
Abstract
K-means clustering is arguably the most popular technique for partitioning data. Unfortunately, K-means suffers from the well-known problem of locally optimal solutions. Furthermore, the final partition is dependent upon the initial configuration, making the choice of starting partitions all the more important. This paper evaluates 12 procedures proposed in the literature and provides recommendations for best practices.
Similar content being viewed by others
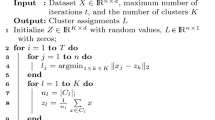

Explore related subjects
Discover the latest articles and news from researchers in related subjects, suggested using machine learning.Author information
Authors and Affiliations
Rights and permissions
About this article
Cite this article
Steinley, D., Brusco, M. Initializing K-means Batch Clustering: A Critical Evaluation of Several Techniques. Journal of Classification 24, 99–121 (2007). https://doi.org/10.1007/s00357-007-0003-0
Issue Date:
DOI: https://doi.org/10.1007/s00357-007-0003-0