
Abstract
\(\mathbb {Z}^n\) is one of the simplest types of lattices, but the computational problems on its rotations, such as \(\mathbb {Z}\)SVP and \(\mathbb {Z}\)LIP, have been of great interest in cryptography. Recent advances have been made in building cryptographic primitives based on these problems, as well as in developing new algorithms for solving them. However, the theoretical complexity of \(\mathbb {Z}\)SVP and \(\mathbb {Z}\)LIP are still not well understood.
In this work, we study the problems on rotations of \(\mathbb {Z}^n\) by exploiting the symmetry property. We introduce a randomization framework that can be roughly viewed as ‘applying random automorphisms’ to the output of an oracle, without accessing the automorphism group. Using this framework, we obtain new reduction results for rotations of \(\mathbb {Z}^n\). First, we present a reduction from \(\mathbb {Z}\)LIP to \(\mathbb {Z}\)SCVP. Here \(\mathbb {Z}\)SCVP is the problem of finding the shortest characteristic vectors, which is a special case of CVP where the target vector is a deep hole of the lattice. Moreover, we prove a reduction from \(\mathbb {Z}\)SVP to \(\gamma \)-\(\mathbb {Z}\)SVP for any constant \(\gamma = O(1)\) in the same dimension, which implies that \(\mathbb {Z}\)SVP is as hard as its approximate version for any constant approximation factor. Second, we investigate the problem of finding a nontrivial automorphism for a given lattice, which is called LAP. Specifically, we use the randomization framework to show that \(\mathbb {Z}\)LAP is as hard as \(\mathbb {Z}\)LIP. We note that our result can be viewed as a \(\mathbb {Z}^n\)-analogue of Lenstra and Silverberg’s result in [JoC2017], but with a different assumption: they assume the G-lattice structure, while we assume the access to an oracle that outputs a nontrivial automorphism.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

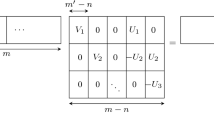

Notes
- 1.
In fact, the signed permutation group \(\mathcal {S}^{\pm }_n\) is the largest possible automorphism group among all lattices in \(\mathbb {R}^n\), with the exception of dimensions \(n=2,4,6,7,8,9,10\) [44].
- 2.
Strictly speaking, we can efficiently generate matrices in \(O_n(\mathbb {R})\) distributed with Haar measure. We refer to Sect. 3 for a detailed discussion.
- 3.
This differs slightly from our definition of LAP, which only asks to find a nontrivial automorphism. We remark that for \(\mathbb {Z}\)LAP, finding a nontrivial automorphism and finding a generating set of the automorphism group are equivalent by Theorem 1.3.
- 4.
Note that \(\text {ord}(\phi ) \mid |S_n^\pm |\), then each prime divisor of \(\text {ord}(\phi )\) is no more than n. Therefore p can be computed efficiently.
- 5.
The second method described in Sect. 3 can also be used to approximate the gradient \(\nabla g_2(\textbf{x})\).
- 6.
‘Semidirect product’ means that \(\mathcal {S}^{\pm }_n = \mathcal {D} \mathcal {S}_n\), \(\mathcal {D} \cap \mathcal {S}_n = \{\textbf{I} _n\}\) and \(\mathcal {D}\) is a normal subgroup of \(\mathcal {S}^{\pm }_n\). This implies that for any \(\textbf{T} \in \mathcal {S}^{\pm }_n\), there exist unique \(\textbf{D} \in \mathcal {D}\) and \(\textbf{P} \in \mathcal {S}_n\) such that \(\textbf{T} = \textbf{P} \textbf{D} \).
- 7.
This is consistent with the notation \(x_i = \langle \textbf{x}, \textbf{v} _i \rangle \) in Sect. 4.2.
References
Aggarwal, D., Bennett, H., Golovnev, A., Stephens-Davidowitz, N.: Fine-grained hardness of CVP(P) - everything that we can prove (and nothing else). In: Marx, D. (ed.) Proceedings of the 2021 ACM-SIAM Symposium on Discrete Algorithms, SODA 2021, Virtual Conference, 10–13 January 2021, pp. 1816–1835. SIAM (2021). https://doi.org/10.1137/1.9781611976465.109
Aggarwal, D., Dadush, D., Regev, O., Stephens-Davidowitz, N.: Solving the shortest vector problem in 2\({}^{\text{n}}\) time using discrete gaussian sampling: extended abstract. In: Servedio, R.A., Rubinfeld, R. (eds.) Proceedings of the Forty-Seventh Annual ACM on Symposium on Theory of Computing (STOC 2015), Portland, 14–17 June 2015, pp. 733–742. ACM (2015). https://doi.org/10.1145/2746539.2746606
Aggarwal, D., Li, J., Nguyen, P.Q., Stephens-Davidowitz, N.: Slide reduction, revisited—filling the gaps in SVP approximation. In: Micciancio, D., Ristenpart, T. (eds.) CRYPTO 2020. LNCS, vol. 12171, pp. 274–295. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-56880-1_10
