
Abstract
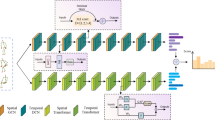
Human action recognition (HAR) is one of the active research areas in computer vision. Although significant progress has been made in the field of action recognition in recent years, most research methods focus on classification of action through single type of data, and with a need to explore spatial–temporal features systematically. Therefore, this paper proposes a three-stream spatial–temporal network with appearance and skeletal information learning for action recognition, briefly coined as 3 s-STNet, which aims to fully learn action spatial–temporal features by extracting, learning and fusing different types of data. The method is divided into two consecutive stages; the first stage uses spatial–temporal graph convolutional network (ST-GCN) and two Res2Net-101 to extract the spatial–temporal features of the action from the spatial–temporal graph, RGB appearance image, and tree-structure-reference-joints image (TSRJI), respectively. The spatial–temporal graph and TSRJI image are converted from human skeleton data. The second stage fine-tunes and fuses the spatial–temporal features obtained by the independent learning of the three-stream network to make full use of the complementarity and diversity among the three output features. The action recognition method proposed in this paper is tested on the challenging NTU RGB + D 60 and NTU RGB + D 120 dataset, and the accuracy of 97.63% (cross-subject), 99.30% (cross-view) and 95.17% (cross-subject), 96.20%(cross-setup), respectively, are obtained, which achieves the state-of-the-art action recognition results in our experiments.








Similar content being viewed by others

Explore related subjects
Discover the latest articles and news from researchers in related subjects, suggested using machine learning.References
Yan S, Xiong Y, Lin D (2018) April. Spatial temporal graph convolutional networks for skeleton-based action recognition. In: Proceedings of the AAAI conference on artificial intelligence (Vol. 32, No. 1).
Peng W, Hong X, Chen H, Zhao G (2020) Learning graph convolutional network for skeleton-based human action recognition by neural searching. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol 34, No. 03, pp. 2669–2676.
Zhang P, Lan C, Xing J, Zeng W, Xue J, Zheng N (2019) View adaptive neural networks for high performance skeleton-based human action recognition. IEEE Trans Pattern Anal Mach Intell 41(8):1963–1978
Li Y, Ji B, Shi X, Zhang J, Kang B, Wang L (2020) Tea: Temporal excitation and aggregation for action recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 909–918.
Sudhakaran S, Escalera S, Lanz O (2020) Gate-shift networks for video action recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 1102–1111.
Abdelbaky A,, Aly S (2020) Human action recognition using short-time motion energy template images and PCANet features. Neural Comput Appl, 1–14.
Li Y, Xia R, Liu X, Huang Q (2019) Learning shape-motion representations from geometric algebra spatio-temporal model for skeleton-based action recognition. In: 2019 IEEE international conference on multimedia and Expo (ICME) (pp. 1066–1071). IEEE, New York.
Caetano C, Sena J, Brémond F, Dos Santos JA, Schwartz WR (2019) Skelemotion: a new representation of skeleton joint sequences based on motion information for 3d action recognition. In: 2019 16th IEEE international conference on advanced video and signal based surveillance (AVSS) (pp. 1–8). IEEE, New York.
Caetano C, Brémond F, Schwartz WR (2019) Skeleton image representation for 3d action recognition based on tree structure and reference joints. In: 2019 32nd SIBGRAPI conference on graphics, patterns and images (SIBGRAPI) (pp. 16–23). IEEE, New York.
Fang L, Wu G, Kang W et al (2019) Feature covariance matrix-based dynamic hand gesture recognition[J]. Neural Comput Appl 31(12):8533–8546
Zheng W, Li L, Zhang Z, Huang Y, Wang L (2019) Relational network for skeleton-based action recognition. In: 2019 IEEE International conference on multimedia and Expo (ICME) (pp. 826–831). IEEE, New York
Li S, Li W, Cook C, Zhu C, Gao Y (2018) Independently recurrent neural network (indrnn): Building a longer and deeper rnn. In: Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 5457–5466).
