
Abstract
Retinal illnesses such as age-related macular degeneration (AMD) and diabetic maculopathy pose serious risks to vision in the developed world. The diagnosis and assessment of these disorders have undergone revolutionary change with the development of optical coherence tomography (OCT). This study proposes a novel method for improving clinical precision in retinal disease diagnosis by utilizing the strength of Attention-Based DenseNet, a deep learning architecture with attention processes. For model building and evaluation, a dataset of 84495 high-resolution OCT images divided into NORMAL, CNV, DME, and DRUSEN classes was used. Data augmentation techniques were employed to enhance the model's robustness. The Attention-Based DenseNet model achieved a validation accuracy of 0.9167 with a batch size of 32 and 50 training epochs. This discovery presents a promising route for more precise and speedy identification of retinal illnesses, ultimately enhancing patient care and outcomes in clinical settings by integrating cutting-edge technology with powerful neural network architectures.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Retinal diseases, like age-related macular degeneration and diabetic retinopathy, are major causes of vision loss globally. Optical coherence tomography (OCT) has transformed retinal diagnosis by offering detailed, noninvasive images. There is a need for even greater diagnostic accuracy to improve patient outcomes. Existing OCT diagnostic methods often struggle to generalize across different clinical situations. Our model aims to address this by using advanced deep learning techniques to enhance diagnostic precision.
Despite the significant advancements in OCT technology, there remains a pressing need to improve diagnostic accuracy. Current OCT-based methods, while effective in many cases, may struggle to generalize across diverse patient populations and clinical scenarios. Factors such as variations in image quality, differences in disease progression, and the presence of confounding factors can hinder the reliability of diagnostic outcomes.
To address these challenges, our research focuses on leveraging advanced deep learning techniques to enhance the precision of OCT-based retinal disease diagnosis. By incorporating attention mechanisms into our deep learning model, we aim to improve feature extraction from OCT images, enabling more accurate differentiation between various retinal conditions. Our approach is designed to capture subtle patterns and variations within the retinal structures, leading to more reliable and consistent diagnostic results.
With the development of OCT in the twenty-first century, it became possible to identify macular diseases and evaluate the necessity and effectiveness of therapies [1]. OCT is a noninvasive diagnostic technique that uses infrared light with a wavelength of 800–840 nm to provide retinal imaging in real time at high resolution. When using state-of-the-art equipment, spectral domain-OCT (SD-OCT) may acquire retinal pictures at rates of up to 20000 axial scans per second with a resolution of 1.3–2.7 μm [2], 3.
In the developed world, age-related macular degeneration (AMD) and diabetic maculopathy are the most prevalent causes of vision loss in addition to glaucoma [4, 5]. Although AMD often develops unilaterally at first, 50% of individuals experience the illness in the unaffected fellow eye within three years [6]. Drusen are extracellular materials that are either on the retinal pigment epithelium (RPE) or the sub-RPE and are thought to be a precursor lesion to progressive AMD. They contain numerous proteins linked to inflammation and lipids [7].
Diabetes can induce diabetic retinopathy (DR), which has an impact on the tiny blood vessels in the retina, leading to the loss of pericytes, degradation of endothelial cells, and increased permeability of the capillaries. These changes occur gradually and may not manifest any early symptoms [8]. It is essential to undergo regular eye examinations to detect and treat DR at an early stage. Retinal photography is a recognized method for screening DR, and manual interpretation of the images has shown better results compared to dilated eye exams. Seeking timely treatment can prevent permanent vision loss, which is why regular eye exams are highly recommended for individuals with long-term diabetes [9].
Age-related macular degeneration (AMD) is associated with drusen, long-spaced collagen, and phospholipid vesicles. Between the basement membrane of the retinal pigment epithelium and the remaining Bruch membrane, these structures are present [10,11,12].
The main factor contributing to visual loss or impairment in working-age and older persons around the world is these lesions [13, 14]. It can take a lot of effort and training to correctly identify retinopathy and maculopathy.
Regarding clinical picture analysis and illness detection, artificial intelligence (AI), in which training data are utilized to construct a system, has grown in popularity [15,16,17,18,19,20]. Despite the fact that the use and development of AI in medicine are still in their infancy, the US Food and Drug Administration has approved a device based on AI to diagnose DR [21]. The best choice boundary in a multidimensional feature space is determined by computer algorithms to solve the existing constraints of auxiliary inspection techniques [22]. Researchers are now working to improve such systems.