Aggarwal, D., Li, Z., Stephens-Davidowitz, N.: A \(2^{n/2}\)-time algorithm for \(\sqrt{n}\)-SVP and \(\sqrt{n}\)-hermite SVP, and an improved time-approximation tradeoff for (H)SVP. In: Canteaut, A., Standaert, F.-X. (eds.) EUROCRYPT 2021. LNCS, vol. 12696, pp. 467–497. Springer, Cham (2021). https://doi.org/10.1007/978-3-030-77870-5_17
Aggarwal, D., Stephens-Davidowitz, N.: Just take the average! an embarrassingly simple \(2{^{n}}\)-time algorithm for SVP (and CVP). In: Seidel, R. (ed.) 1st Symposium on Simplicity in Algorithms, SOSA 2018, 7–10 January 2018, New Orleans. OASIcs, vol. 61, pp. 12:1–12:19. Schloss Dagstuhl - Leibniz-Zentrum für Informatik (2018). https://doi.org/10.4230/OASIcs.SOSA.2018.12
Aggarwal, D., Ursu, B., Vaudenay, S.: Faster sieving algorithm for approximate SVP with constant approximation factors. Cryptology ePrint Archive (2019)
Babai, L.: Graph isomorphism in quasipolynomial time [extended abstract]. In: Wichs, D., Mansour, Y. (eds.) Proceedings of the 48th Annual ACM SIGACT Symposium on Theory of Computing (STOC 2016) Cambridge, 18–21 June 2016, pp. 684–697. ACM (2016). https://doi.org/10.1145/2897518.2897542
Bennett, H.: The complexity of the shortest vector problem. Electron. Colloquium Comput. Complex. TR22-170 (2022). https://eccc.weizmann.ac.il/report/2022/170
Bennett, H., Ganju, A., Peetathawatchai, P., Stephens-Davidowitz, N.: Just how hard are rotations of \({Z}^{{n}}\)? algorithms and cryptography with the simplest lattice. IACR Cryptol. ePrint Arch., p. 1548 (2021). https://eprint.iacr.org/2021/1548
Bennett, H., Golovnev, A., Stephens-Davidowitz, N.: On the quantitative hardness of CVP. In: Umans, C. (ed.) 58th IEEE Annual Symposium on Foundations of Computer Science (FOCS 2017), Berkeley, 15–17 October 2017, pp. 13–24. IEEE Computer Society (2017). https://doi.org/10.1109/FOCS.2017.11
Blanks, T.L., Miller, S.D.: Generating cryptographically-strong random lattice bases and recognizing rotations of \(\mathbb{Z}^n\). In: Cheon, J.H., Tillich, J.-P. (eds.) PQCrypto 2021 2021. LNCS, vol. 12841, pp. 319–338. Springer, Cham (2021). https://doi.org/10.1007/978-3-030-81293-5_17
Brakerski, Z., Langlois, A., Peikert, C., Regev, O., Stehlé, D.: Classical hardness of learning with errors. In: Boneh, D., Roughgarden, T., Feigenbaum, J. (eds.) Symposium on Theory of Computing Conference (STOC 2013), Palo Alto, 1–4 June 2013, pp. 575–584. ACM (2013). https://doi.org/10.1145/2488608.2488680
Cai, J., Nerurkar, A.: An improved worst-case to average-case connection for lattice problems. In: 38th Annual Symposium on Foundations of Computer Science (FOCS 1997), Miami Beach, 19–22 October 1997, pp. 468–477. IEEE Computer Society (1997). https://doi.org/10.1109/SFCS.1997.646135
Cash, D., Hofheinz, D., Kiltz, E., Peikert, C.: Bonsai trees, or how to delegate a lattice basis. In: Gilbert, H. (ed.) EUROCRYPT 2010. LNCS, vol. 6110, pp. 523–552. Springer, Heidelberg (2010). https://doi.org/10.1007/978-3-642-13190-5_27
Collins, B., Śniady, P.: Integration with respect to the haar measure on unitary, orthogonal and symplectic group. Commun. Math. Phys. 264(3), 773–795 (2006)
Diaconis, P., Shahshahani, M.: The subgroup algorithm for generating uniform random variables. Probab. Eng. Inf. Sci. 1(1), 15–32 (1987)
Ducas, L., Gibbons, S.: Hull attacks on the lattice isomorphism problem. IACR Cryptol. ePrint Arch., p. 194 (2023). https://eprint.iacr.org/2023/194
Ducas, L., Postlethwaite, E.W., Pulles, L.N., van Woerden, W.P.J.: Hawk: module LIP makes lattice signatures fast, compact and simple. In: Agrawal, S., Lin, D. (eds.) ASIACRYPT 2022. LNCS, vol. 13794, pp. 65–94. Springer, Cham (2022). https://doi.org/10.1007/978-3-031-22972-5_3
Ducas, L., van Woerden, W.P.J.: On the lattice isomorphism problem, quadratic forms, remarkable lattices, and cryptography. In: Dunkelman, O., Dziembowski, S. (eds.) EUROCRYPT 2022. LNCS, vol. 13277, pp. 643–673. Springer, Cham (2022). https://doi.org/10.1007/978-3-031-07082-2_23
Ducas, L.: Provable lattice reduction of \({Z}^n\) with blocksize \(n/2\). Cryptology ePrint Archive, Paper 2023/447 (2023). https://eprint.iacr.org/2023/447
Dutour Sikirić, M., Haensch, A., Voight, J., van Woerden, W.P.: A canonical form for positive definite matrices. Open Book Ser. 4(1), 179–195 (2020)