Gao SH, Cheng MM, Zhao K, Zhang XY, Yang MH, Torr P (2019) Res2net: A new multi-scale backbone architecture. IEEE Trans Pattern Anal Mach Intell 43(2):652–662.
Karpathy A, Toderici G, Shetty S, Leung T, Sukthankar R, Fei-Fei L (2014) Large-scale video classification with convolutional neural networks. In: Proceedings of the IEEE conference on Computer Vision and Pattern Recognition (pp. 1725–1732).
Gan C, Wang N, Yang Y et al (2015) Devnet: A deep event network for multimedia event detection and evidence recounting. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 2568–2577.
Lin J, Gan C, Han S (2019) TSM: temporal shift module for efficient video understanding. In: Proceedings of the 17th IEEE International Conference on Computer Vision, Seoul, Oct 7–Nov 2, 2019. Piscataway: IEEE, 2019: 7083–7093.
Ji S, Xu W, Yang M, Yu K (2012) 3D convolutional neural networks for human action recognition. IEEE Trans Pattern Anal Mach Intell 35(1):221–231
Lu X, Yao H, Zhao S, Sun X, Zhang S (2019) Action recognition with multi-scale trajectory-pooled 3D convolutional descriptors. Multimedia Tools Appl 78(1):507–523
Feichtenhofer C (2020) X3d: Expanding architectures for efficient video recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern Recognition, pp 203–213.
Simonyan K, Zisserman A (2014) Two-stream convolutional networks for action recognition in videos. arXiv preprint arXiv:1406.2199.
Feichtenhofer C, Fan H, Malik J et al (2019) Slowfast networks for video recognition. In: Proceedings of the IEEE/CVF international conference on computer vision, pp 6202–6211.
Chéron G, Laptev I, Schmid C (2015) P-cnn: Pose-based cnn features for action recognition. In: Proceedings of the IEEE international conference on computer vision, pp. 3218–3226.
Wang H, Wang L (2017) Modeling temporal dynamics and spatial configurations of actions using two-stream recurrent neural networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 499–508).
Liu J, Shahroudy A, Xu D, Kot AC, Wang G (2017) Skeleton-based action recognition using spatio-temporal LSTM network with trust gates. IEEE Trans Pattern Anal Mach Intell 40(12):3007–3021
Li C, Xie C, Zhang B, Han J, Zhen X, Chen J (2021) Memory attention networks for skeleton-based action recognition. IEEE Trans Neural Netw Learn Syst 33(9):4800–4814. https://doi.org/10.1109/TNNLS.2021.3061115.
Si C, Chen W, Wang W, Wang L, Tan T (2019) An attention enhanced graph convolutional lstm network for skeleton-based action recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 1227–1236).
Shi L, Zhang Y, Cheng J, Lu H (2019) Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 12026–12035).
Kipf TN, Welling M (2016) Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907.
Yang Z, Li Y, Yang J, Luo J (2018) Action recognition with spatio–temporal visual attention on skeleton image sequences. IEEE Trans Circuits Syst Video Technol 29(8):2405–2415
Ke Q, Bennamoun M, An S, Sohel F, Boussaid F (2017) A new representation of skeleton sequences for 3d action recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3288–3297).
Shahroudy A, Liu J, Ng TT, Wang G (2016) Ntu rgb+ d: A large scale dataset for 3d human activity analysis. In: Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1010–1019).
Liu J, Shahroudy A, Perez M, Wang G, Duan LY, Kot AC (2019) Ntu rgb+ d 120: A large-scale benchmark for 3d human activity understanding. IEEE Trans Pattern Anal Mach Intell 42(10):2684–2701
Xie S, Girshick R, Dollár P et al (2017) Aggregated residual transformations for deep neural networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp 1492–1500.
Das S, Dai R, Yang D, Bremond F (2021) VPN++: Rethinking Video-Pose embeddings for understanding Activities of Daily Living. arXiv preprint arXiv:2105.08141.
Baradel F, Wolf C, Mille J (2017) Human action recognition: Pose-based attention draws focus to hands. In: Proceedings of the IEEE International conference on computer vision workshops (pp. 604–613).
