
Abstract
Although deep learning-based methods have greatly advanced the speech enhancement, their performance is intensively degraded under the non-Gaussian noises. To combat the problem, a correntropy-based multi-objective multi-channel speech enhancement method is proposed. First, the log-power spectra (LPS) of multi-channel noisy speech are fed to the bidirectional long short-term memory network with the aim of predicting the intermediate log ideal ratio mask (LIRM) and LPS of clean speech in each channel. Then, the intermediate LPS and LIRM features obtained from each channel are separately integrated into a single-channel LPS and a single-channel LIRM by fusion layers. Next, the two single-channel features are further fused into a single-channel LPS and finally fed to the deep neural network to predict the LPS of clean speech. During training, a multi-loss function is constructed based on correntropy with the aim of reducing the impact of outliers and improving the performance of overall network. Experimental results show that the proposed method achieves significant improvements in suppressing non-Gaussian noises and reverberations and has good robustness to different noises, signal–noise ratios and source–array distances.












Similar content being viewed by others
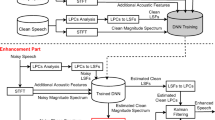

Data Availability
The datasets generated during the current study are available from the corresponding author on reasonable request.
References
S. Araki, T. Hayashi, M. Delcroix, M. Fujimoto, K. Takeda, T. Nakatani, Exploring multi-channel features for denoising-autoencoder-based speech enhancement, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, Australia (2015), pp. 116–120
J. Benesty, S. Makino, J. Chen, Speech Enhancement (Springer, Berlin, 2005)
S. Boll, Suppression of acoustic noise in speech using spectral subtraction. IEEE Trans. Acoust. Speech Signal Process. 27(2), 113–120 (1979)
I. Cohen, S. Gannot, Springer Handbook of Speech Processing (Springer, Berlin, 2008)
S. Chakrabarty, D. Wang, E.A.P. Habets, Time-frequency masking based online speech enhancement with multi-channel data using convolutional neural networks, in International Workshop on Acoustic Signal Enhancement (IWAENC) (Japan, Tokyo, 2018), pp. 476–480
S. Chakrabarty, E.A.P. Habets, Time-frequency masking based online multi-channel speech enhancement with convolutional recurrent neural networks. IEEE J. Sel. Top. Signal Process. 13(4), 787–799 (2019)
X. Cui, Z. Chen, F. Yin, Multi-objective based multi-channel speech enhancement with BiLSTM network. Appl. Acoust. 177, 107927 (2021)
L. Chen, H. Qu, J. Zhao, B. Chen, J.C. Principe, Efficient and robust deep learning with correntropy-induced loss function. Neural Comput. Appl. 27(4), 1019–1031 (2016)
F. Chollet, et al., Keras. 2015. [Online]. Available: https://github.com/fchollet/keras
Y. Ephraim, H.L. Van Trees, A signal subspace approach for speech enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 3(4), 251–266 (1995)
S. Gannot, E. Vincent, S. Markovich-Golan, A. Ozerov, A consolidated perspective on multi-microphone speech enhancement and source separation. IEEE/ACM Trans. Audio Speech Lang. Process. 25(4), 692–730 (2017)
K. Greff, R.K. Srivastava, J. Koutnk, B.R. Steunebrink, J. Schmidhuber, LSTM: a search space odyssey. IEEE Trans. Neural Netw. Learn. Syst. 28(10), 2222–2232 (2017)
A. Graves, J. Schmidhuber, Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 18(5–6), 602–610 (2005)
J.S. Garofolo, L. Lamel, W.M. Fisher, J.G. Fiscus, D.S. Pallett, N.L. Dahlgren, Darpa TIMIT acoustic-phonetic continuous speech corpus (1993). [Online]. Available: https://github.com/philipperemy/timit
