
Abstract
White [6–8] has theoretically shown that learning procedures used in network training are inherently statistical in nature. This paper takes a small but pioneering experimental step towards learning about this statistical behaviour by showing that the results obtained are completely in line with White's theory. We show that, given two random vectorsX (input) andY (target), which follow a two-dimensional standard normal distribution, and fixed network complexity, the network's fitting ability definitely improves with increasing correlation coefficient rXY (0≤rXY≤1) betweenX andY. We also provide numerical examples which support that both increasing the network complexity and training for much longer do improve the network's performance. However, as we clearly demonstrate, these improvements are far from dramatic, except in the case rXY=+ 1. This is mainly due to the existence of a theoretical lower bound to the inherent conditional variance, as we both analytically and numerically show. Finally, the fitting ability of the network for a test set is illustrated with an example.
Similar content being viewed by others

Abbreviations
- X :
-
Generalr-dimensional random vector. In this work it is a one-dimensional normal vector and represents the input vector
- Y :
-
Generalp-dimensional random vector. In this work it is a one-dimensional normal vector and represents the target vector
- Z :
-
Generalr+p dimensional random vector. In this work it is a two-dimensional normal vector
- E :
-
Expectation operator (Lebesgue integral)
- g(X)=E(Y¦X):
-
Conditional expectation
- ε:
-
Experimental random error (defined by Eq. (2.1))
- y :
-
Realized target value
- o :
-
Output value
- f :
-
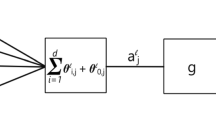
Network's output function. It is formally expressed asf: R r×W→R p, whereW is the appropriate weight space
- λ:
-
Average (or expected) performance function. It is defined by Eq. (2.2) as λ(w)=E[π(Yf(X,w)],w εW
- π:
-
Network's performance
- w * :
-
Weight vector for optimal solution. That is, the objective of network is such that λ(w *) is minimum
- C 1 :
-
Component one
- C 2 :
-
Component two
- Z :
-
Matrix of realised values of the random vectorZ overn observations
- Z t :
-
Transformed matrix version ofZ in such a way thatX andY have values in [0,1]
- X t ,Y t :
-
Transformed versions ofX andY and both are standard one-dimensional normal vectors
- n h :
-
Number of hidden nodes (neurons)
- r XY :
-
Correlation coefficient between eitherX andY orX t andY t
- λ s and λ k in Eq. (3.1) and afterwards:
-
λ s is average value of 100 differentZ t matrices. λ k is the error function ofkthZ t , matrix. In Eq. (3.1), the summation is fromk=1 to 100, and in Eq. (3.2) fromi=1 ton. In Eq. (3.2)o ki andy ki are the output and target values for the kthZ t matrix and ith observation, respectively
- λ1/2(w *) and λ k (wn):
-
λk(wn) is the sample analogue of λ1/2(w *)
- σY 2 :
-
In Eq. (4.1) and afterwards, σY 2 is the variance ofY
- σY 2 :
-
variance ofY t . In Sect. 4.3 the transformation isY t=a Y+b
- Y max,Y min :
-
the maximum and minimum values ofY
- R :
-
Correlation matrix ofX andY
- ⌆:
-
Covariance matrix ofX andY
- ∃:
-
Membership symbol in set theory
References
Hornik K, Stinhcombe M, White H. Multilayer Feedforward Networks are University Approximators. Neural Networks 1989; 2: 359–368
Golden R. A Unified Framework for Connectionist Systems. Biological Cybernetics 1988; 59: 109–120
Barron A. Statistical Properties of Artificial Neural Networks. In: Proceedings of 28th IEEE Conference on Decision and Control, Tampa, FL. New York, IEEE Press 1989: 280–285
Tisby N, Levin E, Solla S. Consistent Inference of Probabilities in Layered Networks: Prediction and Generalization. In: Proceedings of the International Joint Conference on Neural Networks, Washington, DC. New York, IEEE Press 1989: Vol II; 403–408
Mielnizcuk J, Tyrcha J. Consistency of Multilayer Perceptron Regression Estimators. Neural Networks 1993; 6: 1019–1022
White H. Learning in Artificial Neural Networks: A Statistical Perspective. Neural Computation 1989, 1: 425–464
White H. Some Asymptotic Results in a Single Hidden Layer Feedforward Network Models. Journal of American Statistical Association 1989; 84: 1003–1013
White H. Connectionist Nonparametric Regression: Multilayer Feedforward Networks can Learn Arbitrary Mappings. Neural Networks 1990; 3: 535–549
Salt DW, Yildiz N, Livingstone DJ, Tinsley CJ. The Use of Artificial Neural Networks in QSAR. Pestic Sci 1992; 36: 161–170
Minai AA, Williams RD. Acceleration of Back Propagation through Learning Rate and Momentum Adaptation. In: Proceedings of the International Joint Conference on Neural Networks 1990; 1: 676–679
Yildiz N. A Comparison of the Performances of Two Different Type of Feedforward Neural Networks in a Stochastic Environment. Turkish Doga Journal of Engineering and Environmental Sciences 1995; 19: 199–203
Yildiz N. An Investigation of Performance of the Back-Propagation Type Neural Networks in a Stochastic Environment. Unpublished Mphil Thesis, School of Mathematical Studies, University of Portsmouth, UK, 1993
Author information
Authors and Affiliations
Rights and permissions
About this article
Cite this article
Yildiz, N. Correlation structure of training data and the fitting ability of back propagation networks: Some experimental results. Neural Comput & Applic 5, 14–19 (1997). https://doi.org/10.1007/BF01414099
Issue Date:
DOI: https://doi.org/10.1007/BF01414099