
Abstract
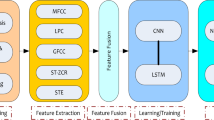
This paper investigates the ability of deep neural networks (DNNs) to improve the automatic recognition of dysarthric speech through the use of convolutional neural networks (CNNs) and long short-term memory (LSTM) neural networks. Dysarthria is one of the most common speech communication disorders associated with neurological impairments that can drastically reduce the intelligibility of speech. The aim of the present study is twofold. First, it compares three different input features for training and testing dysarthric speech recognition systems. These features are the mel-frequency cepstral coefficients (MFCCs), mel-frequency spectral coefficients (MFSCs), and the perceptual linear prediction features (PLPs). Second, the performance of the CNN- and LSTM-based architectures is compared against a state-of-the-art baseline system based on hidden Markov models (HMMs) and Gaussian mixture models (GMMs) to determine the best dysarthric speech recognizer. Experimental results show that the CNN-based system using perceptual linear prediction features provides a recognition rate that can reach 82%, which constitutes relative improvement of 11% and 32% when compared to the performance of LSTM- and GMM-HMM-based systems, respectively.










Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.References
Darley FL, Aronson AE, Brown JR (1969) Differential diagnostic patterns of dysarthria. J Speech Hear Res 12(2):246–269. https://doi.org/10.1044/jshr.1202.246
Glorot X, Bordes A, Bengio Y (2011) Deep sparse rectifier neural networks. In: Proceedings of the 14th international conference on artificial intelligence and statistics, vol 15, pp 315–323, Lauderdale, FL, USA
Enderby P (2013) Disorders of communication: dysarthria. Handb Clin Neurol 110:273–281. https://doi.org/10.1016/B978-0-444-52901-5.00022-8
Hux K, Rankin-Erickson J, Manasse N, Lauritzen E (2000) Accuracy of three speech recognition systems: case study of dysarthric speech. Augment Altern Commun 16(3):186–196. https://doi.org/10.1080/07434610012331279044
Rosengren E (2000) Perceptual analysis of dysarthric speech in the enable project. J TMH-QPSR 41(1):13–18
Le Scaon R (2015) Projet 3A: Détection du langage d’un locuteur sur enregistrement audio.
Fager SK, Beukelman DR, Jakobs T, Hosom JP (2010) Evaluation of a speech recognition prototype for speakers with moderate and severe dysarthria: a preliminary report. Augment Altern Commun 26(4):267–277. https://doi.org/10.3109/07434618.2010.532508
Ziegler W, von Cramon D (1986) Spastic dysarthria after acquired brain injury: an acoustic study. Br J Disord Commun 21(2):173–187. https://doi.org/10.3109/13682828609012275
Selouani S, Sidi Yakoub M, O’Shaughnessy D (2009) Alternative speech communication system for persons with severe speech disorders. EURASIP J Adv Signal Process. https://doi.org/10.1155/2009/540409
Polur PD, Miller GE (2006) Investigation of an HMM/ANN hybrid structure in pattern recognition application using cepstral analysis of dysarthric (distorted) speech signals. Med Eng Phys 28(8):741–748. https://doi.org/10.1016/j.medengphy.2005.11.002
Hasegawa-Johnson M, Gunderson J, Perlman A, Huang T (2006) HMM-based and SVM-based recognition of the speech of talkers with spastic dysarthria. In: 2006 IEEE international conference on acoustics speech and signal processing (ICASSP), vol 3, p III, Toulouse, France. https://doi.org/10.1109/ICASSP.2006.1660840
Shahamiri SR, Salim SSB (2014) Artificial neural networks as speech recognisers for dysarthric speech: identifying the best-performing set of MFCC parameters and studying a speaker-independent approach. Adv Eng Inform 28(1):102–110. https://doi.org/10.1016/j.aei.2014.01.001
Hermans M, Schrauwen B (2013) Training and analysing deep recurrent neural networks. Adv Neural Inf Process Syst 26:190–198
Fager S, Bardach L, Russell S, Higginbotham J (2012) Access to augmentative and alternative communication: new technologies and clinical decision-making. J Pediatr Rehabil Med 5(1):53–61. https://doi.org/10.3233/PRM-2012-0196
