
Abstract
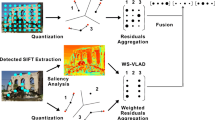
The vector of locally aggregated descriptor (VLAD) has been demonstrated to be efficient and effective in image retrieval and classification tasks. Due to the small-size codebook adopted by the method, the feature space division is coarse and the discriminative power is limited. Toward a discriminative and compact image representation for visual search, we develop a novel aggregating method to build VLAD, called two-step aggregated VLAD. Firstly, we propose the bidirectional quantization from both views of descriptors and visual words, for getting finer division of feature space. Secondly, we impose the probabilistic inverse document frequency to weight the local descriptors, for highlighting the discriminative ones. Experimental results on extensive datasets show that our method yields significant improvement and is competitive with the state-of-the-art methods.










Similar content being viewed by others


References
Arandjelovic, R., Gronat, P., Torii, A., Pajdla, T., Sivic, J.: Netvlad: CNN architecture for weakly supervised place recognition. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, pp. 5297–5307. IEEE (2016)
Arandjelović, R., Zisserman, A.: Three things everyone should know to improve object retrieval. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, pp. 2911–2918. IEEE (2012)
Arandjelovic, R., Zisserman, A.: All about VLAD. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, pp. 1578–1585. IEEE (2013)
Bay, H., Tuytelaars, T., Van Gool, L.: Surf: Speeded up robust features. In: Proceedings of European Conference on Computer Vision, pp. 404–417 (2006)
Cai, H., Wang, X., Wang, Y.: Compact and robust fisher descriptors for large-scale image retrieval. In: IEEE International Workshop on Machine Learning for Signal Processing, pp. 1–6. IEEE (2011)
Chen, D., Tsai, S., Chandrasekhar, V., Takacs, G., Chen, H., Vedantham, R., Grzeszczuk, R., Girod, B.: Residual enhanced visual vectors for on-device image matching. In: Signals, Systems and Computers, pp. 850–854. IEEE (2011)
Chisholm, E., Kolda, T.G.: New term weighting formulas for the vector space method in information retrieval. Computer Science and Mathematics Division, Oak Ridge National Laboratory (1999)
Cho, J., Heo, J.P., Kim, T., Han, B., Yoon, S.E.: Rank-based voting with inclusion relationship for accurate image search. Vis. Comput. 33, 10479–1059 (2017)
Chum, O., Matas, J.: Unsupervised discovery of co-occurrence in sparse high dimensional data. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, pp. 3416–3423. IEEE (2010)
Delhumeau, J., Gosselin, P.H., Jégou, H., Pérez, P.: Revisiting the vlad image representation. In: Proceedings of ACM international conference on Multimedia, pp. 653–656. ACM (2013)
Dong, W., Wang, Z., Charikar, M., Li, K.: High-confidence near-duplicate image detection. In: Proceedings of ACM International Conference on Multimedia Retrieval, p. 1. ACM (2012)
Everingham, M., Van Gool, L., Williams, C.K.I., Winn, J., Zisserman, A.: The PASCAL visual object classes challenge 2012 (VOC2012) results. http://www.pascal-network.org/challenges/VOC/voc2012/workshop/index.html
Gong, Y., Wang, L., Guo, R., Lazebnik, S.: Multi-scale orderless pooling of deep convolutional activation features. In: Proceedings of European Conference on Computer Vision, pp. 392–407 (2014)
Jégou, H., Chum, O.: Negative evidences and co-occurences in image retrieval: the benefit of pca and whitening. In: Proceedings of European Conference on Computer Vision, pp. 774–787 (2012)
Jegou, H., Douze, M., Schmid, C.: Hamming embedding and weak geometric consistency for large scale image search. In: Proceedings of European Conference on Computer Vision, pp. 304–317 (2008)
Jégou, H., Douze, M., Schmid, C.: On the burstiness of visual elements. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, pp. 1169–1176. IEEE (2009)
Jégou, H., Douze, M., Schmid, C., Pérez, P.: Aggregating local descriptors into a compact image representation. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, pp. 3304–3311. IEEE (2010)
Jegou, H., Perronnin, F., Douze, M., Sánchez, J., Perez, P., Schmid, C.: Aggregating local image descriptors into compact codes. IEEE Trans. Pattern Anal. Mach. Intell. 34(9), 1704–1716 (2012)
Kim, T.E., Kim, M.H.: Improving the search accuracy of the vlad through weighted aggregation of local descriptors. J. Vis. Commun. Image Represent. 31, 237–252 (2015)
Lazebnik, S., Schmid, C., Ponce, J.: Beyond bags of features: spatial pyramid matching for recognizing natural scene categories. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, vol. 2, pp. 2169–2178. IEEE (2006)
