
Abstract
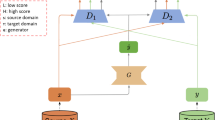
Multimodal image-to-image translation based on generative adversarial networks (GANs) shows suboptimal performance in the visual domains with high internal variability, e.g., translation from multiple breeds of cats to multiple breeds of dogs. To alleviate this problem, we recast the training procedure as modeling distinct distributions which are observed sequentially, for example, when different classes are encountered over time. As a result, the discriminator may forget about the previous target distributions, known as catastrophic forgetting, leading to non-/slow convergence. Through experimental observation, we found that the discriminator does not always forget the previously learned distributions during training. Therefore, we propose a novel generator regulating GAN (GR-GAN). The proposed method encourages the discriminator to teach the generator more effectively when it remembers more of the previously learned distributions, while discouraging the discriminator to guide the generator when catastrophic forgetting happens on the discriminator. Both qualitative and quantitative results show that the proposed method is significantly superior to the state-of-the-art methods in handling the image data that are with high variability.











Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Notes
Considering the memory consumption, the batch size of image translation models is usually very small, e.g., 1.
Some models use LSGAN (Mao et al. 2017) objective.
This dataset is available at http://www.robots.ox.ac.uk/~vgg//data/pets.
All testers are independent of the authors’ research group.
References
Arjovsky M, Chintala S, Bottou L (2007) Wasserstein generative adversarial networks. In: International conference on machine learning, pp 214–223
Bousmalis K, Silberman N, Dohan D, Erhan D, Krishnan D (2017) Unsupervised pixel-level domain adaptation with generative adversarial networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 3722–3731
Deng J, Dong W, Socher R, Li LJ, Li K, Fei-Fei L (2009) Imagenet: a large-scale hierarchical image database. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 248–255
Dong C, Loy CC, He K, Tang X (2014) Learning a deep convolutional network for image super-resolution. In: European conference on computer vision, pp 184–199
French RM (1999) Catastrophic forgetting in connectionist networks. Trends Cognit Sci 3(4):128–135
Ganin Y, Ustinova E, Ajakan H, Germain P, Larochelle H, Laviolette F, Marchand M, Lempitsky V (2016) Domain-adversarial training of neural networks. J Mach Learn Res 17(1):59.1–59.35
Gatys LA, Ecker AS, Bethge M (2016) Image style transfer using convolutional neural networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2414–2423
Gonzalez-Garcia A, van de Weijer J, Bengio Y (2018) Image-to-image translation for cross-domain disentanglement. In: Advances in neural information processing systems 31: Annual conference on neural information processing Systems 2018, pp 1287–1298
Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, Bengio Y (2014) Generative adversarial nets. In: Advances in neural information processing systems 27: Annual conference on neural information processing systems 2014, pp 2672–2680
Hinterstoisser S, Lepetit V, Ilic S, Holzer S, Bradski G, Konolige K, Navab N (2012) Model based training, detection and pose estimation of texture-less 3D objects in heavily cluttered scenes. In: Asian conference on computer vision, pp 548–562
Huang X, Liu MY, Belongie S, Kautz J (2018) Multimodal unsupervised image-to-image translation. In: Proceedings of the European conference on computer vision (ECCV), pp 172–189
Isola P, Zhu JY, Zhou T, Efros AA (2017) Image-to-image translation with conditional adversarial networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1125–1134
Kim T, Cha M, Kim H, Lee JK, Kim J (2017) Learning to discover cross-domain relations with generative adversarial networks. In: Proceedings of the 34th international conference on machine learning, vol 70, pp 1857–1865
Kirkpatrick J, Pascanu R, Rabinowitz N, Veness J, Desjardins G, Rusu AA, Milan K, Quan J, Ramalho T, Grabska-Barwinska A et al (2017) Overcoming catastrophic forgetting in neural networks. Proc Natl Acad Sci 114(13):3521–3526
Larsson G, Maire M, Shakhnarovich G (2016) Learning representations for automatic colorization. In: European conference on computer vision, pp 577–593
LeCun Y, Boser B, Denker JS, Henderson D, Howard RE, Hubbard W, Jackel LD (1989) Backpropagation applied to handwritten zip code recognition. Neural Comput 1(4):541–551
