
Abstract
Learning from high dimensional data has been utilized in various applications such as computational biology, image classification, and finance. Most classical machine learning algorithms fail to give accurate predictions in high dimensional settings due to the enormous feature space. In this article, we present a novel ensemble of classification trees based on weighted random subspaces that aims to adjust the distribution of selection probabilities. In the proposed algorithm base classifiers are built on random feature subspaces in which the probability that influential features will be selected for the next subspace, is updated by incorporating grouping information based on previous classifiers through a weighting function. As an interpretation tool, we show that variable importance measures computed by the new method can identify influential features efficiently. We provide theoretical reasoning for the different elements of the proposed method, and we evaluate the usefulness of the new method based on simulation studies and real data analysis.















Similar content being viewed by others
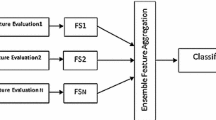
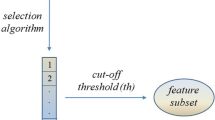
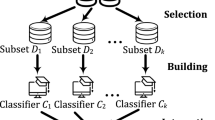
References
Ahn H, Moon H, Fazzari MJ, Lim N, Chen JJ, Kodell RL (2007) Classification by ensembles from random partitions of high-dimensional data. Comput Stat Data Anal 51(12):6166–6179. https://doi.org/10.1016/j.csda.2006.12.043
Alon U, Barkai N, Notterman DA, Gish K, Ybarra S, Mack D, Levine AJ (1999) Broad patterns of gene expression revealed by clustering analysis of tumor and normal colon tissues probed by oligonucleotide arrays. Proc Natl Acad Sci 96(12):6745–6750. https://doi.org/10.1073/pnas.96.12.6745
Amaratunga D, Cabrera J, Lee Y-S (2008) Enriched random forests. Bioinformatics 24(18):2010–2014. https://doi.org/10.1093/bioinformatics/btn356
Bay SD (1998) Combining nearest neighbor classifiers through multiple feature subsets. ICML 98:37–45
Bhattacharjee A, Richards WG, Staunton J, Li C, Monti S, Vasa P et al (2001) Classification of human lung carcinomas by mRNA expression profiling reveals distinct adenocarcinoma subclasses. Proc Natl Acad Sci 98(24):13790–13795
Blaser R, Fryzlewicz P (2016) Random rotation ensembles. J Mach Learn Res 17(1):126–151
Breiman L (1996) Bagging predictors. Mach Learn 24(2):123–140. https://doi.org/10.1007/BF00058655
Breiman L (2001) Random forests. Mach Learn 45(1):5–32. https://doi.org/10.1023/A:1010933404324
Canedo V, Marono N, Betanzos A (2015) Feature selection for high-dimensional data. Springer, Switzerland
Cannings TI, Samworth RJ (2017) Random-projection ensemble classification. J R Stat Soc Ser B (Stat Methodol) 79(4):959–1035. https://doi.org/10.1111/rssb.12228
Chipman HA, George EI, McCulloch RE (2010) Bart: Bayesian additive regression trees. Ann Appl Stat 4(1):266–298. https://doi.org/10.1214/09-AOAS285
Corsetti MA, Love TM (2022) Grafted and vanishing random subspaces. Pattern Anal Appl 25(1):89–124
Deegalla S, Walgama K, Papapetrou P, Boström H (2022) Random subspace and random projection nearest neighbor ensembles for high dimensional data. Expert Syst Appl 191:116078. https://doi.org/10.1016/j.eswa.2021.116078
Fokoué E, Elshrif M (2015) Improvement of predictive performance via random subspace learning with data driven weighting schemes. Rochester Institute of Techonology, Rochester
Freund Y, Schapire RE (1997) A decision-theoretic generalization of on-line learning and an application to boosting. J Comput Syst Sci 55(1):119–139. https://doi.org/10.1006/jcss.1997.1504
Fu G-H, Wu Y-J, Zong M-J, Pan J (2020) Hellinger distance-based stable sparse feature selection for high-dimensional class-imbalanced data. BMC Bioinform 21(1):1–14. https://doi.org/10.1186/s12859-020-3411-3
Geurts P, Ernst D, Wehenkel L (2006) Extremely randomized trees. Mach Learn 63(1):3–42. https://doi.org/10.1007/s10994-006-6226-1
Giraud C (2014) Introduction to high-dimensional statistics. Chapman and Hall/CRC, Boca Raton
Gravier E, Pierron G, Vincent-Salomon A, Gruel N, Raynal V, Savignoni A et al (2010) A prognostic DNA signature for t1t2 node-negative breast cancer patients. Genes Chromosomes Cancer 49(12):1125–1134. https://doi.org/10.1002/gcc.20820
Ho TK (1998) The random subspace method for constructing decision forests. IEEE Trans Pattern Anal Mach Intell 20(8):832–844. https://doi.org/10.1109/34.709601
Ishwaran H, Lu M (2019) Standard errors and confidence intervals for variable importance in random forest regression, classification, and survival. Stat Med 38(4):558–582. https://doi.org/10.1002/sim.7803
Ishwaran H, Kogalur UB, Blackstone EH, Lauer MS (2008) Random survival forests. Ann Appl Stat 2(3):841–860. https://doi.org/10.1214/08-AOAS169