Li, H., Toyoura, M., Shimizu, K., Yang, W., Mao, X.: Retrieval of clothing images based on relevance feedback with focus on collar designs. The Visual Computer 32(10), 1–13 (2016)
Li, Y., Ye, J., Wang, T., Huang, S.: Augmenting bag-of-words: a robust contextual representation of spatiotemporal interest points for action recognition. Vis. Comput. 31(10), 1383–1394 (2015)
Liu, H., Zhao, Q., Wang, H., Lv, P., Chen, Y.: An image-based near-duplicate video retrieval and localization using improved edit distance. Multimed. Tools Appl. 76(22), 24435–24456 (2017)
Liu, Z., Li, H., Zhou, W., Rui, T., Tian, Q.: Making residual vector distribution uniform for distinctive image representation. IEEE Trans. Circuits Syst. Video Technol. 26(2), 375–384 (2016)
Liu, Z., Wang, S., Tian, Q.: Fine-residual vlad for image retrieval. Neurocomputing 173, 1183–1191 (2016)
Lowe, D.G.: Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 60(2), 91–110 (2004)
Ng, Y.H., Yang, F., Davis, L.S.: Exploiting local features from deep networks for image retrieval. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition Workshops, pp. 53–61. IEEE (2015). https://doi.org/10.1109/CVPRW.2015.7301272
Nister, D., Stewenius, H.: Scalable recognition with a vocabulary tree. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, vol. 2, pp. 2161–2168. IEEE (2006)
Paulin, M., Douze, M., Harchaoui, Z., Mairal, J., Perronin, F., Schmid, C.: Local convolutional features with unsupervised training for image retrieval. In: Proceedings of IEEE International Conference on Computer Vision, pp. 91–99. IEEE (2015)
Perronnin, F., Liu, Y., Sánchez, J., Poirier, H.: Large-scale image retrieval with compressed fisher vectors. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, pp. 3384–3391. IEEE (2010)
Perronnin, F., Sánchez, J., Mensink, T.: Improving the fisher kernel for large-scale image classification. In: Proceedings of European Conference on Computer Vision, pp. 143–156. Springer (2010)
Philbin, J., Chum, O., Isard, M., Sivic, J., Zisserman, A.: Object retrieval with large vocabularies and fast spatial matching. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, pp. 1–8. IEEE (2007)
Philbin, J., Chum, O., Isard, M., Sivic, J., Zisserman, A.: Lost in quantization: improving particular object retrieval in large scale image databases. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, pp. 1–8. IEEE (2008)
Sivic, J., Zisserman, A.: Video google: a text retrieval approach to object matching in videos. In: IEEE International Conference on Computer Vision, p. 1470. IEEE (2003)
Spyromitros-Xioufis, E., Papadopoulos, S., Kompatsiaris, I.Y., Tsoumakas, G., Vlahavas, I.: A comprehensive study over VLAD and product quantization in large-scale image retrieval. IEEE Trans. Multimed. 16(6), 1713–1728 (2014)
Vedaldi, A., Fulkerson, B.: VLFeat: an open and portable library of computer vision algorithms. In: Proceedings of ACM international conference on Multimedia, pp. 1469–1472. ACM (2010)
Wang, J., Yang, J., Yu, K., Lv, F., Huang, T., Gong, Y.: Locality-constrained linear coding for image classification. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, pp. 3360–3367. IEEE (2010)
Zhao, W.L., Ngo, C.W., Wang, H.: Fast covariant vlad for image search. IEEE Trans. Multimed. 18(9), 1843–1854 (2016)
Zheng, L., Wang, S., Liu, Z., Tian, Q.: Packing and padding: coupled multi-index for accurate image retrieval. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, pp. 1939–1946. IEEE (2014)
Zheng, L., Yang, Y., Tian, Q.: SIFT meets CNN: a decade survey of instance retrieval. IEEE Trans. Pattern Anal. Mach. Intell. PP(99), 1–1 (2017). https://doi.org/10.1109/tpami.2017.2709749
Zhou, Q., Wang, C., Liu, P., Li, Q., Wang, Y., Chen, S.: Distribution entropy boosted vlad for image retrieval. Entropy 18(8), 311 (2016)
Zhou, W., Li, H., Tian, Q.: Recent advance in content-based image retrieval: a literature survey. CoRR arxiv:1706.06064 (2017)
Funding
This work was partly supported by the China Scholarship Council (201706035021), the National Natural Science Foundation of China (61175096), the German Research Foundation in Project Crossmodal Learning (TRR-169) and Chinese Government Scholarship under China Scholarship Council.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Rights and permissions
About this article

Cite this article
Liu, H., Zhao, Q., Mbelwa, J.T. et al. Weighted two-step aggregated VLAD for image retrieval. Vis Comput 35, 1783–1795 (2019). https://doi.org/10.1007/s00371-018-1573-z
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00371-018-1573-z