
Abstract
The evaluation of clustering results plays an important role in clustering analysis and usually is completed by a validity index or several. But currently existing validity indexes are supervised since they greatly depend on prior information, such as specified clustering algorithms and optimal initializations. Once the prior information is unavailable, the evaluating results of these supervised validity indexes are no longer guaranteed, which lead to that their applicable ranges are greatly limited. In this paper, we firstly propose an estimation of the lower and upper bounds of the number of within-cluster distances in any dataset, and then an unsupervised validity index without needing any clustering algorithm and initialization is presented. A group of typical simulated and real datasets with various characteristics validate the proposed index in an unsupervised way. Experimental results demonstrate that the proposed index has higher accuracy in most tested datasets and has advantages in robustness and runtime compared with the other existing validity indexes.








Similar content being viewed by others

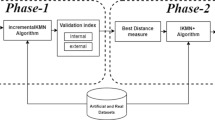
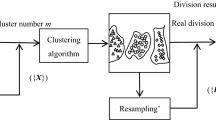
References
Arbelaitz O, Gurrutxaga I, Muguerza J, Perez JM, Perona I (2013) An extensive comparative study of cluster validity indices. Pattern Recogn 46(1):243–256
Azar AT, Hassanien AE (2015) Dimensionality reduction of medical big data using neural-fuzzy classifier. Soft Comput 19(4):1115–1127
Bezdek JC (1974) Cluster validity with fuzzy sets. J Cybern 3(3):58–73
Bezdek J (1981) Pattern recognition with fuzzy objective function algorithms. Plenum Press, New York
Caliński T, Harabasz J (1974) A dendrite method for cluster analysis. Commun Stat 3:1–27
Chou CH, Su MC, Lai E (2004) A new cluster validity measure and its application to image compression. Pattern Anal Appl 7(2):205–220
Davies DL, Bouldin DW (1979) A cluster separation measure. IEEE Trans Pattern Anal 1(2):224–227
Fahad A, Alshatri N, Tari Z, Alamri A, Khalil I, Zomaya AY, Foufou S, Bouras A (2014) A Survey of clustering algorithms for big data: taxonomy and empirical analysis. IEEE Trans Emerg Top Comput 2(3):267–279
Fukuyama Y, Sugeno M (1989) A new method of choosing the number of clusters for the fuzzy c-means method. In: Proceedings of fifth fuzzy system symposium. Kobe, pp 247–250
Gao Y, Huang JZ, Wu L (2007) Learning classifier system ensemble and compact rule set. Connect Sci 19(4):321–337
García-Gil D, Ramírez-Gallego S, García S, Herrera F (2017) A comparison on scalability for batch big data processing on Apache Spark and Apache Flink. Big Data Anal 2(1):1
Kim M, Ramakrishna RS (2005) New indices for cluster validity assessment. Pattern Recogn Lett 26(15):2353–2363
Lee C, Zaiane OR, Park H, Huang J, Greiner R (2008) Clustering high dimensional data: a graph-based relaxed optimization approach. Inf Sci 178(23):4501–4511
Liu C, Wang W, Konan M, Wang S, Huang L, Tang Y, Zhang X (2017) A new validity index of feature subset for evaluating the dimensionality reduction algorithms. Knowl Based Syst 121:83–98
MacQueen JB (1967) Some methods for classification and analysis of multivariate observations. In: Proceedings of the fifth Berkeley symposium on mathematical statistics and probability, University of California Press, California, pp 281–297
Maillo J, Ramirez S, Triguero I, Herrera F (2017) kNN-IS: an iterative spark-based design of the k-nearest neighbors classifier for big data. Knowl Based Syst 117(15):3–15
Mamat R, Herawan T, Denis MM (2013) MAR: maximum attribute relative of soft set for clustering attribute selection. Knowl Based Syst 52:11–20
Pakhira MK, Bandyopadhyay S, Maulik U (2004) Validity index for crisp and fuzzy clusters. Pattern Recogn 37(3):487–501
Pelleg D, Moore A (2000) X-means: extending K-means with efficient estimation of the number of clusters. In: 17th international conference on machine learning. Morgan Kaufmann, San Francisco, pp 727–734
Rodriguez A, Laio A (2014) Clustering by fast search and find of density peaks. Science 344(6191):1492–1496
Tibshirani R, Walther G, Hastie T (2001) Estimation the number of clusters in a dataset via the gap statistic. J R Stat Soc A Stat 63(2):411–423
Wang J, Lin C, Yang YC, Ho Y (2012) Walking pattern classification and walking distance estimation algorithms using gait phase information. IEEE Trans Bio-Med Eng 59(10):2884–2892
Wu KL, Yang MS (2002) Alternative c-means clustering algorithms. Pattern Recogn 35(10):2267–2278
Xie XL, Beni G (1991) A validity measure for fuzzy clustering. IEEE Trans Pattern Anal 13(13):841–847
Xu R, Wunsch D (2005) Survey of clustering algorithms. IEEE Trans Neural Net 16(3):645–678
Yue S, Wu T, Liu Z, Zhao X (2011) Fused multi-characteristic validity index: an application to reconstructed image evaluation in electrical tomography. Int J Comput Int Syst 4(5):1052–1061
Yue S, Wang P, Wang J, Huang T (2013) Extension of the gap statistics index to fuzzy clustering. Soft Comput 17(10):1833–1846
Yue S, Wang J, Wang J, Bao X (2016) A new validity index for evaluating the clustering results by partitional clustering algorithms. Soft Comput 20(3):1127–1138
Acknowledgements
This work was supported by the National Science Foundation of China (Grant No. 61573251). The authors thank Yalu Liao for assistance with editing the format of the original manuscript.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest. This article does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Communicated by V. Loia.
Rights and permissions
About this article

Cite this article
Wang, Y., Yue, S., Hao, Z. et al. An unsupervised and robust validity index for clustering analysis. Soft Comput 23, 10303–10319 (2019). https://doi.org/10.1007/s00500-018-3582-2
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-018-3582-2