
Abstract
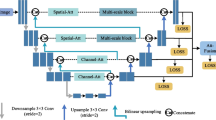
Edge detection algorithms are beneficial to the implementation of upstream tasks. The algorithms used to treat all edges equally, but edges in edge detection can be classified into four types according to the discontinuity as reflectance, illumination, normal and depth. In order to complete and improve the unified classification detection effect of edge discontinuity, we propose a robust convolutional neural network, called FPAFNet, which is the first network to use a feature pyramid structure to uniformly detect these four types of edges. Since the gap between different edge categories is very small, the design of the network should not only consider the difference between categories, but also take account of the connections between them. The proposed method integrates contextual information through a feature pyramid with an attention fusion mechanism to find associations between categories. We improve the attention module to avoid the too-close connections between categories to distinguish them. Compared with state-of-the-art methods, our method achieves the best results on average and achieves ODS of 0.511 and 0.49 in the normal edges and reflectance edges, respectively, which greatly outperforms other methods.








Similar content being viewed by others


References
Marr, D.: Vision: a computational investigation into the human representation and processing of visual information. Q. Rev. Biol. (1983). https://doi.org/10.1007/s10311-007-0116-z
Pu, M., Huang, Y., Guan, Q., Ling, H.: RINDNet: edge detection for discontinuity in reflectance, illumination, normal and depth. In: ICCV, pp. 6859–6868 (2021). https://doi.org/10.1109/ICCV48922.2021.00680
Lin, T.-Y., Dollár, P., Girshick, R., He, K., Hariharan, B., Belongie, S.: Feature pyramid networks for object detection. In: CVPR, pp. 936–944 (2017). https://doi.org/10.1109/CVPR.2017.106
Chen, L.-C., Papandreou, G., Kokkinos, I., Murphy, K., Yuille, A.L.: DeepLab: semantic image segmentation with deep convolutional nets, Atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 40(4), 834–848 (2018). https://doi.org/10.1109/TPAMI.2017.2699184
Canny, J.: A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. PAMI 8(6), 679–698 (1986). https://doi.org/10.1109/TPAMI.1986.4767851
Kittler, J.: On the accuracy of the Sobel edge detector. Image Vis. Comput. 1(1), 37–42 (1983). https://doi.org/10.1016/0262-8856(83)90006-9
Lu, Y., He, C., Yu, Y.F., Xu, G., Zhu, H., Deng, L.: Vector co-occurrence morphological edge detection for colour image. IET Image Process. 15(13), 3063–3070 (2021). https://doi.org/10.1049/ipr2.12290
Martin, D.R., Fowlkes, C.C., Malik, J.: Learning to detect natural image boundaries using local brightness, color, and texture cues. IEEE Trans. Pattern Anal. Mach. Intell. 26(5), 530–549 (2004). https://doi.org/10.1109/TPAMI.2004.1273918
Konishi, S., Yuille, A.L., Coughlan, J.M., Zhu, S.C.: Statistical edge detection: learning and evaluating edge cues. IEEE Trans. Pattern Anal. Mach. Intell. 25(1), 57–74 (2003). https://doi.org/10.1109/TPAMI.2003.1159946
Arbeláez, P., Maire, M., Fowlkes, C., Malik, J.: Contour Detection and Hierarchical Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 33(5), 898–916 (2011). https://doi.org/10.1109/TPAMI.2010.161
Lim, J.J., Zitnick, C.L., Dollár, P.: Sketch tokens: a learned mid-level representation for contour and object detection. In: CVPR, pp. 3158–3165 (2013). https://doi.org/10.1109/CVPR.2013.406
Xie, S., Tu, Z.: Holistically-nested edge detection. In: ICCV, pp. 1395–1403 (2016). https://doi.org/10.1109/ICCV.2015.164
Liu, Y., Cheng, M.-M., Hu, X., Wang, K., Bai, X.: Richer convolutional features for edge detection. In: CVPR, pp. 5872–5881 (2017). https://doi.org/10.1109/CVPR.2017.622
He, J., Zhang, S., Yang, M., Shan, Y., Huang, T.: Bi-directional cascade network for perceptual edge detection. In: CVPR, pp. 3823–3832 (2019). https://doi.org/10.1109/CVPR.2019.00395
Soria, X., Riba, E., Sappa, A.: Dense extreme inception network: towards a Robust CNN model for edge detection. In: WACV, pp. 1912–1921 (2020). https://doi.org/10.1109/WACV45572.2020.9093290
Su, Z., Liu, W., Yu, Z., Hu, D., Liao, Q., Tian, Q., Pietikäinen, M., Liu, L.: Pixel difference networks for efficient edge detection. In: ICCV, pp. 5097–5107 (2021). https://doi.org/10.1109/ICCV48922.2021.00507
Yang, F., Zhang, L., Yu, S., Prokhorov, D., Mei, X., Ling, H.: Feature pyramid and hierarchical boosting network for pavement crack detection. IEEE Trans. Intell. Transp. Syst. 21(4), 1525–1535 (2020). https://doi.org/10.1109/TITS.2019.2910595
Pu, M., Huang, Y., Liu, Y., Guan, Q., Ling, H.: EDTER: edge detection with transformer. In: CVPR (2022)
