
Abstract
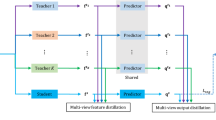
Current state-of-the-art semantic segmentation models achieve great success. However, their vast model size and computational cost limit their applications in many real-time systems and mobile devices. Knowledge distillation is one promising solution to compress the segmentation models. However, the knowledge from a single teacher may be insufficient, and the student may also inherit bias from the teacher. This paper proposes a multi-teacher ensemble distillation framework named MTED for semantic segmentation. The key idea is to effectively transfer the comprehensive knowledge from multiple teachers to one student. We present one multi-teacher output-based distillation loss to effectively distill the valuable knowledge in output probabilities to the student. We construct one adaptive weight assignment module to dynamically assign different weights to different teachers at each pixel. In addition, we introduce one multi-teacher feature-based distillation loss to transfer the comprehensive knowledge in the feature maps efficiently. We conduct extensive experiments on three benchmark datasets, Cityscapes, CamVid, and Pascal VOC 2012. The results show that the proposed MTED performs much better than the single-teacher methods on three datasets, e.g., Cityscapes, CamVid, and Pascal VOC 2012.









Similar content being viewed by others


Data availability
Cityscapes: https://www.cityscapes-dataset.com/, CamVid: http://mi.eng.cam.ac.uk/research/projects/VideoRec/CamVid/, Pascal VOC 2012:http://pjreddie.com/media/files/VOC2012test.
Code availability
We will public the code in the future.
References
Adriana R, Nicolas B, Samira EK, Antoine C, Carlo G, Yoshua B (2015) Fitnets: Hints for thin deep nets. In: Proceedings of the international conference on learning representations (ICLR). http://arxiv.org/abs/1412.6550
Amirkhani A, Khosravian A, Masih-Tehrani M, Kashiani H (2021) Robust semantic segmentation with multi-teacher knowledge distillation. IEEE Access 9:119049–119066
An S, Liao Q, Lu Z, Xue J (2022) Efficient semantic segmentation via self-attention and self-distillation. IEEE Trans Intell Transp Syst 23(9):15256–15266. https://doi.org/10.1109/TITS.2021.3139001
Bhardwaj R, Majumder N, Poria S (2021) Investigating gender bias in BERT. Cogn Comput 13(4):1008–1018. https://doi.org/10.1007/s12559-021-09881-2
Chen LC, Papandreou G, Kokkinos I, Murphy K, Yuille AL (2018) Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans Pattern Anal Mach Intell 40(4):834–848
Chen LC, Papandreou G, Schroff F, Adam H (2017) Rethinking atrous convolution for semantic image segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR)
Cheng B, Collins MD, Zhu Y, Liu T, Huang TS, Adam H, Chen L (2020) Panoptic-deeplab: A simple, strong, and fast baseline for bottom-up panoptic segmentation. In: 2020 IEEE/CVF conference on computer vision and pattern recognition, CVPR 2020, Seattle, WA, USA, June 13–19, 2020, pp. 12472–12482. Computer Vision Foundation / IEEE. 10.1109/CVPR42600.2020.01249
Cordts M, Omran M, Ramos S, Rehfeld T, Enzweiler M, Benenson R, Franke U, Roth S, Schiele B (2016) The cityscapes dataset for semantic urban scene understanding. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp 3213–3223
Deng J, Pan Y, Yao T, Zhou W, Li H, Mei T (2019) Relation distillation networks for video object detection. In: 2019 IEEE/CVF international conference on computer vision, ICCV 2019, Seoul, Korea (South), October 27 - November 2, 2019, pp 7022–7031. IEEE. 10.1109/ICCV.2019.00712
Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, Unterthiner T, Dehghani M, Minderer M, Heigold G, Gelly S et al. (2020) An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929
Everingham M, Gool LV, Williams CKI, Winn J, Zisserman A (2010) The pascal visual object classes (voc) challenge. Int J Comput Vis 88(2):303–338. https://doi.org/10.1007/s11263-009-0275-4
