
Abstract
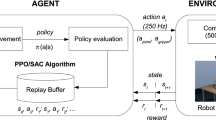
Most existing reinforcement learning (RL) algorithms are solely applied to scenarios with pure discrete action space or pure continuous action space. However, in certain real-world kinematic control tasks that involve robot control based on kinematic properties, the action space is parameterized, wherein actions are represented by a fusion of discrete actions and continuous parameters. In this paper, we propose a hierarchical RL architecture designed specifically for handling parameterized action spaces. Our architecture consists of two levels, the higher level (discrete actor network) selects the discrete action and the lower level (continuous actor networks) determines the corresponding continuous parameters. These components work in tandem to generate an action-parameters vector to interact with the environment. Both the higher and lower levels share the rewards of environmental feedback and the critic networks to update the network weights. The soft actor critic and deep deterministic policy gradient algorithms are adopted to update higher-level and lower-level policies, respectively. Through simulation experiments conducted on different kinematic control tasks with parameterized action spaces, we demonstrate the effectiveness of our proposed algorithm.







Similar content being viewed by others


Data availability
The data that support the findings of this study are available on request from the first author.
Change history
13 December 2023
A Correction to this paper has been published: https://doi.org/10.1007/s00521-023-09305-2
References
Song D, Gan W, Yao P, Zang W, Qu X (2022) Surface path tracking method of autonomous surface underwater vehicle based on deep reinforcement learning. In press, Neural Computing and Applications
Fu C, Xu X, Zhang Y, Lyu Y, Xia Y, Zhou Z, Wu W (2022) Memory-enhanced deep reinforcement learning for uav navigation in 3d environment. Neural Comput Appl 34(17):14599–14607
Sun C, Liu W, Dong L (2020) Reinforcement learning with task decomposition for cooperative multiagent systems. IEEE Transact Neural Netw Lear Syst 32(5):2054–2065
Wang Y, He H, Sun C (2018) Learning to navigate through complex dynamic environment with modular deep reinforcement learning. IEEE Transact Games 10(4):400–412
Mnih V, Kavukcuoglu K, Silver D, Graves A, Antonoglou I, Wierstra D, Riedmiller M (2013) Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602
Lillicrap T.P, Hunt J.J, Pritzel A, Heess N, Erez T, Tassa Y, Silver D, Wierstra D (2015) Continuous control with deep reinforcement learning. arXiv preprint arXiv:1509.02971
Masson W, Ranchod P, Konidaris G (2016) Reinforcement learning with parameterized actions. In: Proceedings of the AAAI conference on artificial intelligence, vol. 30, pp 1934–1940
Hausknecht M, Stone P (2016) Deep reinforcement learning in parameterized action space. In: Proceedings of the international conference on learning representations (ICLR)
Xiong J, Wang Q, Yang Z, Sun P, Han L, Zheng Y, Fu H, Zhang T, Liu J, Liu H (2018) Parametrized deep q-networks learning: reinforcement learning with discrete-continuous hybrid action space. arXiv preprint arXiv:1810.06394
Bester CJ, James SD, Konidaris GD (2019) Multi-pass q-networks for deep reinforcement learning with parameterised action spaces. arXiv preprint arXiv:1905.04388
Fu H, Tang H, Hao J, Lei Z, Chen Y, Fan C (2019) Deep multi-agent reinforcement learning with discrete-continuous hybrid action spaces. In: Twenty-Eighth international joint conference on artificial intelligence IJCAI-19
Zhang X, Jin S, Wang C, Zhu X, Tomizuka M (2022) Learning insertion primitives with discrete-continuous hybrid action space for robotic assembly tasks. In: 2022 International conference on robotics and automation (ICRA), pp 9881–9887 . IEEE
Zheng Q, Wang D, Chen Z, Sun Y, Liang B (2022) Continuous reinforcement learning based ramp jump control for single-track two-wheeled robots. Transact Instit Meas Control 44(4):892–904
Lombardi M, Liuzza D, Bernardo M (2021) Using learning to control artificial avatars in human motor coordination tasks. IEEE Transact Robot 37(6):2067–2082
Mohammadi M, Arefi MM, Vafamand N, Kaynak O (2022) Control of an auv with completely unknown dynamics and multi-asymmetric input constraints via off-policy reinforcement learning. In press, Neural Computing and Applications
Alpdemir MN (2022) Tactical uav path optimization under radar threat using deep reinforcement learning. Neural Comput Appl 34(7):5649–5664
Ma J, Wu F (2020) Feudal multi-agent deep reinforcement learning for traffic signal control. In: Proceeding of the 19th international conference on autonomous agents and multiagent systems(AAMAS), pp 816–824
