
Abstract
The recent pandemic has witnessed a parallel infodemic happening on social media platforms, leading to fear and anxiety within the population. Traditional machine learning (ML) frameworks for fake news detection are limited by the availability of data for training the model. By the time sufficient labeled datasets are available, the existing infodemic may itself come to an end. We propose a COVID-19 fake news detection framework using cross-domain classification techniques to achieve high levels of accuracy while reducing the waiting time for large training datasets to become available. We investigate the effectiveness of three approaches: Domain Adaptive Training, Transfer Learning, and Knowledge Distillation that reuse ML models from past infodemics to improve the accuracy in detecting COVID-19 fake news. Experiments with real-world datasets depict that Transfer Learning performs better than Domain Adaptive Training and Knowledge Distillation techniques.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others
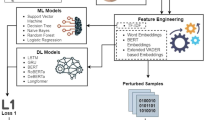

References
Fake News Detection Datasets - University of Victoria. https://www.uvic.ca/ecs/ece/isot/datasets/fake-news/index.php
Fake News. https://kaggle.com/competitions/fake-news
Wang, S.: File structure (2022). https://github.com/MickeysClubhouse/COVID-19-rumor-dataset. Accessed 24 May 2022
Cui, L., Lee, D.: CoAID: COVID-19 healthcare misinformation dataset. arXiv (2020). http://arxiv.org/abs/2006.00885. Accessed 24 May 2022
Pennington, J., Socher, R., Manning, C.: GloVe: global vectors for word representation. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, pp. 1532–1543 (2014). https://doi.org/10.3115/v1/D14-1162
Mikolov, T., Chen, K., Corrado, G., Dean, J.: Efficient estimation of word representations in vector space. arXiv (2013). http://arxiv.org/abs/1301.3781. Accessed 30 May 2022
Conroy, N.J., Rubin, V.L., Chen, Y.: Automatic deception detection: methods for finding fake news. Proc. Assoc. Inf. Sci. Technol. 52(1), 1–4 (2015)
Khurana, U., Intelligentie, B.O.K.: The linguistic features of fake news headlines and statements (2017)
Bhattacharjee, S.D., Talukder, A., Balantrapu, B.V.: Active learning based news veracity detection with feature weighting and deep-shallow fusion. In: 2017 IEEE International Conference on Big Data (Big Data), pp. 556–565. IEEE (2017)
Hassan, N., Arslan, F., Li, C., Tremayne, M.: Toward automated fact-checking: detecting check-worthy factual claims by ClaimBuster. In: SIGKDD, pp. 1803–1812 (2017)
Rashkin, H., Choi, E., Jang, J.Y., Volkova, S., Choi, Y.: Truth of varying shades: analyzing language in fake news and political fact-checking. In: Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pp. 2931–2937 (2017)
Wang, W.Y.: “Liar, liar pants on fire”: a new benchmark dataset for fake news detection. arXiv preprint arXiv:1705.00648 (2017)
Kaliyar, R.K., Goswami, A., Narang, P.: FakeBERT: fake news detection in social media with a BERT-based deep learning approach. Multimed. Tools Appl. 80(8), 11765–11788 (2021). https://doi.org/10.1007/s11042-020-10183-2
Ramponi, A., Plank, B.: Neural unsupervised domain adaptation in NLP–a survey. arXiv (2020)
Zhang, B., Zhang, X., Liu, Y., Cheng, L., Li, Z.: Matching distributions between model and data: cross-domain knowledge distillation for unsupervised domain adaptation. In: ICONIP, pp. 5423–5433 (2021)
Peters, M.E., et al.: Deep contextualized word representations. In: HLT, pp. 2227–2237 (2018)
Kouw, W.M., Loog, M.: An introduction to domain adaptation and transfer learning. arXiv (2019). http://arxiv.org/abs/1812.11806. Accessed 24 May 2022
Ganin, Y., et al.: Domain-adversarial training of neural networks. arXiv (2016). http://arxiv.org/abs/1505.07818. Accessed 25 May 2022
Ganin, Y., Lempitsky, V.: Unsupervised domain adaptation by backpropagation. arXiv (2015). http://arxiv.org/abs/1409.7495. Accessed 25 May 2022
Gou, J., Yu, B., Maybank, S.J., Tao, D.: Knowledge distillation: a survey. Int. J. Comput. Vision 129(6), 1789–1819 (2021). https://doi.org/10.1007/s11263-021-01453-z
Müller, M., Salathé, M., Kummervold, P.E.: COVID-twitter-BERT: a natural language processing model to analyse COVID-19 content on twitter. arXiv (2020)
Multi-Domain Sentiment Dataset. https://www.cs.jhu.edu/~mdredze/datasets/sentiment/
Acknowledgement
This work is partly made possible by Regional Collaborations Programme COVID-19 Digital Grant from the Australian Academy of Science. The statements made herein are solely the responsibility of the authors.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2024 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Sharma, A., Sharma, S., Bhardwaj, U., Mistry, S., Deb, N., Krishna, A. (2024). COVID-19 Fake News Detection Using Cross-Domain Classification Techniques. In: Liu, T., Webb, G., Yue, L., Wang, D. (eds) AI 2023: Advances in Artificial Intelligence. AI 2023. Lecture Notes in Computer Science(), vol 14471. Springer, Singapore. https://doi.org/10.1007/978-981-99-8388-9_41
Download citation
DOI: https://doi.org/10.1007/978-981-99-8388-9_41
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-99-8387-2
Online ISBN: 978-981-99-8388-9
eBook Packages: Computer ScienceComputer Science (R0)