Eisenträger, K., Hallgren, S., Kitaev, A.Y., Song, F.: A quantum algorithm for computing the unit group of an arbitrary degree number field. In: Shmoys, D.B. (ed.) Symposium on Theory of Computing, STOC 2014, New York, 31 May–03 June 2014, pp. 293–302. ACM (2014). https://doi.org/10.1145/2591796.2591860
Geißler, K., Smart, N.P.: Computing the M = U U\({}^{\text{ t }}\) integer matrix decomposition. In: Paterson, K.G. (ed.) Cryptography and Coding. LNCS, vol. 2898, pp. 223–233. Springer, Heidelberg (2003). https://doi.org/10.1007/978-3-540-40974-8_18
Gentry, C., Peikert, C., Vaikuntanathan, V.: Trapdoors for hard lattices and new cryptographic constructions. In: Dwork, C. (ed.) Proceedings of the 40th Annual ACM Symposium on Theory of Computing, Victoria, 17–20 May 2008, pp. 197–206. ACM (2008). https://doi.org/10.1145/1374376.1374407
Gentry, C., Szydlo, M.: Cryptanalysis of the revised NTRU signature scheme. In: Knudsen, L.R. (ed.) EUROCRYPT 2002. LNCS, vol. 2332, pp. 299–320. Springer, Heidelberg (2002). https://doi.org/10.1007/3-540-46035-7_20
Goldreich, O., Goldwasser, S., Halevi, S.: Public-key cryptosystems from lattice reduction problems. In: Jr., B.S.K. (ed.) CRYPTO 1997. LNCS, vol. 1294, pp. 112–131. Springer, Heidelberg (1997). https://doi.org/10.1007/BFb0052231
Haviv, I., Regev, O.: Hardness of the covering radius problem on lattices. Chic. J. Theor. Comput. Sci. (2012). https://cjtcs.cs.uchicago.edu/articles/2012/4/contents.html
Haviv, I., Regev, O.: On the lattice isomorphism problem. In: Chekuri, C. (ed.) Proceedings of the Twenty-Fifth Annual ACM-SIAM Symposium on Discrete Algorithms (SODA 2014), Portland, 5–7 January 2014, pp. 391–404. SIAM (2014). https://doi.org/10.1137/1.9781611973402.29
Hoeffding, W.: Probability inequalities for sums of bounded random variables. In: The Collected Works of Wassily Hoeffding, pp. 409–426 (1994)
Hoffstein, J., Howgrave-Graham, N., Pipher, J., Silverman, J.H., Whyte, W.: NTRUSign: digital signatures using the NTRU lattice. In: Joye, M. (ed.) CT-RSA 2003. LNCS, vol. 2612, pp. 122–140. Springer, Heidelberg (2003). https://doi.org/10.1007/3-540-36563-X_9
Hunkenschröder, C.: Deciding whether a lattice has an orthonormal basis is in co-np. arXiv preprint arXiv:1910.03838 (2019)
Lenstra, H.W., Jr., Silverberg, A.: Revisiting the gentry-szydlo algorithm. In: Garay, J.A., Gennaro, R. (eds.) CRYPTO 2014. LNCS, vol. 8616, pp. 280–296. Springer, Heidelberg (2014). https://doi.org/10.1007/978-3-662-44371-2_16
Lenstra, H.W., Jr., Silverberg, A.: Lattices with symmetry. J. Cryptol. 30(3), 760–804 (2017). https://doi.org/10.1007/s00145-016-9235-7
Khot, S.: Hardness of approximating the shortest vector problem in lattices. In: Proceedings of the 45th Symposium on Foundations of Computer Science (FOCS 2004), October 17–19 2004, Rome, pp. 126–135. IEEE Computer Society (2004). https://doi.org/10.1109/FOCS.2004.31
Köbler, J., Schöning, U., Torán, J.: The graph isomorphism problem: its structural complexity. Prog. Theor. Comput. Sci., Birkhäuser/Springer (1993). https://doi.org/10.1007/978-1-4612-0333-9
Kuperberg, G.: The hidden subgroup problem for infinite groups (2020). https://simons.berkeley.edu/sites/default/files/docs/21261/berkeley.pdf
Kuperberg, G.: The hidden subgroup problem for \(\mathbb{Z} ^k\) for infinite-index subgroups (2022). https://simons.berkeley.edu/sites/default/files/docs/21261/berkeley.pdf
Lenstra, A.K., Lenstra, H.W., Lovász, L.: Factoring polynomials with rational coefficients. Math. Annalen 261, 515–534 (1982)
Liu, M., Wang, X., Xu, G., Zheng, X.: Shortest lattice vectors in the presence of gaps. Cryptology ePrint Archive (2011)
Luks, E.M.: Permutation groups and polynomial-time computation. In: Finkelstein, L., Kantor, W.M. (eds.) Groups and Computation, Proceedings of a DIMACS Workshop, New Brunswick, 7–10 October 1991. DIMACS Series in Discrete Mathematics and Theoretical Computer Science, vol. 11, pp. 139–175. DIMACS/AMS (1991). https://doi.org/10.1090/dimacs/011/11
Martinet, J.: Perfect Lattices in Euclidean Spaces, vol. 327. Springer, Heidelberg (2013). https://doi.org/10.1007/978-3-662-05167-2
Mezzadri, F.: How to generate random matrices from the classical compact groups. arXiv preprint arXiv:math-ph/0609050 (2006)
Nguyen, P.Q., Regev, O.: Learning a parallelepiped: cryptanalysis of GGH and NTRU signatures. In: Vaudenay, S. (ed.) EUROCRYPT 2006. LNCS, vol. 4004, pp. 271–288. Springer, Heidelberg (2006). https://doi.org/10.1007/11761679_17
Elkies, N.D.: Intro to SPLAG (2002). https://people.math.harvard.edu/~elkies/M55a.02/lattice.html