Feng Y, Sun X, Diao W, Li J, Gao X (2021) Double similarity distillation for semantic image segmentation. IEEE Trans Image Process 30:5363–5376. https://doi.org/10.1109/TIP.2021.3083113
Fu J, Liu J, Tian H, Li Y, Bao Y, Fang Z, Lu H (2019) Dual attention network for scene segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp 3146–3154
Han S, Pool J, Tran J, Dally WJ (2015) Learning both weights and connections for efficient neural network. In: Cortes C, Lawrence ND, Lee DD, Sugiyama M, Garnett R (eds) Proceedings of the conference on neural information processing systems (NIPS), pp 1135–1143. https://proceedings.neurips.cc/paper/2015/hash/ae0eb3eed39d2bcef4622b2499a05fe6-Abstract.html
Hariharan B, Arbeláez P, Bourdev L, Maji S, Malik J (2011) Semantic contours from inverse detectors. In: Proceedings of the IEEE international conference on computer vision (ICCV), pp 991–998. 10.1109/ICCV.2011.6126343
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR) pp 770–778
He T, Shen C, Tian Z, Gong D, Sun C, Yan Y (2019) Knowledge adaptation for efficient semantic segmentation. In: IEEE conference on computer vision and pattern recognition, CVPR 2019, Long Beach, CA, USA, June 16–20, 2019, pp 578–587. Computer Vision Foundation / IEEE. 10.1109/CVPR.2019.00067
Hinton G, Vinyals O, Dean J (2014) Distilling the knowledge in a neural network. In: Proceedings of the conference on neural information processing systems workshops (NIPSW)
Howard AG, Zhu M, Chen B, Kalenichenko D, Wang W, Weyand T, Andreetto M, Adam H (2017) Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv: Comp. Res. Repository abs/1704.04861
Huang G, Liu Z, van der Maaten L, Weinberger KQ (2017) Densely connected convolutional networks. Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR) pp 2261–2269
Huang Z, Wang X, Huang L, Huang C, Wei Y, Liu W (2019) Ccnet: Criss-cross attention for semantic segmentation. In: Proceedings of the IEEE international conference on computer vision (ICCV), pp 603–612
Ji D, Wang H, Tao M, Huang J, Hua X, Lu H (2022) Structural and statistical texture knowledge distillation for semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp 16855–16864. 10.1109/CVPR52688.2022.01637
Ju M, Luo J, Wang Z, Luo H (2021) Adaptive feature fusion with attention mechanism for multi-scale target detection. Neural Comput Appl 33(7):2769–2781
Li H, Xiong P, Fan H, Sun J (2019) Dfanet: Deep feature aggregation for real-time semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp 9522–9531. 10.1109/CVPR.2019.00975
Lin G, Liu F, Milan A, Shen C, Reid I (2020) Refinenet: Multi-path refinement networks for dense prediction. IEEE Trans Pattern Anal Mach Intell 42(5):1228–1242. https://doi.org/10.1109/TPAMI.2019.2893630
Liu R, Yang K, Liu H, Zhang J, Peng K, Stiefelhagen R (2022) Transformer-based knowledge distillation for efficient semantic segmentation of road-driving scenes. arXiv preprint arXiv:2202.13393
Liu Y, Chen K, Liu C, Qin Z, Luo Z, Wang J (2019) Structured knowledge distillation for semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp 2604–2613. 10.1109/CVPR.2019.00271
Liu Y, Shu C, Wang J, Shen C (2020) Structured knowledge distillation for dense prediction. IEEE Trans Pattern Anal Mach Intell
Park S, Kwak N (2020) Feature-level ensemble knowledge distillation for aggregating knowledge from multiple networks. In: Giacomo GD, Catalá A, Dilkina B, Milano M, Barro S, Bugarín A, Lang J (eds) Proceedings of the European conference on artificial intelligence (ECAI), Frontiers in Artificial Intelligence and Applications, vol 325, pp 1411–1418. IOS Press. 10.3233/FAIA200246
Paszke A, Chaurasia A, Kim S, Culurciello E (2016) Enet: A deep neural network architecture for real-time semantic segmentation. arXiv: Comp. Res. Repository abs/1606.02147
Rastegari M, Ordonez V, Redmon J, Farhadi A (2016) Xnor-net: Imagenet classification using binary convolutional neural networks. In: Leibe B, Matas J, Sebe N, Welling M (eds) Proceedings of the European conference on computer vision (ECCV), Lecture Notes in Computer Science, vol 9908, pp 525–542. Springer. 10.1007/978-3-319-46493-0_32
