
Abstract
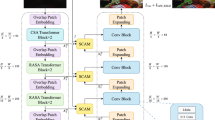
Low-light image enhancement is a low-level vision task. Most of the existing methods are based on convolutional neural network(CNN). Transformer is a predominant deep learning model that has been widely adopted in various fields, such as natural language processing and computer vision. Compared with CNN, transformer has the ability to capture long-range dependencies to make full use of global contextual information. For low-light enhancement tasks, this capability can promote the model to learn the correct luminance, color and texture. We try to introduce transformer into the low-light image enhancement field. In this paper, we design a pyramid transformer with cross-shaped windows (CSwin-P). CSwin-P contains an encoder and decoder. Both the encoder and decoder contain several stages. Each stage contains several enhanced CSwin transformer blocks (ECTB). ECTB uses cross-shaped window self-attention and a feed-forward layer with spatial interaction unit. Spatial interaction unit can further capture local contextual information through gating mechanism. CSwin-P uses implicit positional encoding, and the model is unrestricted by the image size in the inference phase. Numerous experiments prove that our method is superior to the current state-of-the-art methods.






Similar content being viewed by others

Data Availibility
The datasets used during and/or analysed during the current study are publicly available. The corresponding papers are cited accordingly.
References
Bychkovsky V, Paris S, Chan E, Durand F (2011) Learning photographic global tonal adjustment with a database of input/output image pairs. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp. 97-104
Cai B, Xu X, Guo K, Jia K, Hu B, Tao D (2017) A joint intrinsic-extrinsic prior model for retinex. In: Proceedings of the IEEE international conference on computer vision (ICCV), pp. 4020-4029
Chen Y-S, Wang Y-C, Kao M-H, Chuang Y-Y (2018) Deep photo enhancer: unpaired learning for image enhancement from photographs with gans. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp. 6306-6314
Chen J, Lu Y, Yu Q (2021) Transunet: Transformers make strong encoders for medical image segmentation. arXiv preprint arXiv:2102.04306
Chu X, Tian Z, Wang Y, Zhang B, Ren H, Wei X, Xia H, Shen C (2021) Twins: revisiting the design of spatial attention in vision transformers. In: Proceedings of the neural information processing systems (NeurIPS)
Chu X, Tian Z, Zhang B, Wang X, Wei X, Xia H, Shen C (2021) Conditional positional encodings for vision transformers, Arxiv preprint arXiv:2102.10882
Dai Z, Liu H, Le QV, Tan M (2021) Coatnet: marrying convolution and attention for all data sizes, arXiv preprint arXiv:2106.04803
Dascoli S, Touvron H, Leavitt M, Morcos A, Biroli G, Sagun L (2021) Convit: improving vision transformers with soft convolutional inductive biases. In: International conference on machine learning. PMLR, pp. 2286-2296
Deng, Jia, Dong, Wei, Socher, Richard, Li, Li-Jia, Li, Kai, Fei-Fei, Li (2009) Imagenet: A large-scale hierarchical image database, In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 248-255
Dong X, Bao J, Chen D, Zhang W, Yu N, Yuan L, Chen D, Guo B (2022) Cswin transformer: a general vision transformer backbone with cross-shaped windows. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 12124-12134
Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, Unterthiner T, Dehghani M, Minderer M, Heigold G, Gelly S, Uszkoreit J, Houlsby N (2021) An image is worth 16x16 words: transformers for image recognition at scale. In: Proceedings of the international conference on learning representations (ICLR)
Fu X, Zeng D, Huang Y, Zhang X-P, Ding X (2016) A weighted variational model for simultaneous reflectance and illumination estimation. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp. 2782- 2790
Guo M-H, Cai J-X, Liu Z-N, Mu TJ, Martin RR, Hu S-M (2021) Pct: point cloud transformer. Comput Vis Med 7(2):187–199
Hendrycks D, Gimpel K (2020) Gaussian error linear units (gelus), Arxiv preprint arXiv:1606.08415
Hu Y, He H, Xu C, Wang B, Lin S (2018) Exposure: a white-box photo post- processing framework. ACM Trans Graph 37(2)
Johnson J, Alahi A, Fei-Fei L (2016) Perceptual losses for real-time style transfer and super- resolution. In: European conference on computer vision, Springer, Cham, pp 694–711
Kamran SA, Hossain KF, Tavakkoli A, et al (2021) Vtgan: semi-supervised retinal image synthesis and disease prediction using vision transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 3235-3245
Li C, Guo J, Porikli F, Pang Y (2018) Lightennet: a convolutional neural network for weakly illuminated image enhancement. Pattern Recogn Lett 104:15–22
Li J, Li J, Fang F, Li F, Zhang G (2021) Luminance-aware pyramid network for low-light image enhancement. IEEE Trans Multimed 23:3153–3165
Liang J, Cao J, Sun G, Zhang K, Gool L Van, Timofte R (2021) Swinir: image restoration using swin transformer. In: Proceedings of the IEEE international conference on computer vision (ICCV)
Li C, Guo G, Chunle L, Chen C (2021) Learning to enhance low-light image via zero-reference deep curve estimation. IEEE Trans Pattern Anal Mach Intell
Liu H, Dai Z, So DR, Le QV (2021) Pay attention to MLPS. Adv Neural Inf Process Syst 34:9204–9215