Peikert, C.: A decade of lattice cryptography. Found. Trends Theor. Comput. Sci. 10(4), 283–424 (2016). https://doi.org/10.1561/0400000074
Plesken, W., Souvignier, B.: Computing isometries of lattices. J. Symb. Comput. 24(3–4), 327–334 (1997)
Regev, O.: Quantum computation and lattice problems. In: Proceedings of the 43rd Symposium on Foundations of Computer Science (FOCS 2002), 16–19 November 2002, Vancouver, pp. 520–529. IEEE Computer Society (2002). https://doi.org/10.1109/SFCS.2002.1181976
Regev, O., Stephens-Davidowitz, N.: A reverse minkowski theorem. In: Hatami, H., McKenzie, P., King, V. (eds.) Proceedings of the 49th Annual ACM SIGACT Symposium on Theory of Computing (STOC 2017), Montreal, 19–23 June 2017, pp. 941–953. ACM (2017). https://doi.org/10.1145/3055399.3055434
Shor, P.W.: Algorithms for quantum computation: discrete logarithms and factoring. In: 35th Annual Symposium on Foundations of Computer Science, Santa Fe, 20–22 November 1994, pp. 124–134. IEEE Computer Society (1994). https://doi.org/10.1109/SFCS.1994.365700
Sikiric, M.D., Schürmann, A., Vallentin, F.: Complexity and algorithms for computing voronoi cells of lattices. Math. Comput. 78(267), 1713–1731 (2009). https://doi.org/10.1090/S0025-5718-09-02224-8
Stephens-Davidowitz, N.: Search-to-decision reductions for lattice problems with approximation factors (slightly) greater than one. In: Jansen, K., Mathieu, C., Rolim, J.D.P., Umans, C. (eds.) Approximation, Randomization, and Combinatorial Optimization. Algorithms and Techniques, APPROX/RANDOM 2016, 7–9 September 2016, Paris. LIPIcs, vol. 60, pp. 19:1–19:18. Schloss Dagstuhl - Leibniz-Zentrum für Informatik (2016). https://doi.org/10.4230/LIPIcs.APPROX-RANDOM.2016.19
Stewart, G.W.: The efficient generation of random orthogonal matrices with an application to condition estimators. SIAM J. Numer. Anal. 17(3), 403–409 (1980)
Szydlo, M.: Hypercubic lattice reduction and analysis of GGH and NTRU signatures. In: Biham, E. (ed.) EUROCRYPT 2003. LNCS, vol. 2656, pp. 433–448. Springer, Heidelberg (2003). https://doi.org/10.1007/3-540-39200-9_27
Wei, W., Liu, M., Wang, X.: Finding shortest lattice vectors in the presence of gaps. In: Nyberg, K. (ed.) CT-RSA 2015. LNCS, vol. 9048, pp. 239–257. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-16715-2_13
Acknowledgments
We thank the anonymous reviewers from ASIACRYPT 2023 for the valuable comments. We thank Yilei Chen, Ji Luo, Shihe Ma and Shuoxun Xu for helpful conversations. This work is supported by the National Key R &D Program of China (2018YFA0704701, 2020YFA0309705), Shandong Key Research and Development Program (2020ZLYS09), the Major Scientific and Technological Innovation Project of Shandong, China (2019JZZY010133), the Major Program of Guangdong Basic and Applied Research (2019B030302008), the Mathematical Tianyuan Fund of the National Natural Science Foundation of China (12226006) and the National Natural Science Foundation of China (62102216) and Tsinghua University Dushi Program.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Appendices
Appendix A Proof of the Toy Example
With respect to the oracle \(\mathcal {O}\), the rotated square is determined by the angle \(\theta \) between the line connecting its vertex on the first quadrant to the origin O and the positive direction of the x-axis. Denoted the rotated square by \(\square _{\theta },\theta \in [0,\frac{\pi }{2})\). Note we can regard \(\theta \) as functional of \(\rho \), and write \(\theta [\rho ]=\theta [\rho +\frac{\pi }{2}]\). We’ll show that,
Proof
For any \(i\in \mathbb {Z}/4\mathbb {Z}\), \(\text {Pr}_{\rho \leftarrow G}[\rho ^{-1}\mathcal {O}(\square _{\theta [\rho ]})=i]\) is a functional about \(\rho \) which is a distribution on \(G=\mathbb {R}/2\pi \mathbb {Z}\). Then we have
This means \(\forall i\in \mathbb {Z}/4\mathbb {Z},\,\text {Pr}_{\rho \leftarrow G}[\rho ^{-1}\mathcal {O}(\square _{\theta [\rho ]})=i]=\frac{1}{4}.\) \(\square \)
Appendix B Proof of the Property of the Characteristic Vectors
Lemma 2.6. Assume \(\textbf{B}=(\textbf{b}_1,...,\textbf{b}_n)\) is a basis of \(\mathcal {L}\) and \(\textbf{B}^{-\top } = (\textbf{d}_1,...,\textbf{d}_n)\), then it has:
-
1)
\(\textbf{w}=\sum _{i=1}^n\left\| \textbf{d}_i\right\| ^2 \textbf{b}_i\) is a characteristic vector of \(\mathcal {L}\).
-
2)
\(\chi (\mathcal {L}) = \textbf{w}+2\mathcal {L}\) for any characteristic vector \(\textbf{w} \in \chi (\mathcal {L})\).