Ronneberger O, Fischer P, Brox T (2015) U-net: Convolutional networks for biomedical image segmentation. In: Proceedings of the medical image computing and computer-assisted intervention, pp 234–241
Sachin M, Mohammad R, Anat C, Linda S, Hannaneh H (2018) Espnet: Efficient spatial pyramid of dilated convolutions for semantic segmentation. In: Proceedings of the European conference on computer vision (ECCV), pp 552–568
Shelhamer E, Long J, Darrell T (2016) Fully convolutional networks for semantic segmentation. IEEE Trans Pattern Anal Mach Intell 39(4):640–651
Shen Z, He Z, Xue X (2019) MEAL: multi-model ensemble via adversarial learning. In: Proceedings of the AAAI conference on artificial intelligence (AAAI), pp 4886–4893. 10.1609/aaai.v33i01.33014886
Shu C, Liu Y, Gao J, Yan Z, Shen C (2021) Channel-wise knowledge distillation for dense prediction. In: Proceedings of the IEEE international conference on computer vision (ICCV), pp 5311–5320
Sun K, Xiao B, Liu D, Wang J (2019) Deep high-resolution representation learning for human pose estimation. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp 5693–5703
Tan M, Le Q (2019) Efficientnet: Rethinking model scaling for convolutional neural networks. In: Proceedings of the international conference on machine learning (ICML), pp 6105–6114. PMLR
Tian Z, Chen P, Lai X, Jiang L, Liu S, Zhao H, Yu B, Yang MC, Jia J (2022) Adaptive perspective distillation for semantic segmentation. IEEE Trans Pattern Anal Mach Intell pp 1–1. 10.1109/TPAMI.2022.3159581
Wang W, Wei F, Dong L, Bao H, Yang N, Zhou M (2020) Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers. In: Proceedings of the conference on neural information processing systems (NIPS)
Wang Y, Zhou W, Jiang T, Bai X, Xu Y (2020) Intra-class feature variation distillation for semantic segmentation. In: Proceedings of the european conference on computer vision (ECCV), pp 346–362. Springer
Wu A, Zheng W, Guo X, Lai J (2019) Distilled person re-identification: towards a more scalable system. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp 1187–1196. 10.1109/CVPR.2019.00128. http://openaccess.thecvf.com/content_CVPR_2019/html/Wu_Distilled_Person_Re-Identification_Towards_a_More_Scalable_System_CVPR_2019_paper.html
Wu C, Wu F, Huang Y (2021) One teacher is enough? pre-trained language model distillation from multiple teachers. In: Zong C, Xia F, Li W, Navigli R (eds) Proceedings of the annual meeting of the association for computational linguistics (ACL), pp 4408–4413. 10.18653/v1/2021.findings-acl.387
Wu M, Chiu C, Wu K (2019) Multi-teacher knowledge distillation for compressed video action recognition on deep neural networks. In: Proceedings of the IEEE international conference on acoustics, speech and signal processing, pp 2202–2206. IEEE. 10.1109/ICASSP.2019.8682450
Xie E, Wang W, Yu Z, Anandkumar A, Alvarez JM, Luo P (2021) Segformer: Simple and efficient design for semantic segmentation with transformers. In: Proceedings of the conference on neural information processing systems (NIPS), pp 12077–12090. https://proceedings.neurips.cc/paper/2021/hash/64f1f27bf1b4ec22924fd0acb550c235-Abstract.html
Yang C, Zhou H, An Z, Jiang X, Xu Y, Zhang Q (2022) Cross-image relational knowledge distillation for semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp 12319–12328
Yang K, Hu X, Fang Y, Wang K, Stiefelhagen R (2022) Omnisupervised omnidirectional semantic segmentation. IEEE Trans Intell Transp Syst 23(2):1184–1199. https://doi.org/10.1109/TITS.2020.3023331
Yang M, Yu K, Zhang C, Li Z, Yang K (2018) Denseaspp for semantic segmentation in street scenes. In: 2018 IEEE conference on computer vision and pattern recognition, CVPR 2018, Salt Lake City, UT, USA, June 18–22, 2018, pp 3684–3692. 10.1109/CVPR.2018.00388