Das D, Lee CSG (2018) Cross-Scene trajectory level intention inference using gaussian process regression and naïve registration. Department of Electrical and Computer Engineering Technical Reports, Paper 491. https://docs.lib.purdue.edu/ecetr/491/
Oue S, Marxer R, Rudzicz F (2015) Automatic dysfluency detection in dysarthric speech using deep belief networks. In: Proceedings of SLPAT 2015: 6th workshop on speech and language processing for assistive technologies (SLPAT), pp 60–64, Dresden, Germany. https://doi.org/10.18653/v1/W15-5111
Burkert P, Trier F, Afzal M Z, Dengel A, Liwicki M (2015) Dexpression: deep convolutional neural network for expression recognition. arXiv:1509.05371v1
Hochreiter S, Schmidhuber J (1997) Long short-term memory. Neural Comput 9(8):1735–1780. https://doi.org/10.1162/neco.1997.9.8.1735
Farhadipour A, Veisi H, Asgari M, Keyvanrad MA (2018) Dysarthric speaker identification with different degrees of dysarthria severity using deep belief networks. Electron Telecommun Res Inst (ETRI) J 40(5):643–652. https://doi.org/10.4218/etrij.2017-0260
Joy NM, Umesh S (2018) Improving acoustic models in TORGO dysarthric speech database. IEEE Trans Neural Syst Rehabil Eng 26(3):637–645. https://doi.org/10.1109/TNSRE.2018.2802914
Jiao Y, Tu M, Berisha V, Liss J (2018) Simulating dysarthric speech for training data augmentation in clinical speech applications. In: 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP), pp 6009–6013, Calgary, AB, Canada. https://doi.org/10.1109/ICASSP.2018.8462290
Tu M, Berisha V, Liss J (2017) Interpretable objective assessment of dysarthric speech based on deep neural networks. In: Proceedings of the annual conference of the international speech communication association, INTERSPEECH 2017, pp 1849–1853, Stockholm, Sweden. https://doi.org/10.21437/Interspeech.2017-1222
Ijitona T B, Soraghan J J, Lowit A, Di-Caterina G, Yue H (2017) Automatic detection of speech disorder in dysarthria using extended speech feature extraction and neural networks classification. In: IET 3rd international conference on intelligent signal processing (ISP 2017), pp 1–6, London. https://doi.org/10.1049/cp.2017.0360
Chandrakala S, Rajeswari N (2017) Representation learning based speech assistive system for persons with dysarthria. IEEE Trans Neural Syst Rehabil Eng 25(9):1510–1517. https://doi.org/10.1109/TNSRE.2016.2638830
Tu M, Wisler A, Berisha V, Liss JM (2016) The relationship between perceptual disturbances in dysarthric speech and automatic speech recognition performance. J Acoust Soc Am 140(5):416–422. https://doi.org/10.1121/1.4967208
Espana-Bonet C, Fonollosa JAR (2016) Automatic speech recognition with deep neural networks for impaired speech. In: International conference on advances in speech and language technologies for Iberian languages, IberSPEECH 2016, vol 10077. Springer, Cham, pp 97–107. https://doi.org/10.1007/978-3-319-49169-1_10
Nakashika T, Yoshioka T, Takiguchi T, Ariki Y, Duffner S, Garcia C (2014) Convolutive bottleneck network with dropout for dysarthric speech recognition. Trans Mach Learn Artif Intell 2(2):1–15. https://doi.org/10.14738/tmlai.22.150
Yılmaz E, Mitra V, Sivaraman G, Franco H (2019) Articulatory and Bottleneck features for speaker-independent ASR of dysarthric speech. Comput Speech Lang 58:319–334. https://doi.org/10.1016/j.csl.2019.05.002
Tripathi A, Bhosale S, Kopparapu S K (2020) A novel approach for intelligibility assessment in dysarthric subjects. In: 2020 IEEE international conference on acoustics, speech and signal processing (ICASSP), pp 6779–6783, Barcelona, Spain. https://doi.org/10.1109/ICASSP40776.2020.9053339
Sak H, Senior A, Beaufays F (2014) Long short-term memory recurrent neural network architectures for large scale acoustic modeling. In: INTERSPEECH 2014, 15th annual conference of the international speech communication association, pp 338–342, Singapore
Zhang Y, Chen G, Yu D, Yaco K, Khudanpur S, Glass J (2016) Highway long short-term memory RNNS for distant speech recognition. In: 2016 IEEE international conference on acoustics, speech and signal processing (ICASSP), pp 5755–5759, Shanghai, China. https://doi.org/10.1109/ICASSP.2016.7472780