LeCun Y, Bottou L, Bengio Y, Haffner P et al (1998) Gradient-based learning applied to document recognition. Proc IEEE 86(11):2278–2324
Lee HY, Tseng HY, Huang JB, Singh M, Yang MH (2018) Diverse image-to-image translation via disentangled representations. In: Proceedings of the European conference on computer vision (ECCV), pp 35–51
Liu MY, Breuel T, Kautz J (2017) Unsupervised image-to-image translation networks. In: Advances in neural information processing systems 30: Annual conference on neural information processing systems 2017, pp 700–708
Liu D, Fu J, Qu Q, Lv J (2018) BFGAN: Backward and forward generative adversarial networks for lexically constrained sentence generation. IEEE ACM Trans Audio Speech Lang Process 27(12):2350–2361
Ma L, Jia X, Georgoulis S, Tuytelaars T, Van Gool L (2019) Exemplar guided unsupervised image-to-image translation with semantic consistency. In: International conference on learning representations
Mao X, Li Q, Xie H, Lau RY, Wang Z, Paul Smolley S (2017) Least squares generative adversarial networks. In: Proceedings of the IEEE international conference on computer vision, pp 2794–2802
Mirza M, Osindero S (2014) Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784
Parkhi OM, Vedaldi A, Zisserman A, Jawahar CV (2012) Cats and dogs. In: Proceedings of the IEEE conference on computer vision and pattern recognition
Pathak D, Krahenbuhl P, Donahue J, Darrell T, Efros AA (2016) Context encoders: feature learning by inpainting. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2536–2544
Radford A, Metz L, Chintala S (2016) Unsupervised representation learning with deep convolutional generative adversarial networks. In: International conference on learning representations
Salimans T, Goodfellow I, Zaremba W, Cheung V, Radford A, Chen X (2016) Improved techniques for training gans. In: Advances in neural information processing systems, pp 2234–2242
Sangkloy P, Lu J, Fang C, Yu F, Hays J (2017) Scribbler: controlling deep image synthesis with sketch and color. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 5400–5409
Seff A, Beatson A, Suo D, Liu H (2017) Continual learning in generative adversarial nets. arXiv preprint arXiv:1705.08395
Tang C, Xu K, He Z, Lv J (2019) Exaggerated portrait caricatures synthesis. Inf Sci 502:363–375
Thanh-Tung H, Tran T, Venkatesh S (2018) On catastrophic forgetting and mode collapse in generative adversarial networks. arXiv preprint arXiv:1807.04015
Wu C, Herranz L, Liu X, Wang Y, van de Weijer J, Raducanu B (2018) Memory replay gans: learning to generate images from new categories without forgetting. In: Conference on neural information processing systems (NIPS)
Yi Z, Zhang H, Tan P, Gong M (2017) Dualgan: unsupervised dual learning for image-to-image translation. In: Proceedings of the IEEE international conference on computer vision, pp 2849–2857
Yu X, Ying Z, Li G, Gao W (2018) Multi-mapping image-to-image translation with central biasing normalization. arXiv preprint arXiv:1806.10050
Zhang R, Isola P, Efros AA (2016) Colorful image colorization. In: European conference on computer vision, pp 649–666
Zhang R, Isola P, Efros AA, Shechtman E, Wang O (2018) The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 586–595
Zhu JY, Krähenbühl P, Shechtman E, Efros AA (2016) Generative visual manipulation on the natural image manifold. In: European conference on computer vision, pp. 597–613
Zhu JY, Park T, Isola P, Efros AA (2017a) Unpaired image-to-image translation using cycle-consistent adversarial networks. In: Proceedings of the IEEE international conference on computer vision, pp 2223–2232
Zhu JY, Zhang R, Pathak D, Darrell T, Efros AA, Wang O, Shecht man E (2017b) Toward multimodal image-to-image translation. In: Advances in neural information processing systems 30: Annual conference on neural information processing systems 2017, pp 465–476
Acknowledgements
This work was supported by the National Key R&D Program of China under Contract No. 2017YFB1002201, the National Natural Science Fund for Distinguished Young Scholar (Grant No. 61625204) and partially supported by the State Key Program of National Science Foundation of China (Grant Nos. 61836006 and 61432014).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Communicated by V. Loia.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Wang, J., Lv, J., Yang, X. et al. Multimodal image-to-image translation between domains with high internal variability. Soft Comput 24, 18173–18184 (2020). https://doi.org/10.1007/s00500-020-05073-6
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-020-05073-6