-
3)
\(\textbf{w}\) is a characteristic vector if and only if \(\langle \textbf{w}, \textbf{b}_i \rangle \equiv \langle \textbf{b}_i, \textbf{b}_i \rangle \mod 2 \) for \(i\in [n]\).
Proof
-
1)
Let \(\textbf{v}=\sum _{i=1}^{n} v_i \textbf{d}_i \in \mathcal {L}(\textbf{B})\), then \(\langle \textbf{w},\textbf{v}\rangle =\langle \sum _{i=1}^n\left\| \textbf{d}_i\right\| ^2 \textbf{b}_i, \sum _{i=1}^{n} v_i \textbf{d}_i \rangle \) \(= \sum _{i=1}^{n}v_i \left\| \textbf{d}_i\right\| ^2 \equiv \sum _{i=1}^{n}v^2_i\left\| \textbf{d}_i\right\| ^2 \equiv \langle \textbf{v},\textbf{v}\rangle \text { mod } 2\), we used \(v_i\equiv v^2_i \text { mod } 2\). Thus \(\textbf{w}\) is a characteristic vector.
-
2)
Assume \(\textbf{w}\) is a characteristic vector of \(\mathcal {L}\), then for any \(\textbf{x} \in \mathcal {L}\), \(\textbf{w}+2\textbf{x}\) is also a characteristic vector of \(\mathcal {L}\), because \(\langle \textbf{w}+2\textbf{x}, \textbf{v} \rangle = \langle \textbf{w},\textbf{v} \rangle + 2\langle \textbf{x}, \textbf{v} \rangle \equiv \langle \textbf{w},\textbf{v} \rangle \equiv \langle \textbf{v},\textbf{v} \rangle \text { mod } 2\). On the other hand, if \(\textbf{w}'=\sum _{i=1}^{n} a_i \textbf{b}_i \in \chi (\mathcal {L})\), then \(a_i=\langle \textbf{w}',\textbf{d}_i \rangle \equiv \langle \textbf{d}_i,\textbf{d}_i \rangle = \left\| \textbf{d}_i\right\| ^2 \text { mod } 2\), thus for any \(i \in [n]\), \(a_i \equiv \left\| \textbf{d}_i\right\| ^2 \text { mod } 2\) and we know \(\textbf{w}=\sum _{i=1}^n\left\| \textbf{d}_i\right\| ^2 \textbf{b}_i\in \chi (\mathcal {L})\), thus \(\textbf{w}'=\textbf{w}+2\mathcal {L}\). Thus \(\chi (\mathcal {L})\) is a coset of \(\textbf{w}+2\mathcal {L}\), where \(\textbf{w}\) is any element in \(\chi (\mathcal {L})\).
-
3)
Obviously, if \(\textbf{w}\in \chi (\mathcal {L})\), \(\forall \, i\in [n],\, \langle \textbf{w}, \textbf{b}_i \rangle \equiv \langle \textbf{b}_i, \textbf{b}_i \rangle \text { mod } 2 \). On the other hand, if \(\textbf{w}\in \mathcal {L}\) satisfying \(\forall \, i\in [n],\, \langle \textbf{w}, \textbf{b}_i \rangle \equiv \langle \textbf{b}_i, \textbf{b}_i \rangle \text { mod } 2 \). Then for any \(\textbf{v}=\sum ^{n}_{i=1} v_i \textbf{b}_i \in \mathcal {L}\), without loss of generality, assume \(v_i \equiv 1 \text { mod } 2\) for \(1 \le i \le k\), and \(v_i \equiv 0 \text { mod } 2\) for \(k+1 \le i \le n\). Thus we have \(\langle \textbf{w}, \textbf{v} \rangle \equiv \langle \textbf{w}, \textbf{b}_1+\ldots + \textbf{b}_k \rangle \equiv \sum _{i=1}^{k}\langle \textbf{w}, \textbf{b}_i \rangle \equiv \sum _{i=1}^{k} \langle \textbf{b}_i, \textbf{b}_i \rangle \equiv \langle \textbf{v}, \textbf{v} \rangle \text { mod } 2 \). \(\square \)
Lemma 2.7. Suppose \(\mathcal {L} \cong \mathbb {Z}^n \). Assume \(\textbf{B}=\textbf{O}\textbf{U}\) is a basis of \(\mathcal {L}\), where \(\textbf{O}\in {O}_n(\mathbb {R})\) and \(\textbf{U}\in GL_n(\mathbb {Z}^n)\). Then it has:
-
1)
\(\chi (\mathcal {L}) =\{\textbf{O}\textbf{z} : \textbf{z}\in \mathbb {Z}^n \text { such that } \textbf{z}_i \equiv 1 \mod 2, \forall i \in [n] \}\).
-
2)
The shortest characteristic vectors are exactly \(\{\textbf{O}\textbf{z} : \textbf{z}_i=\pm 1, \forall i \in [n] \}\).