Graves A, Jaitly N, Mohamed A (2013) Hybrid speech recognition with deep bidirectional LSTM. In: 2013 IEEE workshop on automatic speech recognition & understanding (ASRU), pp 273–278, Olomouc, Czech Republic. https://doi.org/10.1109/ASRU.2013.6707742
Eyben F, Wöllmer M, Schuller B, Graves A (2009) From speech to letters-using a novel neural network architecture for grapheme based ASR. In: 2009 IEEE workshop on automatic speech recognition and understanding (ASRU), pp. 376–380, Merano, Italy. https://doi.org/10.1109/ASRU.2009.5373257
Graves A, Mohamed A, Hinton G (2013) Speech recognition with deep recurrent neural networks. In: 2013 IEEE international conference on acoustics, speech and signal processing (ICASSP), pp 6645–6649, Vancouver, BC, Canada. https://doi.org/10.1109/ICASSP.2013.6638947
Mayle A, Mou Z, Bunescu R, Mirshekarian S, Xu L, LiuC (2019) Diagnosing dysarthria with long short-term memory networks. In: INTERSPEECH 2019, pp 4514–4518, Graz, Austria. https://doi.org/10.21437/Interspeech.2019-2903
Bhat C, Strik H (2020) Automatic assessment of sentence-level dysarthria intelligibility using BLSTM. IEEE J Sel Top Signal Process 14(2):322–330. https://doi.org/10.1109/JSTSP.2020.2967652
Menendez-Pidal X, Poliko JB, Peters SM, Leonzio JE, Bunnell HT (1996) The nemours database of dysarthric speech. In: Proceeding of 4th international conference on spoken language processing (ICSLP ‘96), vol 3, pp 1962–1965, Philadelphia, PA, USA. https://doi.org/10.1109/ICSLP.1996.608020
Nimbalkar TS, Bogiri N (2016) A novel integrated fragmentation clustering allocation approach for promote web telemedicine database system. Int J Adv Electron Comput Sci (IJAECS) 2(2):1–11
Davis SB, Mermelstein P (1980) Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. IEEE Trans Acoust Speech Signal Process 28(4):357–366. https://doi.org/10.1109/TASSP.1980.1163420
Mohamed A, Hinton G, Penn G (2012) Understanding how deep belief networks perform acoustic modelling. In: 2012 IEEE international conference on acoustics, speech and signal processing (ICASSP), pp 4273-4276, Kyoto, Japan. https://doi.org/10.1109/ICASSP.2012.6288863
Hermansky H (1990) Perceptual linear predictive (PLP) analysis of speech. J Acoust Soc Am 87(4):1738–1752. https://doi.org/10.1121/1.399423
Zaidi B F, Selouani S, Boudraa M, Addou D, SidiYakoub M (2020) Automatic recognition system for dysarthric speech based on MFCC’s, PNCC’s, JITTER and SHIMMER coefficients. In: Advances in computer vision CVC 2019. Advances in intelligent systems and computing, vol 944. Springer, Cham, pp 500–510. https://doi.org/10.1007/978-3-030-17798-0_40
Young S, Evermann G, Gales M, Hain T, Kershaw D, Liu X, Moore G, Odell J, Ollason D, Povey D et al (1995–2015) The HTK book. Cambridge University Engineering Department
Alu D, Zoltan E, Stoica IC (2018) Voice based emotion recognition with convolutional neural networks for companion robots. Roman J Inf Sci Technol 20(3):222–241
Bhagatpatil MVV, Sardar V (2015) An automatic infants cry detection using linear frequency Cepstrum coefficients (LFCC). Int J Technol Enhanc Emerg Eng Res (IJTEEER) 3(2):29–34
Nair V, Hinton G E (2010) Rectified linear units improve restricted Boltzmann machines. In: Proceedings of the 27th international conference on machine learning (ICML), pp 1–8.
Dengsheng C, Jun L, Kai X (2020) AReLU: attention-based rectified linear unit. arXiv:2006.13858v2
Klambauer G, Unterthiner T, Mayr A, Hochreiter S (2017) Self-normalizing neural networks. In: Advances in neural information processing systems, pp 971–980
Funding
Funding was provided by Natural Sciences and Engineering Research Council of Canada under the reference number RGPIN-2018-05221.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflicts of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Zaidi, B.F., Selouani, S.A., Boudraa, M. et al. Deep neural network architectures for dysarthric speech analysis and recognition. Neural Comput & Applic 33, 9089–9108 (2021). https://doi.org/10.1007/s00521-020-05672-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-020-05672-2