
Abstract
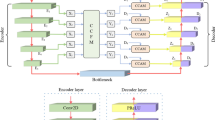
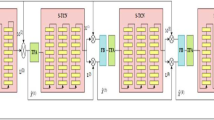
The advanced improvements in deep learning neural networks in the speech enhancement area have vastly improved. The performance of speech enhancement is still limited because widely used existing techniques cannot fully exploit contextual information from multiple scales. To address this issue, we propose a nested U-Net with efficient channel attention and D3Net (ECAD3MUNet) for speech enhancement. The proposed ECAD3MUNet is an encoder and decoder model with skip connections to improve information flow. In ECAD3MUNet, a novel densely connected dilated DenseNet (D3Net) block is incorporated with a multi-scale feature extraction block to explore large-scale contextual information. In this way, the benefits of local and global features can be completely leveraged to increase speech reconstruction abilities. D3Net uses revolutionary multi-dilated convolution with a variable dilation factor in a single layer to simulate many resolutions at the same time. D3Net improves the growth of a receptive field and the simultaneous modeling of multi-resolution data in a single convolution layer. D3Net addresses the aliasing problem that occurs when we naively include dilated convolution in the DenseNet model. Additionally, a novel cross-channel interaction can be implemented via the efficient channel attention (ECA) module without dimensionality reduction. In module testing, choosing an adaptable kernel size for the ECA improved network performance significantly. We incorporated the D3Net and ECA modules into the proposed model for better feature extraction and utterance-level context aggregation. The proposed ECAD3MUNet model experimental results outperform other baseline models in objective speech quality and intelligibility scores.







Similar content being viewed by others

Availability of data
The data that support the findings of this study are available in NOIZEUS: A noisy speech corpus for evaluation of speech enhancement algorithms. “http://ecs.utdallas.edu/loizou/speech/noizeus/”. Common Voice. “https://commonvoice.mozilla.org/en”.
References
B.J. Borgström, M.S. Brandstein, Speech enhancement via attention masking network (seamnet): An end-to-end system for joint suppression of noise and reverberation. IEEE/ACM Trans. Audio Speech Lang. Process. 29, 515–526 (2020)
D. Chen, X. Li, S. Li, A novel convolutional neural network model based on beetle antennae search optimization algorithm for computerized tomography diagnosis (IEEE Trans. Neural Netw. Learn, Syst, 2021)
CommonVoice, Mozilla (2017). https://commonvoice.mozilla.org/en
X. Duan, Y. Sun, J. Wang, Eca-unet for coronary artery segmentation and three-dimensional reconstruction. Signal Image Video Process. 1, 1–7 (2022)
A. Fuchs, R. Priewald, F. Pernkopf, Recurrent dilated densenets for a time-series segmentation task, in 18th IEEE International Conference On Machine Learning And Applications (ICMLA). IEEE, pp. 75–80 (2019)
K. He, X. Zhang, S. Ren et al., Deep residual learning for image recognition, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
T.A. Hsieh, H.M. Wang, X. Lu et al., Wavecrn: an efficient convolutional recurrent neural network for end-to-end speech enhancement. IEEE Signal Process. Lett. 27, 2149–2153 (2020)
J. Hu, L. Shen, G. Sun, Squeeze-and-excitation networks, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 7132–7141 (2018)
Y. Hu, Y. Liu, S. Lv et al., Dccrn: deep complex convolution recurrent network for phase-aware speech enhancement (2020). arXiv preprint arXiv:2008.00264
A.T. Khan, S. Li, X. Cao, Human guided cooperative robotic agents in smart home using beetle antennae search. Sci. China Inf. Sci. 65(2), 1–17 (2022)
D.P. Kingma, J. Ba, adam: A method for stochastic optimization (2014). arXiv preprint arXiv:1412.6980
S. Kumar, K. Kumar, Irsc: integrated automated review mining system using virtual machines in cloud environment, in 2018 Conference on Information and Communication Technology (CICT) (IEEE, 2018), pp 1–6
S. Kumari, M. Singh, K. Kumar, Prediction of liver disease using grouping of machine learning classifiers, in International Conference on Deep Learning, Artificial Intelligence and Robotics (Springer, 2019), pp. 339–349
Y. Lei, H. Zhu, J. Zhang et al., Meta ordinal regression forest for medical image classification with ordinal labels (2022). arXiv preprint arXiv:2203.07725