Proof
-
1)
Let \(\textbf{O}=(\textbf{v}_1,\ldots ,\textbf{v}_n)\) and \(\textbf{w}=\textbf{B}(\textbf{U}^{-1}\textbf{z})=\textbf{O}\textbf{z}\), where \(\textbf{z}\in \mathbb {Z}^n\) is the vector that \(\forall i\in [n],\, z_i=1\). Note that \(\mathcal {L}=\textbf{O}\cdot \mathbb {Z}^n\). Thus assume \(\textbf{v}=\sum _{i=1}^{n}a_i\textbf{v}_i\), then \(\langle \textbf{w},\textbf{v}\rangle =\sum _{i=1}^{n}a_iz_i\equiv \sum _{i=1}^{n}a^2_i=\langle \textbf{v},\textbf{v}\rangle \text { mod } 2\), where we used \(a^2_i\equiv a_i\text { mod } 2\) and \(z_i\equiv 1 \text { mod } 2\). Thus \(\textbf{w}\in \chi (\mathcal {L})\), so \(\chi (\mathcal {L}) =\{\textbf{O}\textbf{z} : \textbf{z}\in \mathbb {Z}^n \text { such that } \textbf{z}_i \equiv 1 \mod 2, \forall i \in [n] \}\).
-
2)
Note that \(\textbf{O}\) is an orthogonal matrix, thus the shortest characteristic vectors are \(\{\textbf{O}\textbf{z} : \textbf{z}_i=\pm 1, \, \forall \,i \in [n] \}\) by 1). \(\square \)
Appendix C Proof of Lemma 4.6
Proof
Let \(\mathcal {D}\) be the set of \(n \times n\) diagonal matrices whose diagonal entries are \(\pm 1\). Then \(\mathcal {D}\) forms a subgroup of \(\mathcal {S}^{\pm }_n\), and \(\mathcal {S}^{\pm }_n\) is the semidirect product of \(\mathcal {D}\) and \(\mathcal {S}_n\).Footnote 6 For \(\phi _0 \in {{\text {Aut}}(\mathcal {L})}\) and \(\phi _0 \sim \textbf{T}_{k_1,k_2,l}\), let \(\textbf{O} \in \mathcal {O}_n(\mathbb {R})\) such that \(\mathcal {L} = \textbf{O} \mathbb {Z}^n \), then it has \(\mathfrak {C}_{\phi _0} = \{ \textbf{O} \textbf{T} \textbf{T}_{k_1,k_2,l} \textbf{T} ^{-1} \textbf{O} ^{-1} : \textbf{T} \in \mathcal {S}^{\pm }_n \}\). Denote \(\textbf{y} = \textbf{O} ^{-1} \textbf{x} = (x_1,\cdots ,x_n)\).Footnote 7
For \(k = 1\), it has
Denote \(\textbf{W}_{k_1,k_2,l} = {\text {diag}} \{\textbf{0} _{2l}, -\textbf{I}_{k_1}, \textbf{I}_{k_2}\}\), where \(\textbf{0} _{2l}\) is the \(2l \times 2l\) zero matrix. Then it has \(\sum _{D \in \mathcal {D}} \textbf{D} \textbf{T}_{k_1,k_2,l} \textbf{D} ^{-1} = |\mathcal {D}| \cdot \textbf{W}_{k_1,k_2,l}\), and thus
where \(\textbf{P} (i)\) represents the row number of the ‘1’ in \(\textbf{P} \)’s i-th column.
For \(k = 2\), it has
For fixed \(\textbf{P} \in \mathcal {S}_n\) and \(\textbf{D} \in \mathcal {D}\), denote \(\textbf{z} = \textbf{P} ^{-1}y = (z_1,\cdots , z_n)\) and \(\textbf{D} = \textbf{D} ^{-1} = {\text {diag}} \{d_1,\cdots ,d_n\}\), where \(d_i = \pm 1\). Then it has
and \({\langle \textbf{D} \textbf{T}_{k_1,k_2,l} \textbf{D} ^{-1} \textbf{z}, \textbf{z} \rangle } =\sum _{i=1}^l 2d_{2i-1}d_{2i}z_{2i-1}z_{2i} - \sum _{i=2l+1}^{2l+k_1}z_i^2 + \sum _{i=2l+k_1+1}^n z_i^2\). It follows that
Observe that \(z_i = x_{\textbf{P} (i)}\) for \(1 \le i \le n\), then it can be deduced that
\(\square \)
Appendix D Recover the Exact Shortest Vectors in Proposition 4.2
In this appendix, we demonstrate how to recover the exact shortest vectors by using good enough approximations of the shortest vectors of \(\mathcal {L}\) and automorphisms of \({{\text {Aut}}(\mathcal {L})}\), thereby completing Proposition 4.2. In fact, this can be reduced to the following problem.
Problem D.1
Suppose n is odd. Given a basis \(\textbf{B}\) of a lattice \(\mathcal {L} \cong \mathbb {Z}^n\), a polynomial number of automorphisms \(\phi _1,\phi _2,\ldots ,\phi _{p(n)} \in {{\text {Aut}}(\mathcal {L})}\) that are drawn uniformly and independently from a conjugacy class \(\mathfrak {C}_{\phi _0}\), where \(\phi _0 \sim \textbf{T}_{k_1,k_2,l}\) and \(k_1,k_2,l\) are fixed, and an approximation of a set of independent shortest vectors \(\textbf{v}_i\), i.e., \(\{\tilde{\textbf{v}}_1,\ldots ,\tilde{\textbf{v}}_n\}\) such that \(\tilde{\textbf{v}}_i=\textbf{v}_i+\boldsymbol{\epsilon }_i\) and \(\left\| \boldsymbol{\epsilon }_i\right\| \le n^{-c}\). The goal is to find the shortest vectors of \(\mathcal {L}\), i.e., \(\textbf{V}=\{{\textbf{v}}_1,\ldots ,{\textbf{v}}_n\}\).
