
Abstract
One of the challenges in constructing Knowledge Graphs from text is verifying the correctness of the produced results. Each language has its unique characteristics, so a Knowledge Graphs construction system may perform better on certain languages and worse on others. In order to detect the most suitable Knowledge Graph construction systems for Vietnamese, in this paper, we propose a method to classify triples extracted from such systems into two categories: Existent and Non-existent. Vietnamese is a low-resource language with limited natural language processing tools and datasets. By combining BERT with a self-constructed Vietnamese Knowledge Graph, we build a classification model to verify the existence of triples in paragraphs. Our results suggest that BERT can learn contextual relations between words from a large amount of text, even for a low-resource language like Vietnamese. BERT’s adaptive capability to detect meaningful triples is also shown and discussed. The outcome of this paper could potentially be used to build more sophisticated systems to solve Knowledge Graph construction and Triple Classification tasks in low resource languages.








Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.References
Phuc D (2019) SparkHINlog: extension of SparkDatalog for heterogeneous information network. J Intell Fuzzy Syst 37:7555–7566
Ho T, Do P (2015) Discovering communities of users on social networks based on topic model combined with Kohonen network. In: 7th international conference on knowledge and systems engineering (KSE) 2015, pp 268–273. https://doi.org/10.1109/KSE.2015.54
Wang Z, Li J (2016) Text-enhanced representation learning for knowledge graph. In: Proceedings of the 25 international joint conference on artificial intelligence (IJCAI’16). AAAI Press, pp 1293–1299
Xiao H, Huang M, Hao Y, Zhu X (2015) TransG: a generative mixture model for knowledge graph embedding
Ji G, Liu K, He S, Zhao J (2016) Knowledge graph completion with adaptive sparse transfer matrix. In: Proceedings of the 30th AAAI conference on artificial intelligence (AAAI’16). AAAI Press, pp 985–991
An B, Chen B, Han X, Sun L (2018) Accurate text-enhanced knowledge graph representation learning. NAACL
Nguyen DQ, Nguyen DQ, Nguyen TD, Phung DQ (2019) A convolutional neural network-based model for knowledge base completion and its application to search personalization. Semant Web 10:947–960
Wang H, Kulkarni V, Wang WY (2020) DOLORES: deep contextualized knowledge graph embeddings. arXiv:1811.00147
Yao L, Mao C, Luo Y (2019) KG-BERT: BERT for knowledge graph completion. arXiv:1909.03193
Do P, Le H (2021) Building a knowledge graph of Vietnam tourism from text. In: Alfred R, Iida H, Haviluddin H, Anthony P (eds) Computational science and technology. Lecture notes in electrical engineering, vol 724. Springer, Singapore. https://doi.org/10.1007/978-981-33-4069-5_1
Do PT, Phan T, Le HT, Gupta BB (2020) Building a knowledge graph by using cross-lingual transfer method and distributed MinIE algorithm on apache spark. Neural Comput Appl pp 1–17
Wang Q, Mao Z, Wang B, Guo L (2017) Knowledge graph embedding: a survey of approaches and applications. IEEE Trans Knowl Data Eng 29(12):2724–2743. https://doi.org/10.1109/TKDE.2017.2754499
Howard J, Ruder S (2018) Universal language model fine-tuning for text classification, pp 328–339. https://doi.org/10.18653/v1/P18-1031
Socher R, Chen D, Manning CD, Ng A (2013) Reasoning with neural tensor networks for knowledge base completion. In: Proceedings of the 26th international conference on neural information processing systems—Volume 1 (NIPS’13). Curran Associates Inc., Red Hook, NY, USA, pp 926–934
Dettmers T, Minervini P, Stenetorp P, Riedel S (2018) Convolutional 2D knowledge graph embeddings. AAAI
Rumelhart DE, Hinton GE, Williams RJ (1986) Learning internal representations by error propagation. Parallel distributed processing: explorations in the microstructure of cognition, vol. 1: foundations. MIT Press, Cambridge, MA, USA, pp 318–362
Hochreiter S, Schmidhuber J (1997) Long short-term memory. Neural Comput 9(8):1735–1780. https://doi.org/10.1162/neco.1997.9.8.1735
Bradbury J, Merity S, Xiong C, Socher R (2017) Quasi-recurrent neural networks. arXiv:1611.01576
Yu F, Koltun V (2016) Multi-scale context aggregation by dilated convolutions. CoRR, arXiv:1511.07122
Favre B (2019) Contextual language understanding Thoughts on Machine Learning in Natural Language Processing. Computation and Language [cs.CL]. Aix-Marseille Universite
Sutskever I, Vinyals O, Le QV (2014) Sequence to sequence learning with neural networks. NIPS
Peters M, Neumann M, Iyyer M, Gardner M, Clark C, Lee K, Zettlemoyer L (2018) Deep contextualized word representations
Radford A, Narasimhan K (2018) Improving language understanding by generative pre-training
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł, Polosukhin I (2017) Attention is all you need. In: Proceedings of the 31st international conference on neural information processing systems (NIPS’17). Curran Associates Inc., Red Hook, NY, USA, pp 6000–6010
Manning C, Surdeanu, M, Bauer J, Finkel J, Bethard S, McClosky D (2014) The stanford CoreNLP natural language processing toolkit. In: Proceedings of 52nd annual meeting of the association for computational linguistics: system demonstrations. https://doi.org/10.3115/v1/P14-5010
Devlin J, Chang M, Lee K, Toutanova K (2019) BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv:1810.04805
Wu Y, Schuster M, Chen Z, Le QV, Norouzi M, Macherey W, Krikun M, Cao Y, Gao Q, Macherey K, Klingner J, Shah A, Johnson M, Liu X, Kaiser L, Gouws S, Kato Y, Kudo T, Kazawa H, Stevens K, Kurian G, Patil N, Wang W, Young C, Smith JR, Riesa J, Rudnick A, Vinyals O, Corrado GS, Hughes M, Dean J (2016) Google’s neural machine translation system: bridging the gap between human and machine translation. arXiv:1609.08144
Nguyen DQ, Nguyen A (2020). PhoBERT: pre-trained language models for Vietnamese. pp 1037–1042. https://doi.org/10.18653/v1/2020.findings-emnlp.92
Clark K, Luong M, Le QV, Manning CD (2020) ELECTRA: pre-training text encoders as discriminators rather than generators. arXiv:2003.10555
Chen D, Ma Z, Wei L, Ma J, Zhu Y, Gastaldo P (2021) MTQA: text-based multitype question and answer reading comprehension model. Intell Neurosci. https://doi.org/10.1155/2021/8810366
Acknowledgements
This research is funded by Vietnam National University Ho Chi Minh City (VNU-HCMC) under Grant Number DS2020-26-01.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A Using Doccano as the annotation tool
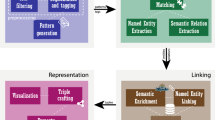
It will take some time to mark the heads, relations, and tails if they are manually retyped. Each sentence may have a different structure and complexity, and the content is often different. Doccano is a useful open-source tool that allows us to immediately and efficiently save the label form without retyping the text. Figure 9 provides an example of our data annotation process with Doccano. The text in red is the heads, the text in cyan is the predicates, and the text in green is the tail of the triples. Once we annotate a text as head or tail, they will be recommended with the same kind the next time they occur.