E.M. Grais, D. Ward, M.D. Plumbley, Raw multi-channel audio source separation using multi-resolution convolutional auto-encoders, in European Signal Processing Conference (EUSIPCO) (Italy, Rome, 2018), pp. 1577–1581
K. Han, Y. Wang, D.L. Wang, W.S. Woods, I. Merks, T. Zhang, Learning spectral mapping for speech dereverberation and denoising. IEEE/ACM Trans. Audio Speech Lang. Process. 23(6), 982–992 (2015)
J. Heymann, L. Drude, R. Haeb-Umbach, Neural network based spectral mask estimation for acoustic beamforming, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China (2016), pp. 196–200
T. Higuchi, K. Kinoshita, N. Ito, S. Karita, T. Nakatani, Frame-by-frame closed-form update for mask-based adaptive MVDR beamforming, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, Canada (2018), pp. 531–535
S. Hochreiter, J. Schmidhuber, Long short-term memory. Neural Comput. 9(8), 1735–1780 (1997)
E.A.P. Habets, Room impulse response (RIR) generator (2016). [Online]. Available: https://github.com/ehabets/RIR-Generator
H.G. Hirsch, D. Pearce, The AURORA experimental framework for the preformance evaluations of speech recognition systems under noisy conditions, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Beijing, China (2000), pp. 181–188
ITU-T, Recommendation P.862: perceptual evaluation of speech quality (PESQ): an objective method for end-to-end speech quality assessment of narrow-band telephone networks and speech codecs. Technical Report (2001)
Y. Jiang, D. Wang, R. Liu, Z. Feng, Binaural classification for reverberant speech segregation using deep neural networks. IEEE Trans. Acoust. Speech Signal Process. 22(12), 2112–2121 (2014)
J. Jensen, C.H. Taal, An algorithm for predicting the intelligibility of speech masked by modulated noise maskers. IEEE Trans. Acoust Speech Signal Process. 24(11), 2009–2022 (2016)
J. Li, L. Deng, R. Haeb-Umbach, Y. Gong, Robust Automatic Speech Recognition: A Bridge to Practical Applications (Academic Press, New York, 2015)
P.C. Loizou, Speech Enhancement: Theory and Practice (CRC Press, Florida, 2013)
J.S. Lim, A.V. Oppenheim, Enhancement and bandwidth compression of noisy speech. Proc. IEEE 67(12), 1586–1604 (1979)
R. Li, X. Sun, T. Li, F. Zhao, A multi-objective learning speech enhancement algorithm based on IRM post-processing with joint estimation of SCNN and TCNN. Digit. Signal Process. 101, 1–11 (2020)
W. Liu, P.P. Pokharel, J.C. Principe, Correntropy: properties and applications in non-Gaussian signal processing. IEEE Trans. Signal Process. 55(11), 5286–5298 (2007)
S.T. Neely, J.B. Allen, Invertibility of a room impulse response. J. Acoust. Soc. Am. 66, 165–169 (1979)
P.P. Pokharel, W. Liu, J.C. Principe, A low complexity robust detector in impulsive noise. Signal Process. 89(10), 1902–1909 (2009)
J. Qi, H. Hu, Y. Wang, C. H. Yang, S. Marco Siniscalchi, C. Lee, Tensor-to-vector regression for multi-channel speech enhancement based on tensor-train network, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain (2020), pp. 7504–7508
Y. Qi, Y. Wang, X. Zheng, Z. Wu, Robust feature learning by stacked autoencoder with maximum correntropy criterion, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy (2014), pp. 6716–6720
C.K.A. Reddy, V. Gopal, R. Cutler, DNSMOS P.835: a non-intrusive perceptual objective speech quality metric to evaluate noise suppressors (2021). arXiv:2110.01763
C.K.A. Reddy et al., The Interspeech 2020 deep noise suppression challenge: datasets, subjective speech quality and testing framework (2020)
T. Shan, T. Kailath, Adaptive beamforming for coherent signals and interference. IEEE Trans. Acoust. Speech Signal Process. 33(3), 527–536 (1985)
X. Sun, R. Xia, J. Li, Y. Yan, A deep learning based binaural speech enhancement approach with spatial cues preservation, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, United Kingdom (2019), pp. 5766–5770
