
Abstract
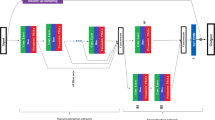
The challenge of image reconstruction from very-low-resolution images is made exceedingly difficult by multiple degradation factors in practical applications. Traditional methods do not consider the interactions between these degradation factors, so the results are often insufficient. To reconstruct low-resolution blurry images, both super-resolution and deblurring processes must be applied. In this paper, we propose a joint super-resolution and a deblurring model with integrated processing of the degradation factors to obtain better image quality. The joint model includes two branches, a super-resolution module and deblurring module, and both of them share the same feature extraction module. The super-resolution module consists of multiple layers of residual blocks. The deblurring module supports the robustness of the super-resolution module through feature feed-back in the learning process, by introducing an image blurring feature description into the feature representation. To create modules with high magnification, the base two-branch model is also used in two stages with scale recursion. A second-stage deblurring module receives the output of the first-stage super-resolution module and improves the deblurring capability when the image is further magnified. The modules enhance each other, significantly improve the quality of very-low-resolution text images, and maintain a low model complexity. A step-by-step training strategy is applied to reduce second-stage training difficulty. Experiments show that our approach significantly outperforms state-of-the-art methods in terms of image quality and optical character recognition accuracy, and with a lower computational cost.









Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Data availability
The datasets analyzed during the current study are available with the link: http://www.fit.vutbr.cz/\(\sim \)ihradis/CNN-Deblur.
References
Zhang, H., Yang, J., Zhang, Y., Nasrabadi, N.M., Huang, T.S.: Close the loop: joint blind image restoration and recognition with sparse representation prior. In: 2011 International Conference on Computer Vision, pp. 770–777 (2011). https://doi.org/10.1109/ICCV.2011.6126315
Li, J., Liang, X., Wei, Y., Xu, T., Feng, J., Yan, S.: Perceptual generative adversarial networks for small object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1222–1230 (2017). https://doi.org/10.1109/CVPR.2017.211
Kupyn, O., Budzan, V., Mykhailych, M., Mishkin, D., Matas, J.: Deblurgan: blind motion deblurring using conditional adversarial networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 8183–8192 (2018). https://doi.org/10.1109/CVPR.2018.00854
Wang, X., Yu, K., Wu, S., Gu, J., Liu, Y., Dong, C., Qiao, Y., Loy, C.C.: ESRGAN: Enhanced Super-Resolution Generative Adversarial Networks: Munich, Germany, September 8–14, 2018. Proceedings, Part (2019). https://doi.org/10.1007/978-3-030-11021-5_5
Yang, J., Wright, J., Huang, T.S., Ma, Y.: Image super-resolution via sparse representation. IEEE Trans Image Process. 19(11), 2861–2873 (2010). https://doi.org/10.1109/TIP.2010.2050625
Li, X., Cao, G., Zhang, Y., Shafique, A., Fu, P.: Combining synthesis sparse with analysis sparse for single image super-resolution. Signal Process. Image Commun. 83, 115805 (2020). https://doi.org/10.1016/j.image.2020.115805
Yoon, Y., Jeon, HG., Yoo, D., et al.: Learning a deep convolutional network for light-field image super-resolution. In: IEEE International Conference on Computer Vision Workshop. IEEE (2015). https://doi.org/10.1109/ICCVW.2015.17
Huang, J.B., Singh, A., Ahuja, N.: Single image super-resolution from transformed self-exemplars. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5197–5206 (2015). https://doi.org/10.1109/CVPR.2015.7299156
Yoon, Y., Jeon, HG., Yoo, D., et al.: Learning a deep convolutional network for light-field image super-resolution. In: IEEE International Conference on Computer Vision Workshop. IEEE (2015). https://doi.org/10.1109/TPAMI.2015.2439281
Kim, J., Kwon Lee, J., Mu Lee, K.: Accurate image super-resolution using very deep convolutional networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1646–1654. (2016). https://doi.org/10.1109/CVPR.2016.182
Chen, J., Li, B., Xue, X.:. Scene Text Telescope: Text-Focused Scene Image Super-Resolution, pp. 12021–12030 (2021). https://doi.org/10.1109/CVPR46437.2021.01185
Chen, Y., Liu, L., Phonevilay, V., et al.: Image super-resolution reconstruction based on feature map attention mechanism. Appl. Intell. 51, 4367–4380 (2021). https://doi.org/10.1007/s10489-020-02116-1
Chen, Y., Xia, R., Yang, K., et al.: MFFN: image super-resolution via multi-level features fusion network. Vis. Comput. (2023). https://doi.org/10.1007/s00371-023-02795-0