Example of Vietnamese description annotation
It is difficult and time-consuming to annotate on a blank document. With the help of Doccano, we can easily create labels with visual color tags for different kinds of heads, tails, or relations.
Doccano’s customization section allows users to fully configure tags that correspond to unique labels. For instance, there may be different kinds of heads, such as public figures, architecture, dishes, and so on. Likewise, there may be various forms of relation and tail. For clarification, we translated Vietnamese entities and relations to English. In our real application, all data remained in Vietnamese. Samples of a tags collection are demonstrated in Fig. 10.

Available collection of tags
Once annotated, data from Doccano will be exported as a JSON file. The data contained in the file will be processed in the Python program to extract into triples.
Appendix B Storing and visualizing the Knowledge Graph
To adapt to the raise of vast and interconnected datasets, we decided to use Neo4j. It is a graph database management system to store and handle our KG, including entities and relations of triples. By storing data using the key-value format, Neo4j was built with a highly scalable and flexible data model so that the semantic of a triple can be expressed for analysis and prediction. In our graph database, an edge is a relationship between two nodes which can be head and tail. An example of storing a triple in Neo4j is shown in Fig. 11.

Structure of triples in Neo4j
(Translation for “description” in Fig. 11: “description”: “Da Nang is a city directly under the central government, located in the South Central Coast of Vietnam, is the central and largest city in the Central region - Central Highlands.”)
Figure 11 depicts the structure of a head object, which is a node with three keys: “name”, “description”, and “viz”. The key “name” is used to query between modules in the system. A node’s “description” is a component that contributes to the classification model’s input, while “viz” aims to provide a better way for users to visualize data. In addition, tail and relation have the same format as the listed entity.

Sample graph in Neo4j
The above example shows the knowledge graph when we want to find all nodes that have any relationship with the node called “ha_noi”. The right side of Fig. 12 is the working space where we can type the query and display the graph, while the left side contains details about our database.
Our database consists of the connection of triples. Neo4j is queried with the Cypher language which aims to retrieve the graph at optimized performance. We would like to illustrate the setting up of a Cyper query and its result. An example gets all the triple with the head entity of named “ha_noi”:

Sample of Knowledge Graph
Figure 13 shows the knowledge graph with the center node named “ha_noi” and three separate types of relations: co_dac_san (has_special_dish), co_le_hoi (has_festival) and toa_lac_tai (located_in).
The knowledge graph visualization is also an efficient way to assess the quality of the classification model since it is simple to display all the connections between entities through various relations. The user can then perform a preliminary evaluation of the accuracy of the triple classification results.
Appendix C Web Application
For the intent of presenting the model result as well as visualization outcomes, we aim to build a web application that executes two main functions, which are visualization and model classification. There are several steps involved in the creation of our web application, the pipeline is depicted in Fig. 14 as follows:

Application pipeline
In the above figure, the user first selects an input (triple) under text format from an available generated list. The triple and its related nodes can be used to visualize- the branch (1). The existence of triple is returned as a result of KG-BERT model and is verified based on its description - the branch (2).
Visualization: In this phase, we show the semantic of triples with KG. We used an open-source tool named NeoViz to query the corresponding triples from Neo4j and visualize them with the connected nodes. We have the Cypher sentence ready to be queried as soon as the input value is the selected head, relation, and tail. The result is a graph similar to those found in Neo4j software that is visualized in the web version to model data relationships between related entities.
Model Classification: from the input data, we query the corresponding description of each entity and relation. The description is pre-processed into a sequence of tokens index using the algorithm described in Sect. 4.4. We displayed on the screen that a triple is exist or not and the user can verify it based on the description at the bottom of the interface. Components in this function is connected via Flask API and then we deploy an application to Docker to avoid the conflict between different machines.
Verification: We verify classification result from the model, and we evaluate the model in Sect. 5.
Rights and permissions
About this article

Cite this article
Do, P., Le, H., Pham, A.B. et al. Using BERT and Knowledge Graph for detecting triples in Vietnamese text. Neural Comput & Applic 34, 17999–18013 (2022). https://doi.org/10.1007/s00521-022-07439-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-022-07439-3