Kyrillidis A, Zouzias A (2014) Non-uniform feature sampling for decision tree ensembles. In: 2014 IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp 4548–4552). https://doi.org/10.1109/ICASSP.2014.6854463
Lakshminarayanan B, Roy DM, Teh YW (2014) Mondrian forests: efficient online random forests. Adv Neural Inf Process Syst 27
Linero AR (2018) Bayesian regression trees for high-dimensional prediction and variable selection. J Am Stat Assoc 113(522):626–636. https://doi.org/10.1080/01621459.2016.1264957
Liu Y, Zhao H (2017) Variable importance-weighted random forests. Quant Biol 5(4):338–351. https://doi.org/10.1007/s40484-017-0121-6
Nutt CL, Mani D, Betensky RA, Tamayo P, Cairncross JG, Ladd C et al (2003) Gene expression-based classification of malignant gliomas correlates better with survival than histological classification. Cancer Res 63(7):1602–1607
Piao Y, Piao M, Jin CH, Shon HS, Chung J-M, Hwang B, Ryu KH (2015) A new ensemble method with feature space partitioning for high-dimensional data classification. Math Probl Eng. https://doi.org/10.1155/2015/590678
Ramos AL (2016) Evolutionary weights for random subspace learning. Rochester Institute of Technology, Rochester
Rodriguez JJ, Kuncheva LI, Alonso CJ (2006) Rotation forest: a new classifier ensemble method. IEEE Trans Pattern Anal Mach Intell 28(10):1619–1630. https://doi.org/10.1109/TPAMI.2006.211
Serpen G, Pathical S (2009) Classification in high-dimensional feature spaces: Random subsample ensemble. In: 2009 international conference on machine learning and applications (pp 740–745). https://doi.org/10.1109/ICMLA.2009.26
Shipp MA, Ross KN, Tamayo P, Weng AP, Kutok JL, Aguiar RC et al (2002) Diffuse large B-cell lymphoma outcome prediction by gene-expression profiling and supervised machine learning. Nat Med 8(1):68–74. https://doi.org/10.1038/nm0102-68
Simm J, De Abril IM, Sugiyama M (2014) Tree-based ensemble multi-task learning method for classification and regression. IEICE Trans Inf Syst 97(6):1677–1681. https://doi.org/10.1587/transinf.E97.D.1677
Singh D, Febbo PG, Ross K, Jackson DG, Manola J, Ladd C et al (2002) Gene expression correlates of clinical prostate cancer behavior. Cancer Cell 1(2):203–209. https://doi.org/10.1016/S1535-6108(02)00030-2
Strobl C, Boulesteix A-L, Zeileis A, Hothorn T (2007) Bias in random forest variable importance measures: illustrations, sources and a solution. BMC Bioinform 8(1):1–21. https://doi.org/10.1186/1471-2105-8-25
Sutera A, Châtel C, Louppe G, Wehenkel L, Geurts P (2018) Random subspace with trees for feature selection under memory constraints. In: International conference on artificial intelligence and statistics (pp 929–937)
Tian Y, Feng Y (2021) Rase: random subspace ensemble classification. J Mach Learn Res 22:1–45
Vapnik VN (1999) An overview of statistical learning theory. IEEE Trans Neural Netw 10(5):988–999. https://doi.org/10.1109/72.788640
Wickham H (2016) ggplot2: Elegant graphics for data analysis. Springer-Verlag, New York. Retrieved from https://ggplot2.tidyverse.org
Wright MN, Ziegler A (2017) ranger: a fast implementation of random forests for high dimensional data in C++ and R. J Stat Softw 77(1):1–17. https://doi.org/10.18637/jss.v077.i01
Xu B, Huang JZ, Williams G, Wang Q, Ye Y (2012) Classifying very high-dimensional data with random forests built from small subspaces. Int J Data Warehous Min (IJDWM) 8(2):44–63. https://doi.org/10.4018/jdwm.2012040103
Xu H, Lin T, Xie Y, Chen Z (2018) Enriching the random subspace method with margin theory—a solution for the high-dimensional classification task. Connect Sci 30(4):409–424
Yang K, Cai Z, Li J, Lin G (2006) A stable gene selection in microarray data analysis. BMC Bioinform 7(1):1–16. https://doi.org/10.1186/1471-2105-7-228
Ye Y, Wu Q, Huang JZ, Ng MK, Li X (2013) Stratified sampling for feature subspace selection in random forests for high dimensional data. Pattern Recognit 46(3):769–787. https://doi.org/10.1016/j.patcog.2012.09.005
Zhao H, Williams GJ, Huang JZ (2017) WSRF: an R package for classification with scalable weighted subspace random forests. J Stat Softw 77:1–30
Zhou Z-H (2019) Ensemble methods: foundations and algorithms. Chapman and Hall/CRC, Boca Raton
Zhu R, Zeng D, Kosorok MR (2015) Reinforcement learning trees. J Am Stat Assoc 110(512):1770–1784. https://doi.org/10.1080/01621459.2015.1036994
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Pour, N.G., Shemehsavar, S. Learning from high dimensional data based on weighted feature importance in decision tree ensembles. Comput Stat 39, 313–342 (2024). https://doi.org/10.1007/s00180-023-01347-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00180-023-01347-3