Note that for any \(\phi \in \mathfrak {C}_{\phi _0}\), it has \(\phi =\textbf{V}\textbf{S}\textbf{V}^{-1}\), where \(\textbf{S} \in {\mathcal {S}^{\pm }_n}\) and \(\textbf{S} \sim \textbf{T}_{k_1,k_2,l}\) (i.e., \(\exists \textbf{T} \in {\mathcal {S}^{\pm }_n}\) such that \(\textbf{S} = \textbf{T}\textbf{T}_{k_1,k_2,l}\textbf{T}^{-1}\)), and \(\phi \) acts on the set of shortest vectors \(\{\pm \textbf{v} _1, \dots , \pm \textbf{v} _n\}\). Then for \(1 \le i,j \le n\), it has \(\left\| \phi \textbf{v}_i \pm \textbf{v}_j\right\| = 0\) or 2 and
Thus, for any given \(\phi \in \mathfrak {C}_{\phi _0}\), we can decide whether \(\left\| \phi \textbf{v}_i \pm \textbf{v}_j\right\| = 0\), and thus exactly recover the corresponding matrix \(\textbf{S} \in {\mathcal {S}^{\pm }_n}\).
Next, we demonstrate that, for the given automorphisms \(\phi _1,\phi _2,\ldots ,\phi _{p(n)} \in \mathfrak {C}_{\phi _0}\) and the corresponding matrices \(\textbf{S}_i \in {\mathcal {S}^{\pm }_n}, 1 \le i \le p(n)\), such that \(\phi _i=\textbf{V}\textbf{S}_i\textbf{V}^{-1}\), we can efficiently recover \(\textbf{V}\). For \(\phi , \textbf{S} \in \mathbb {R}^{n \times n}\), define \(K{(\phi ,{\textbf {S}})}:=\{{\textbf {X}} \in \mathbb {R}^{n \times n}:{\textbf {XS}}{} {\textbf {X}}^{-1}=\phi \}\). Then clearly, \(K{(\phi ,{\textbf {S}})}\) is an \(\mathbb {R}\)-linear space, and \(\textbf{V} \in K{(\phi _i,{\textbf {S}}_i)}\). Moreover,
Therefore, \(\textbf{V} \in {\textbf {V}}\cdot \bigcap _{i=1}^{p(n)} K{({\textbf {S}}_i,{\textbf {S}}_i)}\). Note that \(K{({\textbf {S}}_i,{\textbf {S}}_i)}\) is a subgroup of \(\mathcal {S}^{\pm }_n\). Let \(\textbf{T}_i \in {\mathcal {S}^{\pm }_n}\) such that \(\textbf{S}_i = \textbf{T}_i\textbf{T}_{k_1,k_2,l}\textbf{T}_i^{-1}\). Then it has
Since \(\phi _i\) is drawn uniformly from the conjugacy class \(\mathfrak {C}_{\phi _0}\), then \(\textbf{S}_i\) is distributed uniformly in the conjugacy class \(\mathfrak {C}_{\textbf{T}_{k_1,k_2,l}}\). Then from the group action perspective, the coset \(\textbf{T}_i K{(\textbf{T}_{k_1,k_2,l},\textbf{T}_{k_1,k_2,l})}\) is distributed uniformly in the left cosets of \(\textbf{T}_{k_1,k_2,l}\) in \(\mathcal {S}^{\pm }_n\). Equivalently, \(K{({\textbf {S}}_i,{\textbf {S}}_i)} = \textbf{T}_i K{(\textbf{T}_{k_1,k_2,l},\textbf{T}_{k_1,k_2,l})} \textbf{T}_i^{-1}\) can be viewed as a random subgroup of \(\mathcal {S}^{\pm }_n\) such that \(\textbf{T}_i\) is drawn uniformly at random from \(\mathcal {S}^{\pm }_n\). There are two cases for \(\textbf{T}_{k_1,k_2,l}\).
Case 1. \(l = 0\). In this case, it has \(k_1,k_2 > 0\), and thus there exists \(1 \le a \ne b \le n\) such that \(\textbf{T}_{k_1,k_2,l} \textbf{e} _a = \textbf{e} _a\) and \(\textbf{T}_{k_1,k_2,l} \textbf{e} _b = -\textbf{e} _b\) (we recall that \(\{\textbf{e} _a\}_{a \in [n]}\) is the standard basis). Thus, for an \(\textbf{X} \in K{(\textbf{T}_{k_1,k_2,l},\textbf{T}_{k_1,k_2,l})}\), we have \(\textbf{e} _a^\top \textbf{X} \textbf{e} _b = - \textbf{e} _a^\top \textbf{X} \textbf{T}_{k_1,k_2,l} \textbf{e} _b = - \textbf{e} _a^\top \textbf{T}_{k_1,k_2,l} \textbf{X} \textbf{e} _b = - \textbf{e} _a^\top \textbf{X} \textbf{e} _b \), i.e., \(\textbf{e} _a^\top \textbf{X} \textbf{e} _b = 0\). Similarly, it can be deduced that \(\textbf{e} _b^\top \textbf{X} \textbf{e} _a = 0\).
