
Abstract
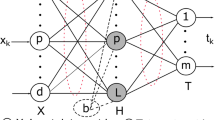
This paper discusses learning algorithms of layered neural networks from the standpoint of maximum likelihood estimation. At first we discuss learning algorithms for the most simple network with only one neuron. It is shown that Fisher information of the network, namely minus expected values of Hessian matrix, is given by a weighted covariance matrix of input vectors. A learning algorithm is presented on the basis of Fisher's scoring method which makes use of Fisher information instead of Hessian matrix in Newton's method. The algorithm can be interpreted as iterations of weighted least squares method. Then these results are extended to the layered network with one hidden layer. Fisher information for the layered network is given by a weighted covariance matrix of inputs of the network and outputs of hidden units. Since Newton's method for maximization problems has the difficulty when minus Hessian matrix is not positive definite, we propose a learning algorithm which makes use of Fisher information matrix, which is non-negative, instead of Hessian matrix. Moreover, to reduce the computation of full Fisher information matrix, we propose another algorithm which uses only block diagonal elements of Fisher information. The algorithm is reduced to an iterative weighted least squares algorithm in which each unit estimates its own weights by a weighted least squares method. It is experimentally shown that the proposed algorithms converge with fewer iterations than error back-propagation (BP) algorithm.
Similar content being viewed by others


References
Rumelhart, D. E., Hinton, G. E., and Williams, R. J., “Learning Representations by Back-Propagating Errors,”Nature, 323–9, pp. 533–536, 1986.
Rumelhart, D. E., Hinton, G. E., and Williams, R. J., “Learning Internal Representations by Error Propagation,” inParallel Distributed Processing, Vol. 1 (McCleland, J. L., Rumelhart, D. E., and The PDP Research group, ed.), Cambridge, MA, MIT Press, 1986.
Richard, M. D. and Lippmann, R. P., “Neural Network Classifiers Estimate Bayesiana posteriori Probabilities,”Neural Computation, 3, 4, pp. 461–483, 1991.
Baum, E. B. and Wilczek, F., “Supervised Learning of Probability Distributions by Neural Networks,” inNeural Information Processing Systems (D. Anderson, ed.), American Institute of Physics, New York, pp. 52–61, 1988.
Hinton, G. E., “Connectionist Learning Procedures,”Artificial Intelligence, 40, pp. 185–234, 1989.
Bridle, J. S., “Training Stochastic Model Recognition Algorithms as Networks Can Lead to Maximum Mutual Information Estimation of Parameters,” inNeural Information Processing Systems 2 (David S. Touretzky, ed.), Morgan Kaufmann, pp. 211–217, 1990.
Gish, H., “A Probabilistic Approach to the Understanding and Training of Neural Network Classifiers,” inProc. of IEEE Conference on Acoustics Speech and Signal Processing, pp. 1361–1364, 1990.
Hampshire, J. B. and Waibel, A. H., “A Novel Objective Function for Improved Phoneme Recognition Using Time-Delay Neural Networks,”IEEE Trans. on Neural Networks, 1, 2, pp. 216–228, 1990.
Holt, M. J. J. and Semanani, S., “Convergence of Back Propagation in Neural Networks Using a Log-Likelihood Cost Function,”Electron. Lett.,26,23, 1990.
Kurita, T., “A Method to Determine the Number of Hidden Units of Three Layered Neural Networks by Information Criteria,”Trans. of IEICE Japan, J73-D-II, 11, pp. 1872–1878, 1990 (in Japanese).
Seber, G. A. F. and Wild, C. J.,Nonlinear Regression, John Wiley & Sons, 1989.
Kurita, T., “On Maximum Likelihood Estimation of Feed-Forward Neural Net Parameters,”IEICE Technical Report, NC91-36, 1991 (in Japanese).
McCullagh, P. and Nelder FRS, J. A.,Generalized Linear Models, Chapman and Hall, 1989.
Fletcher, R.,Practical Methods of Optimization, John Wiley & Sons, 1987.
Fahlman, S. E., “An Empirical Study of Learning Speed in Back-Propagation Networks,”Technical Report, CMU-CS-88-162, 1988.
Akaike, H., “A New Look at the Statistical Model Identification,”IEEE Trans. on Automatic Control, AC-91, 6, pp. 716–723, 1974.
Rissanen, J., “A Universal Prior for Integers and Estimation by Minimum Description Length,”The Annals of Statistics, 11, 2, pp. 416–431, 1983.
Rissanen, J., “Stochastic Complexity and Modeling,”The Annals of Statistics, 14, 3, pp. 1080–1100, 1986.
Fisher, R. A., “The Use of Multiple Measurements in Taxonomic Problems,”Ann. Eugenics, 7, Part II, pp. 179–188, 1936.
Author information
Authors and Affiliations
Additional information
Takio Kurita, Ph. D: He received the B. E. degree in 1981 from Nagoya Institute of Technology and the Dr. Eng. degree in 1993 from the University of Tsukuba. Since 1981, he has been with the Electrotechnical Laboratory, AIST, MITI, Japan. From 1990 to 1991 he was a visiting research scientist at Institute for Information Technology, NRC, Ottawa, Canada. His current research interests are multivariate analysis methods, neural networks and their applications to pattern recognition.
About this article
Cite this article
Kurita, T. Iterative weighted least squares algorithms for neural networks classifiers. New Gener Comput 12, 375–394 (1994). https://doi.org/10.1007/BF03037353
Received:
Revised:
Issue Date:
DOI: https://doi.org/10.1007/BF03037353