
Abstract
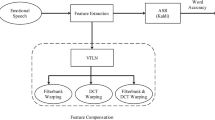
In recognition of emotional speech, the performance of automatic speech recognition (ASR) systems is degraded significantly. To improve the recognition rate of ASR systems, we can neutralize the Mel-frequency cepstral coefficients (MFCCs) of emotional speech as the most frequently used features in ASR. In this way, the neutralized MFCCs are used in a hidden Markov model (HMM)-based ASR system that has been trained by nonemotional speech. In this paper, the frequency range that is most affected by emotion is determined, and the frequency warping is applied in the calculation process of MFCCs. This warping is performed in Mel filterbank module and/or discrete cosine transform (DCT) module in the process of MFCCs’ calculation. To determine the warping factor, a combined structure using dynamic time warping (DTW) technique and multi-layer perceptron (MLP) neural network is used. Experimental results show that the recognition rate in anger and happiness emotional states is improved when the warping is performed in each of the mentioned modules when the MFCCs are calculated. Also, when the warping is performed in both the Mel filterbank and the DCT modules, the recognition rate of speech in anger and happiness emotional states is improved by 6.4 and 3.0%, respectively.






Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.References
Strik H, Cucchiarini C (1999) Modeling pronunciation variation for ASR: a survey of the literature. Speech Commun 29:225–246
Vlasenko B, Wendemuth A (2009) Heading toward to the natural way of human-machine interaction: the NIMITEK project. Proceedings of IEEE international conference on multimedia and expo, pp 950–953
Ijima Y, Tachibana M, Nose T, Kobayashi T (2009) Emotional speech recognition based on style estimation and adaptation with multiple-regression HMM. Proceedings of IEEE international conference on acoustic, speech and signal processing, pp 4157–4160
Ververidis D, Kotropoulos C (2006) Emotional speech recognition: resources, features, and methods. Speech Commun 48:1162–1181
Schuller B, Seppi D, Batliner A, Maier A, Steidl S (2007) Towards more reality in the recognition of emotional speech. Proceedings of IEEE international conference on acoustic, speech and signal processing, vol 4, pp 941–944
Schuller B, Batliner A, Steidl S, Seppi D (2009) Emotion recognition from speech: putting ASR in the loop. Proceedings of IEEE international conference on acoustic, speech and signal processing, pp 4585–4588
Krajewski J, Batliner A, Kessel S (2010) Comparing multiple classifiers for speech-based detection of self-confidence-A pilot study. Proceedings international conference on pattern recognition, pp 3716–3719
Athanaselis T, Bakamidis S, Dologlou I, Cowie R, Douglas-Cowie E, Cox C (2005) ASR for emotional speech: clarifying the issues and enhancing performance. J Neural Netw 18:437–444
Litman DJ, Hirschberg JB, Swerts M (2000) Predicting automatic speech recognition performance using prosodic cues. Proceedings North American chapter of the association for computational linguistics conference, pp 218–225
Steeneken HJM, Hansen JHL (1999) Speech under stress conditions: overview of the effect of speech production and on system performance. Proceedings of IEEE international conference on acoustic, speech and signal processing, vol 4, pp 2079–2082
Benzeghiba M, De Mori R, Deroo O, Dupont S, Erbes T, Jouvet D, Fissore L, Laface P, Mertins A, Ris C, Rose R, Tyagi V, Wellekens C (2007) Automatic speech recognition and speech variability: a review. Speech Commun 49:763–786
Hansen JH, Patil S (2007) Speech under stress: analysis, modeling and recognition. Springer, Berlin, pp 108–137
Gharavian D (2004) Prosody in Farsi language and its use in recognition of intonation and speech. Ph.D. Dissertation, Electrical Engineering Department, Amirkabir University of Technology, Tehran