Pateria S, Subagdja B, Tan AH, Chai Q (2022) End-to-end hierarchical reinforcement learning with integrated subgoal discovery. IEEE Transact Neural Netw Learn Syst 33(12):7778–7790
Dilokthanakul N, Kaplanis C, Pawlowski N, Shanahan M (2019) Feature control as intrinsic motivation for hierarchical reinforcement learning. IEEE Transact Neural Netw Learn Syst 30(11):3409–3418
Bougie N, Ichise R (2021) Fast and slow curiosity for high-level exploration in reinforcement learning. Appl Intell 51(2):1086–1107
Ren T, Niu J, Liu X, Wu J, Zhang Z (2020) An efficient model-free approach for controlling large-scale canals via hierarchical reinforcement learning. IEEE Transact Indus Inform 17(6):4367–4378
Yang Z, Merrick K, Jin L, Abbass HA (2018) Hierarchical deep reinforcement learning for continuous action control. IEEE Transact Neural Netw Learn Syst 29(11):5174–5184
Nachum O, Gu S, Lee H, Levine S (2018) Data-efficient hierarchical reinforcement learning. arXiv preprint arXiv:1805.08296
Devo A, Mezzetti G, Costante G, Fravolini ML, Valigi P (2020) Towards generalization in target-driven visual navigation by using deep reinforcement learning. IEEE Transact Robot 36(5):1546–1561
Whlke J, Schmitt F, Hoof H.V (2021) Hierarchies of planning and reinforcement learning for robot navigation. In: 2021 IEEE international conference on robotics and automation (ICRA), pp 10682–10688
Christen S, Jendele L, Aksan E, Hilliges O (2021) Learning functionally decomposed hierarchies for continuous control tasks with path planning. IEEE Robot Autom Lett 6(2):3623–3630
Bigazzi R, Landi F, Cascianelli S, Baraldi L, Cornia M, Cucchiara R (2022) Focus on impact: indoor exploration with intrinsic motivation. IEEE Robot Autom Lett 7(2):2985–2992
Xia F, Li C, Martín-Martín R, Litany O, Toshev A, Savarese S (2021) Relmogen: Leveraging motion generation in reinforcement learning for mobile manipulation. In: 2021 international conference on robotics and automation (ICRA)
Liu C, Zhu F, Liu Q, Fu Y (2021) Hierarchical reinforcement learning with automatic sub-goal identification. IEEE/CAA J Autom Sin 8(10):1686–1696
Yang X, Ji Z, Wu J, Lai YK, Setchi R (2022) Hierarchical reinforcement learning with universal policies for multistep robotic manipulation. IEEE Transact Neural Netw Learn Syst 33(9):4727–4741
Peng X.B, Chang M, Zhang G, Abbeel P, Levine S (2019) Mcp: Learning composable hierarchical control with multiplicative compositional policies. In: Proc. NIPS, pp 3681–3692
Howard RA (1960) Dynamic programming and markov processes. Math Gazette 3(358):120
Haarnoja T, Zhou A, Abbeel P, Levine S (2018) Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In: International conference on machine learning, pp 1861–1870. PMLR
Haarnoja T, Zhou A, Abbeel P, Levine S (2019) Soft actor-critic algorithm and applications. arXiv preprint arXiv:1812.05905
Christodoulou P (2019) Soft actor-critic for discrete action settings. arXiv preprint arXiv:1910.07207
Bellman R (1966) Dynamic programming. Science 153(3731):34–37
Paszke A, Gross S, Chintala S, Chanan G, Yang E, Devito Z, Lin Z, Desmaison A, Antiga L, Lerer A (2017) Automatic differentiation in pytorch. In: cNIPS 2017 autodiff workshop: the future of gradient-based machine learning software and techniques
Brockman G, Cheung V, Pettersson L, Schneider J, Schulman J, Tang J, Zaremba W (2016) Openai gym. arXiv preprint arXiv:1606.01540
Kitano H, M, A, Y, K, I, N (1997) Robocup : a challenge ai problem. Ai Magazine, 18–7385
Funding
The funding was supported by Key Technologies Research and Development Program of Anhui Province (Grant No. 2018AAA0101400). Innovative Research Group Project of the National Natural Science Foundation of China (Grant No. 61921004). Natural Science Research of Jiangsu Higher Education Institutions of China (Grant No. BK20202006). National Natural Science Foundation of China (Grant No. 62173251). National Natural Science Foundation of China (Grant U1713209).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
No potential conflict of interest was reported by the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original online version of this article was revised : In this article the author name “Jingyu Cao” was incorrectly written as “Jingly Cao”.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Cao, J., Dong, L. & Sun, C. Hierarchical reinforcement learning for kinematic control tasks with parameterized action spaces. Neural Comput & Applic 36, 323–336 (2024). https://doi.org/10.1007/s00521-023-08991-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-023-08991-2