A. Li, C. Zheng, C. Fan et al., A recursive network with dynamic attention for monaural speech enhancement (2020). arXiv preprint arXiv:2003.12973
S. Li, X. Xing, W. Fan et al., Spatiotemporal and frequential cascaded attention networks for speech emotion recognition. Neurocomputing 448, 238–248 (2021)
Z. Li, S. Li, X. Luo, An overview of calibration technology of industrial robots. IEEE/CAA J. Automatica Sinica 8(1), 23–36 (2021)
Z. Li, S. Li, O.O. Bamasag et al., Diversified regularization enhanced training for effective manipulator calibration (IEEE Trans. Neural Netw. Learn, Syst, 2022)
J. Lim, A. Oppenheim, All-pole modeling of degraded speech. IEEE Trans. Acoust. Speech Signal Process. 26(3), 197–210 (1978)
Y. Lin, Q. Li, B. Yang et al., Improving speech recognition models with small samples for air traffic control systems. Neurocomputing 445, 287–297 (2021)
J.Y. Liu, Y.H. Yang, Dilated convolution with dilated gru for music source separation (2019). arXiv preprint arXiv:1906.01203
P. Loizou, Y. Hu, Noizeus: a noisy speech corpus for evaluation of speech enhancement algorithms. Speech Commun. 49, 588–601 (2017)
H. Lu, L. Jin, X. Luo et al., Rnn for solving perturbed time-varying underdetermined linear system with double bound limits on residual errors and state variables. IEEE Trans. Ind. Inf. 15(11), 5931–5942 (2019)
A. Negi, K. Kumar, N.S. Chaudhari et al., Predictive analytics for recognizing human activities using residual network and fine-tuning, in International Conference on Big Data Analytics (Springer, 2021), pp. 296–310
A. Odena, V. Dumoulin, C. Olah, Deconvolution and checkerboard artifacts. Distill 1(10), e3 (2016)
A.v.d. Oord, S. Dieleman, H. Zen et al., Wavenet. A generative model for raw audio (2016). arXiv preprint arXiv:1609.03499
A. Pandey, D. Wang, On adversarial training and loss functions for speech enhancement, in 2018 IEEE International Conference on Acoustics. Speech and Signal Processing (ICASSP) (IEEE, 2018), pp. 5414–5418
A. Pandey, D. Wang, A new framework for CNN-based speech enhancement in the time domain. IEEE/ACM Trans. Audio Speech Lang. Process. 27(7), 1179–1188 (2019)
A. Pandey, D. Wang, A new framework for CNN-based speech enhancement in the time domain. IEEE/ACM Trans. Audio Speech Lang. Process. 27(7), 1179–1188 (2019)
A. Pandey, D. Wang, Tcnn: temporal convolutional neural network for real-time speech enhancement in the time domain, in ICASSP 2019–2019 IEEE International Conference on Acoustics. Speech and Signal Processing (ICASSP) (IEEE, 2019), pp. 6875–6879
X. Qin, Z. Zhang, C. Huang et al., U2-net: going deeper with nested u-structure for salient object detection. Pattern Recogn. 106(107), 404 (2020)
Recommendation IT Perceptual evaluation of speech quality (pesq): An objective method for end-to-end speech quality assessment of narrow-band telephone networks and speech codecs. Rec ITU-T P 862 (2001)
V. Rieser, O. Lemon, S. Keizer, Natural language generation as incremental planning under uncertainty: adaptive information presentation for statistical dialogue systems. IEEE/ACM Trans. Audio Speech Lang. Process. 22(5), 979–994 (2014)
N. Roman, D. Wang, G.J. Brown, Speech segregation based on sound localization. J. Acoust. Soc. Am. 114(4), 2236–2252 (2003)
P. Sandhya, R. Bandi, D.D. Himabindu, Stock price prediction using recurrent neural network and lstm, in 2022 6th International Conference on Computing Methodologies and Communication (ICCMC) (IEEE, 2022), pp. 1723–1728
S. Sharma, K. Kumar, Asl-3dcnn: American sign language recognition technique using 3-d convolutional neural networks. Multimed. Tools Appl. 80(17), 26319–26331 (2021)
S. Sharma, S.N. Shivhare, N. Singh et al., Computationally efficient ANN model for small-scale problems, in Machine Intelligence and Signal Analysis (Springer, 2019), pp. 423–435
P.N. Srinivasu, A.K. Bhoi, R.H. Jhaveri et al., Probabilistic deep q network for real-time path planning in censorious robotic procedures using force sensors. J. Real-Time Image Proc. 18(5), 1773–1785 (2021)
P.N. Srinivasu, G. JayaLakshmi, R.H. Jhaveri et al., Ambient assistive living for monitoring the physical activity of diabetic adults through body area networks (Mobile Inf, Syst, 2022)
D. Stoller, S. Ewert, S. Dixon, Wave-u-net: a multi-scale neural network for end-to-end audio source separation (2018). arXiv preprint arXiv:1806.03185
C.H. Taal, R.C. Hendriks, R. Heusdens et al., An algorithm for intelligibility prediction of time-frequency weighted noisy speech. IEEE Trans. Audio Speech Lang. Process. 19(7), 2125–2136 (2011)
