumqi, China, 11–12 August 2018, Proceedings 13, pp. 428–438. Springer, Cham (2018). https://doi.org/10.1007/978-3-319-97909-0_46
Chen, S., Wang, J., Chen, Y., Shi, Z., Geng, X., Rui, Y.: Label distribution learning on auxiliary label space graphs for facial expression recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13984–13993 (2020)
Cotter, S.F.: Sparse representation for accurate classification of corrupted and occluded facial expressions. In: 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, pp. 838–841. IEEE (2010)
Dalal, N., Triggs, B.: Histograms of oriented gradients for human detection. In: 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2005), vol. 1, pp. 886–893. IEEE (2005)
Deng, J., Guo, J., Xue, N., Zafeiriou, S.: ArcFace: additive angular margin loss for deep face recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4690–4699 (2019)
Dosovitskiy, A., et al.: An image is worth 16 \(\times \) 16 words: transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
Farzaneh, A.H., Qi, X.: Facial expression recognition in the wild via deep attentive center loss. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 2402–2411 (2021)
Guo, Y., Zhang, L., Hu, Y., He, X., Gao, J.: MS-Celeb-1M: a dataset and benchmark for large-scale face recognition. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016, Proceedings, Part III 14, pp. 87–102. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46487-9_6
Huang, Y.F., Tsai, C.H.: PIDViT: pose-invariant distilled vision transformer for facial expression recognition in the wild. IEEE Trans. Affect. Comput. 14(4), 3281–3293 (2022)
Kingma, D.P., Ba, J.: Adam: a method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
Li, H., Wang, N., Ding, X., Yang, X., Gao, X.: Adaptively learning facial expression representation via CF labels and distillation. IEEE Trans. Image Process. 30, 2016–2028 (2021)
Li, S., Deng, W., Du, J.: Reliable crowdsourcing and deep locality-preserving learning for expression recognition in the wild. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2852–2861 (2017)
Lin, W., et al.: CAT: cross-attention transformer for one-shot object detection. arXiv preprint arXiv:2104.14984 (2021)
Ma, F., Sun, B., Li, S.: Facial expression recognition with visual transformers and attentional selective fusion. IEEE Trans. Affect. Comput. 14(2), 1236–1248 (2021)
Mollahosseini, A., Hasani, B., Mahoor, M.H.: AffectNet: a database for facial expression, valence, and arousal computing in the wild. IEEE Trans. Affect. Comput. 10(1), 18–31 (2017)
Rifai, S., Bengio, Y., Courville, A., Vincent, P., Mirza, M.: Disentangling factors of variation for facial expression recognition. In: Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C. (eds.) Computer Vision–ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012, Proceedings, Part VI 12, pp. 808–822. Springer, Cham (2012). https://doi.org/10.1007/978-3-642-33783-3_58
Ruan, D., Yan, Y., Lai, S., Chai, Z., Shen, C., Wang, H.: Feature decomposition and reconstruction learning for effective facial expression recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7660–7669 (2021)
Shan, C., Gong, S., McOwan, P.W.: Facial expression recognition based on local binary patterns: a comprehensive study. Image Vis. Comput. 27(6), 803–816 (2009)
She, J., Hu, Y., Shi, H., Wang, J., Shen, Q., Mei, T.: Dive into ambiguity: latent distribution mining and pairwise uncertainty estimation for facial expression recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6248–6257 (2021)
Maximiano da Silva, F.A., Pedrini, H.: Geometrical features and active appearance model applied to facial expression recognition. Int. J. Image Graph. 16(04), 1650019 (2016)
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., Wojna, Z.: Rethinking the inception architecture for computer vision. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2818–2826 (2016)
Vaswani, A., et al.: Attention is all you need. In: Proceedings of the 31st International Conference on Neural Information Processing Systems, pp. 6000–6010 (2017)
Wang, K., Peng, X., Yang, J., Lu, S., Qiao, Y.: Suppressing uncertainties for large-scale facial expression recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6897–6906 (2020)
Wang, K., Peng, X., Yang, J., Meng, D., Qiao, Y.: Region attention networks for pose and occlusion robust facial expression recognition. IEEE Trans. Image Process. 29, 4057–4069 (2020)
Wen, Z., Lin, W., Wang, T., Xu, G.: Distract your attention: multi-head cross attention network for facial expression recognition. Biomimetics 8(2), 199 (2023)
Xu, X., Wang, T., Yang, Y., Zuo, L., Shen, F., Shen, H.T.: Cross-modal attention with semantic consistence for image-text matching. IEEE Trans. Neural Networks Learn. Syst. 31(12), 5412–5425 (2020)
Xue, F., Wang, Q., Guo, G.: Transfer: learning relation-aware facial expression representations with transformers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 3601–3610 (2021)
Zeng, D., Lin, Z., Yan, X., Liu, Y., Wang, F., Tang, B.: Face2Exp: combating data biases for facial expression recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 20291–20300 (2022)
Zhang, Y., Wang, C., Ling, X., Deng, W.: Learn from all: erasing attention consistency for noisy label facial expression recognition. In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds.) Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022, Proceedings, Part XXVI, pp. 418–434. Springer, Cham (2022). https://doi.org/10.1007/978-3-031-19809-0_24
Zhao, Z., Liu, Q., Wang, S.: Learning deep global multi-scale and local attention features for facial expression recognition in the wild. IEEE Trans. Image Process. 30, 6544–6556 (2021)
Zhao, Z., Liu, Q., Zhou, F.: Robust lightweight facial expression recognition network with label distribution training. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, pp. 3510–3519 (2021)
Acknowledgements
This work is supported by the Higher Education Stability Support Program Project (Grant No. GXWD20220811173317002) and Shenzhen Science and Technology Program (Grant No. RCBS20210609103709020).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2024 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Liu, Y., Li, Z., Zhang, Y., Wen, J. (2024). Local-Global Cross-Fusion Transformer Network for Facial Expression Recognition. In: Song, X., Feng, R., Chen, Y., Li, J., Min, G. (eds) Web and Big Data. APWeb-WAIM 2023. Lecture Notes in Computer Science, vol 14332. Springer, Singapore. https://doi.org/10.1007/978-981-97-2390-4_18
Download citation
DOI: https://doi.org/10.1007/978-981-97-2390-4_18
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-97-2389-8
Online ISBN: 978-981-97-2390-4
eBook Packages: Computer ScienceComputer Science (R0)