
Abstract
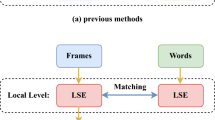
Video-sharing platforms emphasize video-text retrieval in multimodal information retrieval. Existing methods often overlook video text intricacies and redundancy, focusing mainly on single-granularity information. To address this, we propose Fine-grained Cross-modal Contrast Learning (FCCL), an end-to-end framework. FCCL includes a frame enhancement module to reduce data complexity by discerning key features from each video frame. Additionally, we introduce a multimodal attention model to identify text-similar video sub-regions accurately. We also intro-duce a multi-granularity discrepancy analysis model to capture cross-modal similarity across different levels, including video-sentence, frame-sentence, and frame-word perspectives. Experimental results on MSR-VTT and MSVD datasets demonstrate FCCL's superiority in video-text retrieval. Code is available at: https://github.com/LHlh917/FCCL.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


Disclosure of Interests
The authors have no competing interests to declare that are relevant to the content of this article.
References
Nian, F., et al.: Multi-level cross-modal semantic alignment network for video–text retrieval. Mathematics 10(18), 3346 (2022)
Liu, S., et al.: Hit: hierarchical transformer with momentum contrast for video-text re-trieval. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2021)
Fang, H., et al.: Clip2video: mastering video-text retrieval via image clip. arxiv preprint arxiv:2106.11097 (2021)
Radford, A., et al.: Learning transferable visual models from natural language supervi-sion. In: International Conference on Machine Learning. PMLR (2021)
Portillo-Quintero, J.A., Ortiz-Bayliss, J.C., Terashima-Marín, H.: A straightforward framework for video retrieval using clip. In: Mexican Conference on Pattern Recognition, pp. 3–12. Springer, Cham (2021)
Patrick, M., et al.: Support-set bottlenecks for video-text representation learning. arxiv preprint arxiv:2010.02824 (2020)
Luo, H., et al.: Clip4clip: an empirical study of clip for end to end video clip retrieval and captioning. Neurocomputing 508, 293–304 (2022)
Ma, Y., et al.: X-clip: end-to-end multi-grained contrastive learning for video-text re-trieval. In: Proceedings of the 30th ACM International Conference on Multimedia (2022)
Gorti, S.K., et al.: X-pool: cross-modal language-video attention for text-video re-trieval. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2022)
Yao, L., et al.: Filip: fine-grained interactive language-image pre-training. arXiv pre-print arXiv:2111.07783 (2021)
Lee, K.-H., et al.: Stacked cross attention for image-text matching. In: Proceedings of the European Conference on Computer Vision (ECCV) (2018)
Kay, W., Carreira, J., Simonyan, K., et al.: The kinetics human action video dataset. arxiv pre-print arxiv:1705.06950 (2017)
Chen, D., Dolan, W.B.: Collecting highly parallel data for paraphrase evaluation. In: Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies (2011)
Zhu, L., Yi, Y.: Actbert: learning global-local video-text representations. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2020)
Bain, M., et al.: Frozen in time: a joint video and image encoder for end-to-end retrieval. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2021)
Wang, Z., et al.: Simvlm: simple visual language model pretraining with weak supervision. arxiv preprint arxiv:2108.10904 (2021)
Dzabraev, M., et al.: Mdmmt: multidomain multimodal transformer for video retrieval. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (2021)
Yang, J., et al.: Membridge: video-language pre-training with memory-augmented in-ter-modality bridge. IEEE Trans. Image Process. (2023)
Jiang, J., et al.: Tencent text-video retrieval: hierarchical cross-modal interactions with mul-ti-level representations. IEEE Access (2022)
Wang, Z., et al.: Unified coarse-to-fine alignment for video-text retrieval. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2023)
Liu, Y., et al.: Ts2-net: token shift and selection transformer for text-video retrieval. In: European Conference on Computer Vision. Springer, Cham (2022)
Zhai, A., Wu, H.-Y.: Classification is a strong baseline for deep metric learning. arxiv preprint arxiv:1811.12649 (2018)
Xu, J., et al.: Msr-vtt: a large video description dataset for bridging video and language. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2016)
Yu, Y., Kim, J., Kim, G.: A joint sequence fusion model for video question answering and retrieval. In: Proceedings of the European Conference on Computer Vi-sion (ECCV) (2018)
Liu, Y., et al.: Use what you have: Video retrieval using representations from collabora-tive experts. arxiv preprint arxiv:1907.13487 (2019)
Gabeur, V., et al.: Multi-modal transformer for video retrieval. In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part IV 16. Springer (2020)
Croitoru, I., et al.: Teachtext: crossmodal generalized distillation for text-video retrieval. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2021)
Acknowledgements
This work was supported in part by Anhui Provincial Key Research and Development Program (No. 2022a05020042), the University Synergy Innovation Program of Anhui Province (No. GXXT-2022-043), and Natural Science Research Project of Anhui Educational Committee (No. 2022AH051783).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2024 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Liu, H., Lv, G., Gu, Y., Nian, F. (2024). Fine-Grained Cross-Modal Contrast Learning for Video-Text Retrieval. In: Huang, DS., Zhang, X., Guo, J. (eds) Advanced Intelligent Computing Technology and Applications. ICIC 2024. Lecture Notes in Computer Science, vol 14866. Springer, Singapore. https://doi.org/10.1007/978-981-97-5594-3_25
Download citation
DOI: https://doi.org/10.1007/978-981-97-5594-3_25
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-97-5593-6
Online ISBN: 978-981-97-5594-3
eBook Packages: Computer ScienceComputer Science (R0)