N. Takahashi, Y. Mitsufuji, Multi-scale multi-band densenets for audio source separation, in 2017 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA) (IEEE, 2017), pp. 21–25
N. Takahashi, Y. Mitsufuji, D3net: Densely connected multidilated densenet for music source separation (2020). arXiv preprint arXiv:2010.01733
K. Tan, D. Wang, A convolutional recurrent neural network for real-time speech enhancement, in Interspeech (2018), pp 3229–3233
K. Tan, D. Wang, Learning complex spectral mapping with gated convolutional recurrent networks for monaural speech enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 28, 380–390 (2019)
K. Tan, X. Zhang, D. Wang, Deep learning based real-time speech enhancement for dual-microphone mobile phones. IEEE/ACM Trans. Audio Speech Lang. Process. 29, 1853–1863 (2021)
A. Vijayvergia, K. Kumar, Star: rating of reviews by exploiting variation in emotions using transfer learning framework, in 2018 Conference on Information and Communication Technology (CICT) (IEEE, 2018), pp. 1–6
A. Vijayvergia, K. Kumar, Selective shallow models strength integration for emotion detection using glove and LSTM. Multimed. Tools Appl. 80(18), 28349–28363 (2021)
D. Wang, G.J. Brown, Computational Auditory Scene Analysis: Principles, Algorithms, and Applications (Wiley, New York, 2006)
H. Wang, T. Lin, L. Cui et al., Multitask learning-based self-attention encoding atrous convolutional neural network for remaining useful life prediction. IEEE Trans. Instrum. Meas. 71, 1–8 (2022)
Q. Wang, B. Wu, P. Zhu, et al, Supplementary material for ‘eca-net: Efficient channel attention for deep convolutional neural networks, in Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (IEEE, Seattle, WA, USA, 2020), pp. 13–19
W. Wang, C. Tang, X. Wang et al., A vit-based multiscale feature fusion approach for remote sensing image segmentation. IEEE Geosci. Rem. Sens. Lett. 19, 1–5 (2022)
Y. Wang, A. Narayanan, D. Wang, On training targets for supervised speech separation. IEEE/ACM Trans. Audio Speech Lang. Process. 22(12), 1849–1858 (2014)
P. Wen, J. Zhang, S. Zhang et al., Normalized subband spline adaptive filter: algorithm derivation and analysis. Circuits Syst. Signal Process. 40(5), 2400–2418 (2021)
P. Wen, B. Wang, S. Zhang, et al., Bias-compensated augmented complex-valued nsaf algorithm and its low-complexity implementation. Signal Process. 108812 (2022)
Y. Xian, Y. Sun, W. Wang et al., A multi-scale feature recalibration network for end-to-end single channel speech enhancement. IEEE J. Sel. Top. Signal Process. 15(1), 143–155 (2020)
X. Xiang, X. Zhang, H. Chen, A convolutional network with multi-scale and attention mechanisms for end-to-end single-channel speech enhancement. IEEE Signal Process. Lett. 28, 1455–1459 (2021)
X. Xiang, X. Zhang, H. Chen, A nested u-net with self-attention and dense connectivity for monaural speech enhancement. IEEE Signal Process. Lett. 29, 105–109 (2021)
R. Xu, R. Wu, Y. Ishiwaka et al., Listening to sounds of silence for speech denoising. Adv. Neural. Inf. Process. Syst. 33, 9633–9648 (2020)
Y. Xu, J. Du, L.R. Dai et al., A regression approach to speech enhancement based on deep neural networks. IEEE/ACM Trans. Audio Speech Lang. Process. 23(1), 7–19 (2014)
K. Yamashita, T. Shimamura, Nonstationary noise estimation using low-frequency regions for spectral subtraction. IEEE Signal Process. Lett. 12(6), 465–468 (2005)
X. Yang, J. Zhang, C. Chen et al., An efficient and lightweight CNN model with soft quantification for ship detection in SAR images. IEEE Trans. Geosci. Remote Sens. 60, 1–13 (2022)
C.H. You, S.N. Koh, S. Rahardja, An invertible frequency eigendomain transformation for masking-based subspace speech enhancement. IEEE Signal Process. Lett. 12(6), 461–464 (2005)
Q. Zhang, A. Nicolson, M. Wang et al., Deepmmse: A deep learning approach to mmse-based noise power spectral density estimation. IEEE/ACM Trans. Audio Speech Lang. Process. 28, 1404–1415 (2020)
C. Zheng, X. Peng, Y. Zhang et al., Interactive speech and noise modeling for speech enhancement, in Proceedings of the AAAI Conference on Artificial Intelligence (2021), pp. 14549–14557
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Yechuri, S., Vanambathina, S. A Nested U-Net with Efficient Channel Attention and D3Net for Speech Enhancement. Circuits Syst Signal Process 42, 4051–4071 (2023). https://doi.org/10.1007/s00034-023-02300-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00034-023-02300-x