
Abstract
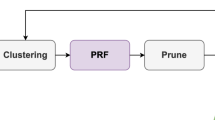
The redundancy in convolutional neural networks (CNNs) causes a significant number of extra parameters resulting in increased computation and less diverse filters. In this paper, we introduce filter pruning via expectation-maximization (FPEM) to trim redundant structures and improve the diversity of remaining structures. Our method is designed based on the discovery that the filter diversity of pruned networks is positively correlated with its performance. The expectation step divides filters into groups by maximum likelihood layer-wisely, and averages the output feature maps for each cluster. The maximization step calculates the likelihood estimation of clusters and formulates a loss function to make the distributions in the same cluster consistent. After training, the intra-cluster redundant filters can be trimmed and only intra-cluster diverse filters are retained. Experiments conducted on CIFAR-10 have outperformed the corresponding full models. On ImageNet ILSVRC12, FPEM reduces \(46.5\%\) FLOPs on ResNet-50 with only \(0.36\%\) Top-1 accuracy decrease, which advances the state-of-arts. In particular, the FPEM offers strong generalization performance on the object detection task.



Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.References
Denil M, Shakibi B, Dinh L, Ranzato M, De Freitas N (2013) Predicting parameters in deep learning. In: NIPS, pp 2148–2156
Denton EL, Zaremba W, Bruna J, LeCun Y, Fergus R (2014) Exploiting linear structure within convolutional networks for efficient evaluation. In: NIPS, pp 1269–1277
Ding X, Ding G, Guo Y, Han J (2019) Centripetal sgd for pruning very deep convolutional networks with complicated structure. In: CVPR, pp 4943–4953
Dong X, Huang J, Yang Y, Yan S (2017) More is less: A more complicated network with less inference complexity. In: CVPR, pp 5840–5848
Everingham M, Van Gool L, Williams CK, Winn J, Zisserman A (2010) The pascal visual object classes (voc) challenge. Int J Comput Vis 88(2):303–338
Girshick R, Donahue J, Darrell T, Malik J (2014) Rich feature hierarchies for accurate object detection and semantic segmentation. In: CVPR, pp 580–587
Gu J, Li C, Zhang B, Han J, Cao X, Liu J, Doermann D (2019) Projection convolutional neural networks for 1-bit cnns via discrete back propagation. In: AAAI, vol 33, pp 8344–8351
Han S, Pool J, Tran J, Dally W (2015) Learning both weights and connections for efficient neural network. In: NIPS, pp 1135–1143
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: CVPR, pp 770–778
He K, Zhang X, Ren S, Sun J (2016) Identity mappings in deep residual networks. In: ECCV, pp 630–645
He Y, Kang G, Dong X, Fu Y, Yang Y (2018) Soft filter pruning for accelerating deep convolutional neural networks. In: IJCAI, pp 1–8
He Y, Liu P, Wang Z, Hu Z, Yang Y (2019) Filter pruning via geometric median for deep convolutional neural networks acceleration. In: CVPR, pp 4340–4349
He Y, Zhang X, Sun J (2017) Channel pruning for accelerating very deep neural networks. In: ICCV, pp 1389–1397
Hinton G, Vinyals O, Dean J (2015) Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531
Ioffe S, Szegedy C (2015) Batch normalization: Accelerating deep network training by reducing internal covariate shift. In: ICML, pp 448–456
Krizhevsky A, Hinton G et al (2009) Learning multiple layers of features from tiny images. Technical report, Citeseer
Krizhevsky A, Sutskever I, Hinton GE (2012) Imagenet classification with deep convolutional neural networks. In: NIPS, pp 1097–1105
LeCun Y, Denker JS, Solla SA (1990) Optimal brain damage. In: NIPS, pp 598–605
Li H, Kadav A, Durdanovic I, Samet H, Graf HP (2016) Pruning filters for efficient convnets. In: ICLR, pp 1–13
Li Y, Lin S, Liu J, Ye Q, Wang M, Chao F, Yang F, Ma J, Tian Q, Ji R (2021) Towards compact cnns via collaborative compression. In: CVPR, pp 6438–6447
Lin M, Ji R, Wang Y, Zhang Y, Zhang B, Tian Y, Shao L (2020) Hrank: Filter pruning using high-rank feature map. In: CVPR, pp 1529–1538