Therefore, for any \(\textbf{Y} \in K{({\textbf {S}}_i,{\textbf {S}}_i)}\), we have \(\textbf{T}_i^\top \textbf{Y} \textbf{T}_i \in K{(\textbf{T}_{k_1,k_2,l},\textbf{T}_{k_1,k_2,l})}\). It follows that \((\textbf{T}_i \textbf{e} _a)^\top \textbf{Y} (\textbf{T}_i \textbf{e} _b) = (\textbf{T}_i \textbf{e} _b)^\top \textbf{Y} (\textbf{T}_i \textbf{e} _a) = 0\). Note that \(\textbf{T}_i\) can be viewed as drawn uniformly at random from \(\mathcal {S}^{\pm }_n\), and \(\mathcal {S}^{\pm }_n\) acts transitively on all the pairs \(\{(\pm \textbf{e} _a, \pm \textbf{e} _b): 1 \le a \ne b \le n\}\). Thus, for a sufficiently large polynomial p(n), it has \(\textbf{e} _a^\top \textbf{Y} \textbf{e} _b = \textbf{e} _b^\top \textbf{Y} \textbf{e} _a = 0\) for all \(1 \le a \ne b \le n\) and \(\textbf{Y} \in \bigcap _{i=1}^{p(n)} K{({\textbf {S}}_i,{\textbf {S}}_i)}\). In other words, \(\bigcap _{i=1}^{p(n)} K{({\textbf {S}}_i,{\textbf {S}}_i)}\) consists of all diagonal matrices in \(\mathbb {R}^{n \times n}\), i.e., \(\bigcap _{i=1}^{p(n)} K{(\phi _i,{\textbf {S}}_i)} = \{ \textbf{V} \cdot {\text {diag}}\{d_1, \dots , d_n\} : d_i \in \mathbb {R} \}\). Then \(\textbf{V}\) can be reconstructed by first computing an \(\mathbb {R}\)-linear basis of the space \(\bigcap _{i=1}^{p(n)} K{(\phi _i,{\textbf {S}}_i)}\) and then recovering each \(\pm \textbf{v} _i\) via vector normalization.
Case 2: \(l \ne 0\). In this case, it has \(k_1 \ne 0\) (or \(k_2 \ne 0\)). Thus we have \(\textbf{T}_{k_1,k_2,l} \textbf{e} _1 = \textbf{e} _2\), \(\textbf{T}_{k_1,k_2,l} \textbf{e} _2 = \textbf{e} _1\), and there exists \(3 \le j \le n\) such that \(\textbf{T}_{k_1,k_2,l} \textbf{e} _j = -\textbf{e} _j\) (or \(\textbf{T}_{k_1,k_2,l} \textbf{e} _j = \textbf{e} _j\) if \(k_2 \ne 0\)). Then, by a similar deduction as in Case 1, we have \(\textbf{e} _1^\top \textbf{X} \textbf{e} _1 = \textbf{e} _2^\top \textbf{X} \textbf{e} _2\), \(\textbf{e} _1^\top \textbf{X} \textbf{e} _2 = \textbf{e} _2^\top \textbf{X} \textbf{e} _1\), and \(\textbf{e} _1^\top \textbf{X} \textbf{e} _j = -\textbf{e} _2^\top \textbf{X} \textbf{e} _j\) (or \(\textbf{e} _1^\top \textbf{X} \textbf{e} _j = \textbf{e} _2^\top \textbf{X} \textbf{e} _j\) if \(k_2 \ne 0\)) for all \(j \in [n]\) and \(\textbf{X} \in K{(\textbf{T}_{k_1,k_2,l},\textbf{T}_{k_1,k_2,l})}\).
Again, due to the transitivity of the action of \(\mathcal {S}^{\pm }_n\) on \(\{(\pm \textbf{e} _a, \pm \textbf{e} _b, \pm \textbf{e} _c)\}\), we can deduce that for a large enough polynomial p(n), it has \(\textbf{e} _a^\top \textbf{Y} \textbf{e} _a = \textbf{e} _b^\top \textbf{Y} \textbf{e} _b\), \(\textbf{e} _a^\top \textbf{Y} \textbf{e} _b = \textbf{e} _b^\top \textbf{Y} \textbf{e} _a\), and \(\textbf{e} _a^\top \textbf{Y} \textbf{e} _c = -\textbf{e} _b^\top \textbf{Y} \textbf{e} _c\), \(\textbf{e} _a^\top \textbf{Y} \textbf{e} _c = \textbf{e} _b^\top \textbf{Y} \textbf{e} _c\) for all \(1 \le a \ne b \ne c \le n\) and \(\textbf{Y} \in \bigcap _{i=1}^{p(n)} K{({\textbf {S}}_i,{\textbf {S}}_i)}\). In other words, \(\bigcap _{i=1}^{p(n)} K{({\textbf {S}}_i,{\textbf {S}}_i)} = \{h\textbf{I}_n: h\in \mathbb {R}\}\). Then \(\textbf{V}\) can be reconstructed by first computing a nonzero matrix in \(\bigcap _{i=1}^{p(n)} K{(\phi _i,{\textbf {S}}_i)}\) and then performing normalization.
Rights and permissions
Copyright information
© 2023 International Association for Cryptologic Research
About this paper

Cite this paper
Jiang, K., Wang, A., Luo, H., Liu, G., Yu, Y., Wang, X. (2023). Exploiting the Symmetry of \(\mathbb {Z}^n\): Randomization and the Automorphism Problem. In: Guo, J., Steinfeld, R. (eds) Advances in Cryptology – ASIACRYPT 2023. ASIACRYPT 2023. Lecture Notes in Computer Science, vol 14441. Springer, Singapore. https://doi.org/10.1007/978-981-99-8730-6_6
Download citation
DOI: https://doi.org/10.1007/978-981-99-8730-6_6
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-99-8729-0
Online ISBN: 978-981-99-8730-6
eBook Packages: Computer ScienceComputer Science (R0)