I. Santamaria, P.P. Pokharel, J.C. Principe, Generalized correlation function: definition, properties, and application to blind equalization. IEEE Trans. Signal Process. 54(6), 2187–2197 (2006)
A. Singh, J.C. Principe, A loss function for classification based on a robust similarity metric, in International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain (2010), pp. 1–6
A. Singh, R. Pokharel, J.C. Principe, The c-loss function for pattern classification. Pattern Recognit. 47(1), 441–453 (2014)
L. Sun, J. Du, L. Dai, C. Lee, Multiple-target deep learning for LSTM-RNN based speech enhancement, in Hands-Free Speech Communications and Microphone Arrays, (HSCMA), San Francisco, CA (2017), p. 136–140
I. Tashev, A. Acero, Microphone array post-processor using instantaneous direction of arrival, in International Workshop on Acoustic, Echo and Noise Control (IWAENC), Paris, France, 2006)
C.H. Taal, R.C. Hendriks, R. Heusdens, J. Jensen, A short-time objective intelligibility measure for time-frequency weighted noisy speech, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Dallas, USA (2010), pp. 4214–4217
A. Varga, H.J.M. Steeneken, Assessment for automatic speech recognition: II. NOISEX-92: a database and an experiment to study the effect of additive noise on speech recognition systems. Speech Commun. 12(3), 247–251 (1993)
D.S. Williamson, D.L. Wang, Time-frequency masking in the complex domain for speech dereverberation and denoising. IEEE/ACM Trans. Audio Speech Lang. Process. 25(7), 1492–1501 (2017)
Y. Wang, A. Narayanan, D. Wang, On training targets for supervised speech separation. IEEE Trans. Acoust. Speech Signal Process. 22(12), 1849–1858 (2014)
D. Wang, J. Chen, Supervised speech separation based on deep learning: an overview. IEEE Trans. Acoust Speech Signal Process. 26(10), 1702–1726 (2018)
X. Xiao, S. Zhao, D.L. Jones, E.S. Chng, H. Li, On time-frequency mask estimation for MVDR beamforming with application in robust speech recognition, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, USA (2017), pp. 3246–3250
T. Yoshioka, T. Nakatani, Generalization of multi-channel linear prediction methods for blind MIMO impulse response shortening. IEEE Trans. Acoust Speech Signal Process. 20(10), 2707–2720 (2012)
N. Yousefian, P.C. Loizou, A dual-microphone speech enhancement algorithm based on the coherence function. IEEE/ACM Trans. Audio Speech Lang. Process. 20(2), 599–609 (2012)
Y. Zhao, Z. Wang, D. Wang, Two-stage deep learning for noisy-reverberant speech Enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 27(1), 53–62 (2019)
X. Zhang, D. Wang, Deep learning based binaural speech separation in reverberant environments. IEEE Trans. Acoust. Speech Signal Process. 25(5), 1075–1084 (2017)
S. Zhang, X. Li, Microphone array generalization for multichannel narrowband deep speech enhancement, in Interspeech (Czech, Brno, 2021), pp. 666–670
Acknowledgements
This work was supported by the National Natural Science Foundation of China (Nos. 61771091, 61871066), National High Technology Research and Development Program (863 Program) of China (No. 2015AA016306), Natural Science Foundation of Liaoning Province of China (No. 20170540159), and Fundamental Research Funds for the Central Universities of China (Nos. DUT17LAB04).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
We declare that we do not have any commercial or associative interest that represents a conflict of interest in connection with the work submitted.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Cui, X., Chen, Z., Yin, F. et al. Correntropy-Based Multi-objective Multi-channel Speech Enhancement. Circuits Syst Signal Process 41, 4998–5025 (2022). https://doi.org/10.1007/s00034-022-02016-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00034-022-02016-4