Liu L, Chen E, Ding Y (2022) TR-Net: a transformer-based neural network for point cloud processing. Machines 10(7):517
Liu Z, Lin Y, Cao Y, Hu H, Wei Y, Zhang Z, Lin S, Guo B (2021) Swin transformer: Hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE international conference on computer vision (ICCV)
Li Y, Zhang K, Cao J, Timofte R, Gool L Van (2021) Localvit: bringing locality to vision transformers, arXiv preprint arXiv:2104.05707
Lore KG, Akintayo A, Sarkar S (2017) Llnet: a deep autoencoder approach to natural low-light image enhancement. Pattern Recogn 61:650–662
Pizer SM, Johnston RE, Ericksen JP, Yankaskas BC, Muller KE (1990) Contrast-limited adaptive histogram equalization: speed and effectiveness. In: Proceedings of the first conference on visualization in biomedical computing, pp. 337-345
Pizer SM, Amburn EP, Austin JD, Cromartie R, Zuiderveld K (1987) Adaptive histogram equalization and its variations. Comput Vis Graph Image Process 39(3):355–368
Risheng L, Long M, Jiaao Z, Xin F, Zhongxuan L (2021) Retinex-inspired unrolling with cooperative prior architecture search for low- light image enhancement. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR)
Wang S, Zheng J, Hai-Miao H, Li B (2013) Naturalness preserved enhancement algorithm for non- uniform illumination images. IEEE Trans Image Process 22(9):3538–3548
Wang Z, Cun X, Bao J, Liu J (2022) Uformer: a general u-shaped transformer for image restoration. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 17683-17693
Wang W, Wei C, Yang W, Liu J (2018) Gladnet: low-light enhancement network with global awareness. In: 2018 13th IEEE international conference on automatic face and gesture recognition (FG 2018). IEEE pp. 751-755
Wang W, Xie E, Li X, Fan D-P, Song K, Liang D, Lu T, Luo P, Shao L (2021) Pyramid vision transformer: a versatile backbone for dense prediction without convolutions. In: Proceedings of the IEEE international conference on computer vision (ICCV)
Wang R, Zhang Q, Fu C-W, Shen X, Zheng W-S, Jia J (2019) Underexposed photo enhancement using deep illumination estimation. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp. 6842- 6850
Wu H, Xiao B, Codella N, Liu M, Dai X, Yuan L, Zhang L (2021) Cvt: introducing convolutions to vision transformers. In: Proceedings of the IEEE/CVF international conference on computer vision, pp. 22-31
Xiao T, Singh M, Mintun E, Darrell T, Dollár P, Girshick R (2021) Early convolutions help transformers see better. Adv Neural Inf Process Syst 34:30392–30400
Xiaogang X, Wang R, Fu C-W, Jia J (2022) SNR-aware low-light image enhancement. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 17714-17724
Xiaojie G, Yu L, Haibin L (2017) Lime: low-light image enhancement via illumination map estimation. IEEE Trans Image Process 26(2):982–993
Xie E, Wang W, Zhiding Yu, Anandkumar A, Jose MA, Ping L (2021) Segformer: simple and efficient design for semantic segmentation with transformers. Adv Neural Inf Process Syst 34:12077–12090
Yang W, Liu J, Wei C, Wang W (2018) Deep retinex decomposition for low-light enhancement, arXiv preprint arXiv:1808.04560
Yang J, Li C, Zhang P, Dai X, Xiao B, Yuan L, Gao J (2021) Focal self-attention for local-global interactions in vision transformers, arXiv preprint arXiv:2107.00641
Yuan L, Chen Y, Wang T, Yu W, Shi Y, Jiang Z-H, Tay FE, Feng J, Yan S (2021) Tokens-to-token vit: Training vision transformers from scratch on imagenet. In: Proceedings of the IEEE international conference on computer vision (ICCV), pp. 558-567
Yuan K, Guo S, Liu Z, Zhou A, Yu F, Wu W (2021) Incorporating convolution designs into visual transformers. In: Proceedings of the IEEE/CVF international conference on computer vision, pp. 579-588
Zamir SW, Arora A, Khan S, Hayat M, Khan FS, Yang MH, Shao L (2020) Learning enriched features for real image restoration and enhancement. In: Proceedings of the European conference on computer vision (ECCV)
Zhang P, Dai X, Yang J, Xiao B, Yuan L, Zhang L, Gao J (2021) Multi- scale vision longformer: a new vision transformer for high-resolution image encoding. In: Proceedings of the IEEE international conference on computer vision (ICCV)
Zhang Y, Liu H, Hu Q (2021) Transfuse: fusing transformers and cnns for medical image segmentation. In: Proceedings of the medical image computing and computer assisted intervention-MICCA I, pp.14–24
Zhang Y, Zhang J, Guo X (2019) Kindling the darkness: a practical low-light image enhancer. In: Proceedings of the 27th ACM international conference on multimedia, New York, NY, USA, pp. 1632-1640
Zheng C, Zhu S, Mendieta M, Yang T, Chen C, Ding Z (2021) 3d human pose estimation with spatial and temporal transformers. In: Proceedings of the IEEE international conference on computer vision (ICCV)
Acknowledgements
The work was supported in part by the Science and Technology Planning Project of Henan Province under Grant 212102210097.
Funding
The authors have not disclosed any funding.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
Conflict of interest The authors declare that they have no conflict of interest to this work.
Ethical approval
This chapter does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Li, C., Gao, P., Song, S. et al. A pyramid transformer with cross-shaped windows for low-light image enhancement. Soft Comput 28, 4399–4411 (2024). https://doi.org/10.1007/s00500-023-08788-4
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-023-08788-4