Lin M, Ji R, Zhang Y, Zhang B, Wu Y, Tian Y (2020) Channel pruning via automatic structure search. In: IJCAI, pp 1–7
Lin S, Ji R, Li Y, Deng C, Li X (2019) Toward compact convnets via structure-sparsity regularized filter pruning. IEEE Trans Neural Netw Learn Syst 31(2):574–588
Lin S, Ji R, Li Y, Wu Y, Huang F, Zhang B (2018) Accelerating convolutional networks via global & dynamic filter pruning. In: IJCAI, pp 2425–2432
Lin S, Ji R, Yan C, Zhang B, Cao L, Ye Q, Huang F, Doermann D (2019) Towards optimal structured cnn pruning via generative adversarial learning. In: CVPR, pp 2790–2799
Lin TY, Maire M, Belongie S, Hays J, Perona P, Ramanan D, Dollár P, Zitnick CL (2014) Microsoft coco: common objects in context. In: ECCV, pp 740–755
Liu J, Zhuang B, Zhuang Z, Guo Y, Huang J, Zhu J, Tan M (2021) Discrimination-aware network pruning for deep model compression. IEEE Trans Pattern Anal Mach Intell
Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu CY, Berg AC (2016) Ssd: Single shot multibox detector. In: ECCV, pp 21–37
Liu Z, Mu H, Zhang X, Guo Z, Yang X, Cheng KT, Sun J (2019) Metapruning: meta learning for automatic neural network channel pruning. In: ICCV, pp 3296–3305
Luo JH, Wu J, Lin W (2017) Thinet: A filter level pruning method for deep neural network compression. In: ICCV, pp 5058–5066
Nair V, Hinton GE (2010) Rectified linear units improve restricted boltzmann machines. In: ICML, pp 807–814
Rastegari M, Ordonez V, Redmon J, Farhadi A (2016) Xnor-net: Imagenet classification using binary convolutional neural networks. In: ECCV, pp 525–542
Romero A, Ballas N, Kahou SE, Chassang A, Gatta C, Bengio Y (2015) Fitnets: Hints for thin deep nets. In: ICLR, pp 1–13
Russakovsky O, Deng J, Su H, Krause J, Satheesh S, Ma S, Huang Z, Karpathy A, Khosla A, Bernstein M, Berg AC, Fei-Fei L (2015) Imagenet large scale visual recognition challenge. Int J Comput Vis 115(3):211–252
Simonyan K, Zisserman A (2015) Very deep convolutional networks for large-scale image recognition. In: ICLR
Wang X, Zhang B, Li C, Ji R, Han J, Cao X, Liu J (2018) Modulated convolutional networks. In: CVPR, pp 840–848
Xie Z, Zhu L, Zhao L, Tao B, Liu L, Tao W (2020) Localization-aware channel pruning for object detection. Neurocomputing 403:400–408
Xu S, Chen H, Gong X, Liu K, Lü J, Zhang B (2021) Efficient structured pruning based on deep feature stabilization. Neural Comput Appl 1–12
Xu S, Li Y, Zhao J, Zhang B, Guo G (2021) Poem: 1-bit point-wise operations based on expectation-maximization for efficient point cloud processing. In: BMVC
Xu S, Zhao J, Lu J, Zhang B, Han S, Doermann D (2021) Layer-wise searching for 1-bit detectors. In: CVPR, pp 5682–5691
Xuan G, Zhang W, Chai P (2001) Em algorithms of gaussian mixture model and hidden markov model. In: Proceedings 2001 international conference on image processing (Cat. No. 01CH37205), vol 1. IEEE, pp 145–148
Yu R, Li A, Chen CF, Lai JH, Morariu VI, Han X, Gao M, Lin CY, Davis LS (2018) Nisp: pruning networks using neuron importance score propagation. In: CVPR, pp 9194–9203
Zhang X, Zou J, Ming X, He K, Sun J (2015) Efficient and accurate approximations of nonlinear convolutional networks. In: CVPR, pp 1984–1992
Zhao J, Xu S, Zhang B, Gu J, Doermann D, Guo G (2021) Towards compact 1-bit cnns via bayesian learning. Int J Comput Vis 1–25
Acknowledgements
This study was supported by Grant NO.2019JZZY011101 from the Key Research and Development Program of Shandong Province to Dianmin Sun. This work was supported in part by the National Natural Science Foundation of China under Grant 62076016, 61876015 and 92067204.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Sheng Xu and Yanjing Li: co-first authors.
Rights and permissions
About this article

Cite this article
Xu, S., Li, Y., Yang, L. et al. Filter pruning via expectation-maximization. Neural Comput & Applic 34, 12807–12818 (2022). https://doi.org/10.1007/s00521-022-07127-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-022-07127-2