Gharavian D, Ahadi SM (2006) Recognition of emotional speech and speech emotion in Farsi. Proceedings of international symposium on Chinese spoken language processing, vol 2, pp 299–308
Gharavian D, Ahadi SM (2005) The effect of emotion on Farsi speech parameters: a statistical evaluation. Proceedings of international conference on speech and computer, pp 463–466
Gharavian D, Sheikhan M, Janipour M (2010) Pitch in emotional speech and emotional speech recognition using pitch frequency. Majlesi J Electr Eng 4(1):19–24
Bosch LT (2003) Emotions, speech and the ASR framework. Speech Commun 40:213–225
Müller F, Mertins A (2011) Contextual invariant-integration features for improved speaker-independent speech recognition. Speech Commun. doi:10.1016/j.specom.2011.02.002 Article in Press
Welling L, Ney H, Kanthak S (2002) Speaker adaptive modeling by vocal tract normalization. IEEE Trans Speech Audio Process 10:415–426
Sinha R, Umesh S (2002) Non-uniform scaling based speaker normalization. Proceedings of IEEE international conference on acoustic, speech and signal processing, vol 1, pp 589–592
Gales MJF (1998) Maximum likelihood linear transformations for HMM-based speech recognition. Comput Speech Lang 12:75–98
Byrne W, Doermann D, Franz M, Gustman S, Hajič J, Oard D, Picheny M, Psutka J, Ramabhadran B, Soergel D, Ward T, Zhu W-J (2004) Automatic recognition of spontaneous speech for access to multilingual oral history archives. IEEE Trans Speech Audio Process 12:420–435
Godfrey J, Holliman E, McDaniel J (1992) SWITCHBOARD: telephone speech corpus for research and development. Proceedings of IEEE international conference on acoustic, speech and signal processing, pp 517–520
Pan YC, Xu MX, Liu LQ, Jia PF (2006) Emotion-detecting based model selection for emotional speech recognition. Proceedings of multiconference on computational engineering in system applications, pp 2169–2172
Meng H, Pittermann J, Pittermann A, Minker W (2007) Combined speech-emotion recognition for spoken human-computer interfaces. Proceedings IEEE international conference on signal processing and communications, pp 1179–1182
Sun Y, Zhou Y, Zhao Q, Yan Y (2009) Acoustic feature optimization for emotion affected speech recognition. Proceedings of international conference on information engineering and computer science, pp 1–4. doi:10.1109/ICIECS.2009.5365821
Muralishankar R, Sangwan A, O’Shaughnessy D (2007) Theoretical complex cepstrum of DCT and warped DCT filters. IEEE Signal Process Lett 14:367–370
Chang J-H (2005) Warped discrete cosine transform-based noisy speech enhancement. IEEE Trans Circuits Syst II 52:535–539
Panchapagesan S (2006) Frequency warping by linear transformation of standard MFCC. Proceedings of interspeech, pp 397–400
Pitz M, Molau S, Schlueter R, Ney H (2001) Vocal tract normalization equals linear transformation in cepstral space. Proceedings of European conference on speech communication and technology, pp 721–724
Clavel C, Vasilescu I, Devillers L (2011) Fiction support for realistic portrayals of fear-type emotional manifestations. Comput Speech Lang 25:63–83
Bijankhan M, Sheikhzadegan J, Roohani MR, Samareh Y, Lucas C, Tebiani M (1994) The speech database of Farsi spoken language. Proceedings of Australian international conference on speech science and technology, pp 826–831
Young SJ, Evermann G, Kershaw D, Moore G, Odell J, Ollason D, Povey D, Valtchev V, Woodland V (2002) The HTK book (Ver.3.2). Cambridge University, Cambridge
McCandless SS (1974) An Algorithm for formant extraction using linear prediction spectra. IEEE Trans Acoustics Speech Signal Process 22:135–141
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Sheikhan, M., Gharavian, D. & Ashoftedel, F. Using DTW neural–based MFCC warping to improve emotional speech recognition. Neural Comput & Applic 21, 1765–1773 (2012). https://doi.org/10.1007/s00521-011-0620-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-011-0620-8