
Abstract
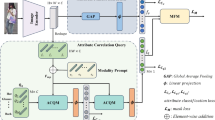
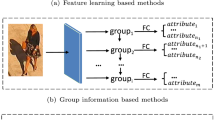
Pedestrian attribute recognition (PAR) is susceptible to variable shooting angles, lighting, and occlusions. Improving recognition accuracy to suit its application in various complex scenarios is one of the most important tasks. In this paper, based on the Image-Text Multimodal Transformer, the intra-modal and inter-modal correlations are learned from pedestrian images and attribute labels. The applicability of six different multimodal fusion frameworks for attribute recognition is explored. The impact of different frameworks’ fused feature division methods on recognition accuracy is compared and analyzed. The comparative experiments verify the robustness and efficiency of the Early Concatenate framework, which has achieved multiple best metric scores on the two major public PAR datasets, PA100k and RAP. This paper not only proposes a new Transformer-based high-accuracy multimodal network, but also provides feasible ideas and directions for further research on PAR. The comparative discussion based on various multimodal frameworks also provides a perspective that can be learned for other multimodal tasks.
Supported by the Graduate Research and Practice Projects of Minzu University of China (SJCX2022038).
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

References
Abdulnabi, A.H., Wang, G., Lu, J., Jia, K.: Multi-task CNN model for attribute prediction. IEEE Trans. Multim. 17(11), 1949–1959 (2015)
Cheng, X., Jia, M., Wang, Q., Zhang, J.: A simple visual-textual baseline for pedestrian attribute recognition. IEEE Trans. Circuits Syst. Video Technol. 32(10), 6994–7004 (2022)
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: Bert: pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018)
Dosovitskiy, A., et al.: An image is worth 16x16 words: transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
Li, D., Chen, X., Huang, K.: Multi-attribute learning for pedestrian attribute recognition in surveillance scenarios. In: 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR), pp. 111–115. IEEE (2015)
Li, D., Chen, X., Zhang, Z., Huang, K.: Pose guided deep model for pedestrian attribute recognition in surveillance scenarios. In: 2018 IEEE International Conference on Multimedia and Expo (ICME), pp. 1–6. IEEE (2018)
Li, D., Zhang, Z., Chen, X., Ling, H., Huang, K.: A richly annotated dataset for pedestrian attribute recognition. arXiv preprint arXiv:1603.07054 (2016)
Li, Q., Zhao, X., He, R., Huang, K.: Visual-semantic graph reasoning for pedestrian attribute recognition. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, pp. 8634–8641 (2019)
Li, W., Cao, Z., Feng, J., Zhou, J., Lu, J.: Label2Label: a language modeling framework for multi-attribute learning. In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds.) ECCV 2022. LNCS, vol. 13672, pp. 562–579. Springer, Cham (2022). https://doi.org/10.1007/978-3-031-19775-8_33
Liu, P., Liu, X., Yan, J., Shao, J.: Localization guided learning for pedestrian attribute recognition. arXiv preprint arXiv:1808.09102 (2018)
Liu, X., et al.: Hydraplus-net: attentive deep features for pedestrian analysis. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 350–359 (2017)
Lu, J., Batra, D., Parikh, D., Lee, S.: Vilbert: pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. Adv. Neural Inf. Process. Syst. 32 (2019)
Sarfraz, M.S., Schumann, A., Wang, Y., Stiefelhagen, R.: Deep view-sensitive pedestrian attribute inference in an end-to-end model. arXiv preprint arXiv:1707.06089 (2017)
Tang, C., Sheng, L., Zhang, Z., Hu, X.: Improving pedestrian attribute recognition with weakly-supervised multi-scale attribute-specific localization. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 4997–5006 (2019)
Tang, Z., Huang, J.: Drformer: learning dual relations using transformer for pedestrian attribute recognition. Neurocomputing 497, 159–169 (2022)
Vaswani, A., et al.: Attention is all you need. Adv. Neural Inf. Process. Syst. 30 (2017)
Wang, J., Yang, Y., Mao, J., Huang, Z., Huang, C., Xu, W.: Cnn-rnn: a unified framework for multi-label image classification. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2285–2294 (2016)
Wang, J., Zhu, X., Gong, S., Li, W.: Attribute recognition by joint recurrent learning of context and correlation. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 531–540 (2017)
Xu, P., Zhu, X., Clifton, D.A.: Multimodal learning with transformers: a survey. IEEE Trans. Pattern Anal. Mach. Intell. (2023)
Zhang, N., Paluri, M., Ranzato, M., Darrell, T., Bourdev, L.: Panda: pose aligned networks for deep attribute modeling. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1637–1644 (2014)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2024 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Liu, D., Song, W., Zhao, X. (2024). Pedestrian Attribute Recognition Based on Multimodal Transformer. In: Liu, Q., et al. Pattern Recognition and Computer Vision. PRCV 2023. Lecture Notes in Computer Science, vol 14425. Springer, Singapore. https://doi.org/10.1007/978-981-99-8429-9_34
Download citation
DOI: https://doi.org/10.1007/978-981-99-8429-9_34
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-99-8428-2
Online ISBN: 978-981-99-8429-9
eBook Packages: Computer ScienceComputer Science (R0)