
Abstract
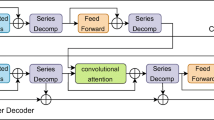
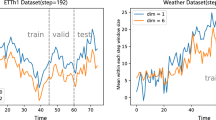
Transformer-based methods have shown excellent results in long-term series forecasting, but they still suffer from high time and space costs; difficulties in analysing sequence correlation due to entanglement of the original sequence; bottleneck in information utilisation due to the dot-product pattern of the attention mechanism. To address these problems, we propose a sequence decomposition architecture to identify the different features of sub-series decomposed from the original time series. We then utilize causal convolution to solve the information bottleneck problem caused by the attention mechanism’s dot-product pattern. To further improve the efficiency of the model in handling long-term series forecasting, we propose the Linear Convolution Transformer (LCformer) based on a linear self-attention mechanism with O(n) complexity, which exhibits superior prediction performance and lower consumption on long-term series prediction problems. Experimental results on two different types of benchmark datasets show that the LCformer exhibits better prediction performance compared to those of the state-of-the-art Transformer-based methods, and exhibits near linear complexity for long series prediction.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

References
Vaswani, A., et al.: Attention is all you need. In: Proceedings of the 31st International Conference on Neural Information Processing Systems, pp. 6000–6010. Curran Associates Inc. (2017)
Zhou, H., Zhang, S., Peng, J., et al.: Informer: beyond efficient transformer for long sequence time-series forecasting. In: Proceedings of the 35th AAAI Conference on Artificial Intelligence, vol. 35, no. 12, pp. 11106–11115. Association for the Advancement of Artificial Intelligence (AAAI) (2021)
Wu, H., Xu, J., Wang, J., et al.: Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. Adv. Neural. Inf. Process. Syst. 34(1), 22419–22430 (2021)
Durbin, J., Koopman, S.J.: Time Series Analysis by State Space Methods: Second Edition. Oxford University Press (2012). https://doi.org/10.1093/acprof:oso/9780199641178.001.0001
Pascanu, R., Mikolov, T., Bengio, Y.: On the difficulty of training recurrent neural networks. In: 30th International Conference on Machine Learning, pp. 1310–1318. Association for Computing and Machinery (ACM) (2013)
Zhao, J., Huang, F., Lv, J., et al.: Do RNN and LSTM have long memory? In: Proceedings of the 37th International Conference on Machine Learning, PMLR, pp. 11365–11375. Association for Computing and Machinery (ACM) (2020)
Salinas, D., Flunkert, V., Gasthaus, J., et al.: DeepAR: probabilistic forecasting with autoregressive recurrent networks. Int. J. Forecast. 36(3), 1181–1191 (2020)
Lai, G., Chang, W.C., Yang, Y., et al.: Modeling long-and short-term temporal patterns with deep neural networks. In: 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, pp. 95–104. Association for Computing Machinery (ACM) (2018)
Shih, S.Y., Sun, F.K., Lee, H.: Temporal pattern attention for multivariate time series forecasting. Mach. Learn. 108, 1421–1441 (2019)
Brown, T., Mann, B., Ryder, N., et al.: Language models are few-shot learners. Adv. Neural. Inf. Process. Syst. 33, 1877–1901 (2020)
Wang, J., Jin, L., Ding, K.: LiLT: a simple yet effective language-independent layout transformer for structured document understanding. In: Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, vol. 1, pp. 7747–7757. Association for Computational Linguistics (ACL) (2022)
Peer, D., Stabinger, S., Engl, S., et al.: Greedy-layer pruning: speeding up transformer models for natural language processing. Pattern Recogn. Lett. 157, 76–82 (2022)
Kjell, O.N.E., Sikström, S., Kjell, K., et al.: Natural language analyzed with AI-based transformers predict traditional subjective well-being measures approaching the theoretical upper limits in accuracy. Sci. Rep. 12(1), 3918 (2022)
Von der Mosel, J., Trautsch, A., Herbold, S.: On the validity of pre-trained transformers for natural language processing in the software engineering domain. IEEE Trans. Software Eng. 49(4), 1487–1507 (2023)
Dong, X., Bao, J., Chen, D., et al.: CSWin transformer: a general vision transformer backbone with cross-shaped windows. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12124–12134. Institute of Electrical and Electronics Engineers (IEEE) (2022)
Lee, Y., Kim, J., Willette, J., et al.: MPViT: multi-path vision transformer for dense prediction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7287–7296. Institute of Electrical and Electronics Engineers (IEEE) (2022)
Zhengzhong, T., et al.: Maxvit: Multi-axis vision transformer. In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds.) Computer Vision – ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXIV, pp. 459–479. Springer Nature Switzerland, Cham (2022). https://doi.org/10.1007/978-3-031-20053-3_27
Li, B., Zhao, Y., Zhelun, S., et al.: DanceFormer: music conditioned 3D dance generation with parametric motion transformer. In: Proceedings of the 36th AAAI Conference on Artificial Intelligence, vol. 36, no. 2, pp. 1272–1279. Association for the Advancement of Artificial Intelligence (AAAI) (2022)
Di, S., Jiang, Z., Liu, S., et al.: Video background music generation with controllable music transformer. In: Proceedings of the 29th ACM International Conference on Multimedia, pp. 2037–2045. Association for Computing Machinery (ACM) (2021)
Hernandez-Olivan, C., Beltrán, J.R.: Music composition with deep learning: a review. In: Biswas, A., Wennekes, E., Wieczorkowska, A., Laskar, R.H. (eds.) Advances in Speech and Music Technology: Computational Aspects and Applications, pp. 25–50. Springer International Publishing, Cham (2023). https://doi.org/10.1007/978-3-031-18444-4_2
Li, S., Jin, X., Xuan, Y., et al.: Enhancing the locality and breaking the memory bottleneck of transformer on time series forecasting. In: Proceedings of the 33rd International Conference on Neural Information Processing Systems, pp. 5243–5253. Curran Associates Inc. (2019)
Yang, X., Liu, Y., Wang, X.: ReFormer: the relational transformer for image captioning. In: Proceedings of the 30th ACM International Conference on Multimedia, pp. 5398–5406. Association for Computing Machinery (ACM) (2022)
Chen, C., Liu, Y., Chen, L., et al.: Bidirectional spatial-temporal adaptive transformer for urban traffic flow forecasting. IEEE Trans. Neural Networks Learn. Syst. 34, 6913–6925 (2022)
Dao, T., Fu, D., Ermon, S., et al.: FlashAttention: fast and memory-efficient exact attention with IO-awareness. Adv. Neural. Inf. Process. Syst. 35, 16344–16359 (2022)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2024 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Qin, J., Gao, C., Wang, D. (2024). LCformer: Linear Convolutional Decomposed Transformer for Long-Term Series Forecasting. In: Luo, B., Cheng, L., Wu, ZG., Li, H., Li, C. (eds) Neural Information Processing. ICONIP 2023. Communications in Computer and Information Science, vol 1962. Springer, Singapore. https://doi.org/10.1007/978-981-99-8132-8_5
Download citation
DOI: https://doi.org/10.1007/978-981-99-8132-8_5
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-99-8131-1
Online ISBN: 978-981-99-8132-8
eBook Packages: Computer ScienceComputer Science (R0)