Yu C, Wang J, Peng C, Gao C, Yu G, Sang N (2018) Bisenet: Bilateral segmentation network for real-time semantic segmentation. In: Proceedings of the European conference on computer vision (ECCV), pp 325–341
Yu F, Koltun V (2016) Multi-scale context aggregation by dilated convolutions. In: Proceedings of the international conference on learning representations (ICLR)
Yuan Y, Chen X, Wang J (2020) Object-contextual representations for semantic segmentation. In: Proceedings of the European conference on computer vision (ECCV), pp 173–190
Zagoruyko S, Komodakis N (2017) Paying more attention to attention: improving the performance of convolutional neural networks via attention transfer. In: Proceedings of the international conference on learning representations (ICLR). https://openreview.net/forum?id=Sks9_ajex
Zhang J, Yang K, Constantinescu A, Peng K, Müller K, Stiefelhagen R (2022) Trans4trans: Efficient transformer for transparent object and semantic scene segmentation in real-world navigation assistance. IEEE Trans Intell Transp Syst 23(10):19173–19186. https://doi.org/10.1109/TITS.2022.3161141
Zhang W, Huang Z, Luo G, Chen T, Wang X, Liu W, Yu G, Shen C (2022) Topformer: Token pyramid transformer for mobile semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp 12073–12083. IEEE. 10.1109/CVPR52688.2022.01177
Zhang X, Du B, Wu Z, Wan T (2022) Laanet: lightweight attention-guided asymmetric network for real-time semantic segmentation. Neural Comput Appl 34(7):3573–3587
Zhang X, Zhou X, Lin M, Sun J (2018) Shufflenet: An extremely efficient convolutional neural network for mobile devices. Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR) pp 6848–6856
Zhang Z, Zhou C, Tu Z (2022) Distilling inter-class distance for semantic segmentation. In: Raedt LD (ed) Proceedings of the international joint conference on artificial intelligence (IJCAI), pp 1686–1692. ijcai.org. 10.24963/ijcai.2022/235
Zhao H, Qi X, Shen X, Shi J, Jia J (2018) Icnet for real-time semantic segmentation on high-resolution images. In: Proceedings of the European conference on computer vision (ECCV), pp 405–420
Zhao H, Shi J, Qi X, Wang X, Jia J (2017) Pyramid scene parsing network. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp 2881–2890. 10.1109/CVPR.2017.660
Zheng S, Lu J, Zhao H, Zhu X, Luo Z, Wang Y, Fu Y, Feng J, Xiang T, Torr PHS, Zhang L (2021) Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), pp 6881–6890. 10.1109/CVPR46437.2021.00681
Acknowledgements
The authors thank Dingding Chen, Fengyuan Shi, and Ganghong Huang for their great helps with codes, suggestions, and discussion.
Funding
This work is partially supported by the National Natural Science Foundation of China (62176029 and 61876026), the Project supported by graduate scientific research and innovation foundation of Chongqing, China (CYS21061), the National Key Research and Development Program of China (2017YFB1402401), and the Key Research Program of Chongqing Science and Technology Bureau (cstc2020jscx-msxmX0149).
Author information
Authors and Affiliations
Contributions
CW contribute to conceptualization, methodology, software, and original draft writing. JZ contributes to conceptualization, supervision, resources, and funding acquisition. QD contributes to original draft writing and Investigation. QY contributes to conceptualization and methodology. YQ contributes to software and validation. BF contributes to conceptualization and review. XL contributes to investigation and review.
Corresponding author
Ethics declarations
Conflict of interest
No conflicts to declare.
Ethics approval
Not Applicable.
Consent to participate
Not Applicable.
Consent for publication
Not Applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Wang, C., Zhong, J., Dai, Q. et al. MTED: multiple teachers ensemble distillation for compact semantic segmentation. Neural Comput & Applic 35, 11789–11806 (2023). https://doi.org/10.1007/s00521-023-08321-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-023-08321-6