Baradel F, Wolf C, Mille J (2018) Human activity recognition with pose-driven attention to rgb. In: BMVC 2018–29th British Machine Vision Conference (pp. 1–14).
Liu M, Yuan J (2018) Recognizing human actions as the evolution of pose estimation maps. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 1159–1168).
Shi L, Zhang Y, Cheng J, Lu H (2019) Skeleton-based action recognition with directed graph neural networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 7912–7921).
Das S, Dai R, Koperski M, Minciullo L, Garattoni L Bremond F, Francesca G (2019) Toyota smarthome: Real-world activities of daily living. In: Proceedings of the IEEE/CVF international conference on computer vision (pp. 833–842).
Das S, Chaudhary A, Bremond F, Thonnat M (2019) Where to focus on for human action recognition? In: 2019 IEEE Winter Conference on Applications of Computer Vision (WACV) (pp. 71–80). IEEE, New York.
Liu Z, Zhang H, Chen Z, Wang Z, Ouyang W (2020) Disentangling and unifying graph convolutions for skeleton-based action recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 143–152).
Das S, Sharma S, Dai R, Bremond F, Thonnat M (2020) Vpn: Learning video-pose embedding for activities of daily living. In: European conference on computer vision (pp. 72–90). Springer, Cham.
Ziyu Liu, Hongwen Zhang, Zhenghao Chen, Zhiyong Wang, Wanli Ouyang (2020) Disentangling and unifying graph convo-lutions for skeleton-based action recognition. In: Proceedings ofthe IEEE/CVF conference on computer vision and pattern recognition, p. 143–152
Liu J, Wang G, Hu P, Duan LY, Kot AC (2017) Global context-aware attention lstm networks for 3d action recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1647–1656).
Carreira J, Zisserman A (2017) Quo vadis, action recognition? a new model and the kinetics dataset. In: proceedings of the IEEE conference on computer vision and pattern recognition (pp. 6299–6308).
Yang H, Yan D, Zhang L, Li D, Sun Y, You S, Maybank SJ (2020) Feedback graph convolutional network for skeleton-based action recognition. arXiv preprint arXiv:2003.07564.
Chen Z, Li S, Yang B, Li Q, Liu H (2021) Multi-scale spatial temporal graph convolutional network for skeleton-based action recognition. In: Proceedings of the AAAI conference on artificial intelligence (Vol. 35, No. 2, pp. 1113–1122).
Cheng K, Zhang Y, He X et al (2020) Skeleton-based action recognition with shift graph convolutional network. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 183–192.
Friji Rasha, Hassen Drira, Faten Chaieb, Hamza Kchok, Sebastian Kurtek (2021) Geometric deep neural network using rigid and non-rigid transformations for human action recognition. In: Proceedings of the IEEE/CVF international conference on computer vision, pp. 12611–12620.
Acknowledgements
This work is supported partially by the National Natural Science Foundation of China under the Grant 62277009, the project of Jilin Provincial Science and Technology Department under the Grant 20180201003GX, the project of Jilin province development and reform commission under the Grant 2022C047-5. The authors gratefully acknowledge the helpful comments and suggestions of the reviewers, which have improved the presentation. The authors gratefully acknowledge the helpful comments and suggestions of the reviewers, which have improved the presentation.
Funding
This work was supported by the project of Changchun Municipal Science and Technology Bureau under the Grant 21ZY31.
Author information
Authors and Affiliations
Contributions
This study was completed by the co-authors. SL conceived the research. The major experiments and analyses were undertaken by MF and SP. YZ and HY were responsible for data processing and drawing figures. C-CH edited and reviewed the paper. All authors have read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
Authors declare no conflicts of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Fang, M., Peng, S., Zhao, Y. et al. 3 s-STNet: three-stream spatial–temporal network with appearance and skeleton information learning for action recognition. Neural Comput & Applic 35, 1835–1848 (2023). https://doi.org/10.1007/s00521-022-07763-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-022-07763-8