Harmeling, S., Michael, H., Schölkopf, B.: Space-variant single-image blind deconvolution for removing camera shake. In: Advances in Neural Information Processing Systems, pp. 829–837 (2010)
Li, X., Zheng, S., Jia, J.: Unnatural L0 sparse representation for natural image deblurring. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1107–1114 (2013). https://doi.org/10.1109/CVPR.2013.147
Tao, X., Gao, H., Shen, X., Wang, J., Jia, J.: Scale-recurrent network for deep image deblurring. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 8174–8182 (2018). https://doi.org/10.1109/CVPR.2018.00853
Hu, D., Tan, J., Zhang, L., et al.: Image deblurring based on enhanced salient edge selection. Vis. Comput. 39, 281–296 (2023). https://doi.org/10.1007/s00371-021-02329-6
Park, H., Lee, K.M.: Joint Estimation of Camera Pose, Depth, Deblurring, and Super-Resolution from a Blurred Image Sequence, pp. 4613–4621 (2017). https://doi.org/10.1109/ICCV.2017.494
Yamaguchi, T., Fukuda, H., Furukawa, R., Kawasaki, H., Sturm, P.: Video deblurring and super-resolution technique for multiple moving objects. In: Asian Conference on Computer Vision, pp. 127–140. Springer, Berlin (2010). https://doi.org/10.1007/978-3-642-19282-1_11
Lumentut, J., Park, I.: Deep neural network for joint light field deblurring and super-resolution, vol. 95 (2020). https://doi.org/10.1117/12.2566962
Niu, W., Zhang, K., Luo, W., Zhong, Y. Blind motion deblurring super-resolution: when dynamic spatio-temporal learning meets static image understanding. IEEE Trans. Image Process. (2021), https://doi.org/10.1109/TIP.2021.3101402
Zhang, X., Dong, H., Hu, Z., Lai, W.S., Wang, F., Yang, M.H.: Gated fusion network for joint image deblurring and super-resolution. arXiv preprint arXiv:1807.10806 (2018)
Xu, X., Sun, D., Pan, J., Zhang, Y., Pfifister, H., Yang, M.H.: Learning to super-resolve blurry face and text images. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 251–260 (2017). https://doi.org/10.1109/ICCV.2017.36
Xing, W., Egiazarian, K.: End-to-End Learning for Joint Image Demosaicing. Denoising and super-resolution, pp. 3506–3515 (2021). https://doi.org/10.1109/CVPR46437.2021.00351
Zhang, X., Wang, F., Dong, H., Guo, Y.: A deep dual-branch networks for joint blind motion deblurring and super-resolution. In: Proceedings of the 2nd International Conference on Vision, Image and Signal Processing (ICVISP 2018). Association for Computing Machinery, New York, NY, USA, Article 1, pp. 1–6 (2018). https://doi.org/10.1145/3271553.3271554
Odena, A., Dumoulin, V., Olah, C.: Deconvolution and Checkerboard Artifacts[EB/OL] (2016). https://doi.org/10.23915/distill.00003
Liu, Z., Yeh, R., Tang, X., Liu, Y., Agarwala, A.: Video frame synthesis using deep voxel flow. In ICCV. IEEE (2017). https://doi.org/10.1109/ICCV.2017.478
Su, S., Delbracio, M., Wang, J., Sapiro, G., Heidrich, W., Wang, O.: Deep video deblurring for hand-held cameras, pp. 1279–1288 (2017). https://doi.org/10.1109/CVPR.2017.33
Kingma, D., Ba, J.: Adam: a method for stochastic optimization. Computer Science (2014). https://doi.org/10.48550/arXiv.1412.6980
Lim, B., Son, S., Kim, H., Nah, S., Mu Lee, K.: Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, pp. 136–144 (2017). https://doi.org/10.1109/CVPRW.2017.151
Ledig, C., et al.: Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network, 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, pp. 105–114 (2017). https://doi.org/10.48550/arXiv.1609.04802
He, K., et al.: Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 37(9), 1904–1916 (2015). https://doi.org/10.1109/TPAMI.2015.2389824
He, K., Zhang, X., Ren, S., et al.: Delving deep into rectifiers: surpassing human-level performance on ImageNet classification. In: Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, pp. 1026–1034 (2015). https://doi.org/10.1109/ICCV.2015.123
Ma, J., Liang, Z., Zhang, L.: A text attention network for spatial deformation robust scene text image super-resolution (2022). https://doi.org/10.1109/CVPR52688.2022.00582
Hradiš, M., Kotera, J., Zemcık, P., šroubek, F.: Convolutional neural networks for direct text deblurring. In: Proceedings of BMVC, vol. 10, p. 2 (2015). https://doi.org/10.5244/C.29.6
Funding
This work was supported by the Natural Science Foundation of Tianjin (Grant No. 18JCYBJC85000).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no competing interests to declare that are relevant to the content of this article.
Ethical approval
The study complies with all ethical standards.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Zhu, Y., Wang, H. & Chen, S. Joint super-resolution and deblurring for low-resolution text image using two-branch neural network. Vis Comput 40, 2667–2678 (2024). https://doi.org/10.1007/s00371-023-02970-3
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00371-023-02970-3