
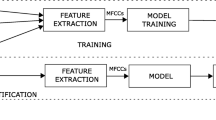
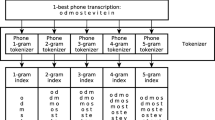
Abstract. Speech and speaker recognition systems are rapidly being deployed in real-world applications. In this paper, we discuss the details of a system and its components for indexing and retrieving multimedia content derived from broadcast news sources. The audio analysis component calls for real-time speech recognition for converting the audio to text and concurrent speaker analysis consisting of the segmentation of audio into acoustically homogeneous sections followed by speaker identification. The output of these two simultaneous processes is used to abstract statistics to automatically build indexes for text-based and speaker-based retrieval without user intervention. The real power of multimedia document processing is the possibility of Boolean queries in the form of combined text- and speaker-based user queries. Retrieval for such queries entails combining the results of individual text and speaker based searches. The underlying techniques discussed here can easily be extended to other speech-centric applications and transactions.
Similar content being viewed by others

Author information
Authors and Affiliations
Additional information
Received November 14, 1999 / Revised January 21, 2000
Rights and permissions
About this article
Cite this article
Viswanathan, M., Beigi, H., Dharanipragada, S. et al. Multimedia document retrieval using speech and speaker recognition. IJDAR 2, 147–162 (2000). https://doi.org/10.1007/PL00021522
Issue Date:
DOI: https://doi.org/10.1007/PL00021522