Wibisono, J., Hang, H.-M.: Fined: fast inference network for edge detection. In: ICME, pp. 1–6 (2021). https://doi.org/10.1109/ICME51207.2021.9428230
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition (2014). arXiv:1409.1556
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR, pp. 770–778 (2016). https://doi.org/10.1109/CVPR.2016.90
Chollet, F.: Xception: deep learning with depthwise separable convolutions. In: CVPR, pp. 1800–1807 (2017). https://doi.org/10.1109/CVPR.2017.195
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth \(16\times 16\) words: transformers for image recognition at scale. CoRR (2020)
Hu, Y., Chen, Y., Li, X., Feng, J.: Dynamic feature fusion for semantic edge detection. In: IJCAI, pp. 782–788 (2019). https://doi.org/10.24963/ijcai.2019/110
Yu, Z., Feng, C., Liu, M.-Y., Ramalingam, S.: Casenet: deep category-aware semantic edge detection. In: CVPR, pp. 1761–1770 (2017). https://doi.org/10.1109/CVPR.2017.191
Wang, G., Wang, X., Li, F., Liang, X.: DOOBNet: deep object occlusion boundary detection from an image. In: ACCV, pp. 686–702 (2019). https://doi.org/10.1007/978-3-030-20876-9_43
Wang, P., Yuille, A.: DOC: Deep occlusion estimation from a single image. In: ECCV, pp. 545–561 (2016). https://doi.org/10.1007/978-3-319-46448-0_33
Lu, R., Xue, F., Zhou, M., Ming, A., Zhou, Y.: Occlusion-shared and feature-separated network for occlusion relationship reasoning. In: ICCV, pp. 10342–10351 (2019). https://doi.org/10.1109/ICCV.2019.01044
Sun, M., Zhao, H., Li, J.: Road crack detection network under noise based on feature pyramid structure with feature enhancement (road crack detection under noise). IET Image Process. 16(3), 809–822 (2022). https://doi.org/10.1049/ipr2.12388
Hu, J., Shen, L., Albanie, S., Sun, G., Wu, E.: Squeeze-and-excitation networks. IEEE Trans. Pattern Anal. Mach. Intell. 42(8), 2011–2023 (2020). https://doi.org/10.1109/TPAMI.2019.2913372
Qi, L., Kuen, J., Gu, J., Lin, Z., Wang, Y., Chen, Y., Li, Y., Jia, J.: Multi-scale aligned distillation for low-resolution detection. In: CVPR, pp. 14438–14448 (2021). https://doi.org/10.1109/CVPR46437.2021.01421
Adam, P., Sam, G., Soumith, C., Gregory, C., Edward, Y., Zachary, D., Zeming, L., Alban, D., Luca, A., Adam, L.: Automatic differentiation in pytorch. In: NIPS (2017)
Chen, L.-C., Papandreou, G., Schroff, F., Adam, H.: Rethinking Atrous convolution for semantic image segmentation (2017). arXiv:1706.05587
Yang, M., Yu, K., Zhang, C., Li, Z., Yang, K.: DenseASPP for semantic segmentation in street scenes. In: CVPR, pp. 3684–3692 (2018). https://doi.org/10.1109/CVPR.2018.00388
Wang, Z., Ji, S.: Smoothed dilated convolutions for improved dense prediction. In: KDD, pp. 2486–2495 (2018). https://doi.org/10.1145/3219819.3219944
Chen, L.-C., Zhu, Y., Papandreou, G., Schroff, F., Adam, H.: Encoder-decoder with Atrous separable convolution for semantic image segmentation. In: ECCV, pp. 833–851 (2018). https://doi.org/10.1007/978-3-030-01234-2_49
Lin, T.-Y., Goyal, P., Girshick, R., He, K., Dollár, P.: Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 42(2), 318–327 (2020). https://doi.org/10.1109/TPAMI.2018.2858826
Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., Fei-Fei, L.: ImageNet: a large-scale hierarchical image database. In: CVPR, pp. 248–255 (2009). https://doi.org/10.1109/CVPR.2009.5206848
Wang, Y., Zhao, X., Huang, K.: Deep crisp boundaries. In: CVPR, pp. 1724–1732 (2017). https://doi.org/10.1109/CVPR.2017.187
Liu, S., Qi, L., Qin, H., Shi, J., Jia, J.: Path aggregation network for instance segmentation. In: CVPR, pp. 8759–8768 (2018). https://doi.org/10.1109/CVPR.2018.00913
Funding
This work was supported by the Nature Science Foundation of China [Grant No. 62071199]; the Provincial Science and Technology Innovation Special Fund Project of Jilin Province [Grant No. 20190302026GX]; and the Jilin Province Development and Reform Commission Industrial Technology Research and Development Project [Grant No. 2022C045-9].
Author information
Authors and Affiliations
Contributions
MS contributed to the formal analysis, methodology, writing—original draft and writing—review & editing. HZ was involved in the data curation, conceptualization and investigation. PL assisted in the funding acquisition, project administration, resources and supervision. JZ contributed to software and validation.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Sun, M., Zhao, H., Liu, P. et al. Feature pyramid with attention fusion for edge discontinuity classification. Machine Vision and Applications 34, 34 (2023). https://doi.org/10.1007/s00138-023-01385-3
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00138-023-01385-3