
Abstract
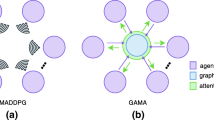
The coordination between agents in multi-agent systems has become a popular topic in many fields. To catch the inner relationship between agents, the graph structure is combined with existing methods and improves the results. But in large-scale tasks with numerous agents, an overly complex graph would lead to a boost in computational cost and a decline in performance. Here we present DAGMIX, a novel graph-based value factorization method. Instead of a complete graph, DAGMIX generates a dynamic graph at each time step during training, on which it realizes a more interpretable and effective combining process through the attention mechanism. Experiments show that DAGMIX significantly outperforms previous SOTA methods in large-scale scenarios, as well as achieving promising results on other tasks.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Berner, C., et al.: Dota 2 with large scale deep reinforcement learning. arXiv preprint arXiv:1912.06680 (2019)
Ha, D., Dai, A., Le, Q.V.: Hypernetworks. arXiv preprint arXiv:1609.09106 (2016)
Hamilton, W., Ying, Z., Leskovec, J.: Inductive representation learning on large graphs. In: Advances in Neural Information Processing Systems, vol. 30 (2017)
Jang, E., Gu, S., Poole, B.: Categorical reparameterization with gumbel-softmax. arXiv preprint arXiv:1611.01144 (2016)
Kipf, T.N., Welling, M.: Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907 (2016)
Kortvelesy, R., Prorok, A.: QGNN: value function factorisation with graph neural networks. arXiv preprint arXiv:2205.13005 (2022)
Li, S., Gupta, J.K., Morales, P., Allen, R., Kochenderfer, M.J.: Deep implicit coordination graphs for multi-agent reinforcement learning. arXiv preprint arXiv:2006.11438 (2020)
Liu, Y., Wang, W., Hu, Y., Hao, J., Chen, X., Gao, Y.: Multi-agent game abstraction via graph attention neural network. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, pp. 7211–7218 (2020)
Lowe, R., Wu, Y.I., Tamar, A., Harb, J., Pieter Abbeel, O., Mordatch, I.: Multi-agent actor-critic for mixed cooperative-competitive environments. In: Advances in Neural Information Processing Systems, vol. 30 (2017)
Mahajan, A., Rashid, T., Samvelyan, M., Whiteson, S.: MAVEN: multi-agent variational exploration. In: Advances in Neural Information Processing Systems, vol. 32 (2019)
Malysheva, A., Kudenko, D., Shpilman, A.: MAGNet: multi-agent graph network for deep multi-agent reinforcement learning. In: 2019 XVI International Symposium “Problems of Redundancy in Information and Control Systems” (REDUNDANCY), pp. 171–176. IEEE (2019)
Oliehoek, F.A., Amato, C.: A Concise Introduction to Decentralized POMDPs. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-28929-8
Rashid, T., Farquhar, G., Peng, B., Whiteson, S.: Weighted QMIX: expanding monotonic value function factorisation for deep multi-agent reinforcement learning. In: Advances in Neural Information Processing Systems, vol. 33, pp. 10199–10210 (2020)
Rashid, T., Samvelyan, M., Schroeder, C., Farquhar, G., Foerster, J., Whiteson, S.: QMIX: monotonic value function factorisation for deep multi-agent reinforcement learning. In: International Conference on Machine Learning, pp. 4295–4304. PMLR (2018)
Samvelyan, M., et al.: The StarCraft multi-agent challenge. arXiv preprint arXiv:1902.04043 (2019)
Shamsoshoara, A., Khaledi, M., Afghah, F., Razi, A., Ashdown, J.: Distributed cooperative spectrum sharing in UAV networks using multi-agent reinforcement learning. In: 2019 16th IEEE Annual Consumer Communications & Networking Conference (CCNC), pp. 1–6. IEEE (2019)
Son, K., Kim, D., Kang, W.J., Hostallero, D., Yi, Y.: QTRAN: learning to factorize with transformation for cooperative multi-agent reinforcement learning. CoRR abs/1905.05408 (2019). https://arxiv.org/abs/1905.05408
Sunehag, P., et al.: Value-decomposition networks for cooperative multi-agent learning. arXiv preprint arXiv:1706.05296 (2017)
Sutton, R.S., Barto, A.G.: Reinforcement Learning: An Introduction. MIT Press, Cambridge (2018)
Tampuu, A., et al.: Multiagent cooperation and competition with deep reinforcement learning. PLoS ONE 12(4), e0172395 (2017)
Vaswani, A., et al.: Attention is all you need. In: Advances in Neural Information Processing Systems, vol. 30 (2017)
Vinyals, O., et al.: Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 575(7782), 350–354 (2019)
Wang, J., Ren, Z., Liu, T., Yu, Y., Zhang, C.: QPLEX: duplex dueling multi-agent Q-learning. arXiv preprint arXiv:2008.01062 (2020)
Wang, T., Dong, H., Lesser, V., Zhang, C.: ROMA: multi-agent reinforcement learning with emergent roles. arXiv preprint arXiv:2003.08039 (2020)
Wang, T., Gupta, T., Mahajan, A., Peng, B., Whiteson, S., Zhang, C.: RODE: learning roles to decompose multi-agent tasks. arXiv preprint arXiv:2010.01523 (2020)
Xu, D., Chen, G.: Autonomous and cooperative control of UAV cluster with multi-agent reinforcement learning. Aeronaut. J. 126(1300), 932–951 (2022)
Xu, Z., Zhang, B., Bai, Y., Li, D., Fan, G.: Learning to coordinate via multiple graph neural networks. In: Mantoro, T., Lee, M., Ayu, M.A., Wong, K.W., Hidayanto, A.N. (eds.) ICONIP 2021. LNCS, vol. 13110, pp. 52–63. Springer, Cham (2021). https://doi.org/10.1007/978-3-030-92238-2_5
Yang, Y., et al.: Qatten: a general framework for cooperative multiagent reinforcement learning. arXiv preprint arXiv:2002.03939 (2020)
Ye, D., et al.: Towards playing full MOBA games with deep reinforcement learning. In: Advances in Neural Information Processing Systems, vol. 33, pp. 621–632 (2020)
Acknowledgements
This work was supported by the Strategic Priority Research Program of the Chinese Academy of Science, Grant No. XDA27050100.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2024 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Zhou, G., Xu, Z., Zhang, Z., Fan, G. (2024). Mastering Complex Coordination Through Attention-Based Dynamic Graph. In: Luo, B., Cheng, L., Wu, ZG., Li, H., Li, C. (eds) Neural Information Processing. ICONIP 2023. Lecture Notes in Computer Science, vol 14447. Springer, Singapore. https://doi.org/10.1007/978-981-99-8079-6_24
Download citation
DOI: https://doi.org/10.1007/978-981-99-8079-6_24
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-99-8078-9
Online ISBN: 978-981-99-8079-6
eBook Packages: Computer ScienceComputer Science (R0)