Research Gap While OCT has transformed the field of diagnosing retinal diseases today, there is a significant research gap in reaching even higher clinical precision. Although successful, current procedures can be improved by incorporating cutting-edge AI tools to better diagnose and categorize retinal illnesses.
The Solution Our study offers a ground-breaking remedy in the shape of an Attention-Based DenseNet model to fill this research gap. The analysis and detection of retinal illnesses using OCT pictures have been greatly improved thanks to the inclusion of attention mechanisms in this deep learning architecture. We want to provide a revolutionary strategy that can change the clinical accuracy of retinal disease diagnosis by utilizing the capabilities of our cutting-edge AI model.
The Importance This study is significant because it has the potential to completely alter ophthalmology. We want to improve the precision and efficacy of retinal disease diagnostics by combining cutting-edge technologies with potent neural network architectures. The significance of this work transcends the boundaries of research since it has the potential to enhance clinical results, patient care, and quality of life for those who suffer from retinal illnesses.
The main contributions in this paper are:
-
Introducing Attention-Based DenseNet In this section, we describe the use of an Attention-Based DenseNet model for enhancing OCT image analysis. This model makes use of attentional mechanisms to improve the accuracy of the diagnosis.
-
Integration of a Large Dataset We make use of a sizable dataset made up of 84495 high-resolution OCT pictures that have been divided into NORMAL, CNV, DME, and DRUSEN classes. This dataset, which provides a realistic portrayal of clinical events, is essential to the training and assessment of our model.
-
High Validation Accuracy Attained The validation accuracy of 0.9167 for our suggested Attention-Based DenseNet model is astounding. The model has the potential to considerably increase the precision of diagnosing retinal diseases, as evidenced by the high degree of accuracy.
-
Augmentation approaches for Data resilience To increase the model's resilience and ensure that it can cope with the variability present in clinical OCT pictures, we use augmentation approaches for data.
-
Potential for Improved Clinical Care This research's most important contribution is the promise it holds for quicker and more accurate diagnosis of retinal diseases. We want to improve the standard of patient care and clinical results in the diagnosis and treatment of retinal diseases by increasing the state of the art.
The remaining work is structured as follows: Sect. 2 provides an overview of recent research conducted in the field of OCT. Section 3 introduces the proposed framework for this study. In Sect. 4, the experimental evaluation conducted is presented. Finally, Sect. 5 serves as the conclusion, summarizing the key findings and concluding the research effort.
2 Related work
Deep learning and attention mechanisms have demonstrated significant potential to enhance clinical accuracy and efficiency in ophthalmology, particularly in the context of retinal disease diagnosis. Attention-Based DenseNet models, in particular, are poised to revolutionize patient care by providing more accurate and timely diagnostic outcomes.
Akinniyi et al. [23] developed a multi-stage classification network for retinal image classification using OCT images. Their approach, which employed a scale-adaptive neural network and a feature-rich pyramidal architecture, effectively extracted multi-scale features from the images. This led to impressive classification accuracies of 97.78%, 96.83%, and 94.26% for the first, second, and all-at-once stages, respectively.
Jin et al. [24] introduced a novel aggregation channel attention network for semantic segmentation. By incorporating context information and balancing the contributions of dice coefficients and cross-entropy loss, their network significantly improved performance in small area segmentation. This enabled more accurate feature restoration and enhanced prediction efficiency.
Yu et al. [25] also proposed an aggregation channel attention network for semantic segmentation. Their approach, similar to Jin et al.'s, focused on improving performance in small area segmentation by utilizing context information and balancing loss functions. Experimental results demonstrated enhanced prediction performance and computational efficiency.
Ma et al. [26] presented a hybrid ConvNet-Transformer network (HCTNet) for retinal OCT image classification. HCTNet, which combines the strengths of convolutional neural networks and transformers, achieved an overall accuracy of 91.56% and 86.18% on two public retinal OCT datasets, outperforming purely convolutional or transformer-based methods.
Mora et al. [27] introduced a new fully convolutional network (FCN) architecture called LOCTSeg for semantic segmentation of OCT images. LOCTSeg, designed for optimal performance and efficiency, demonstrated competitive inference speed without sacrificing segmentation accuracy. The algorithm was evaluated on both public and private datasets, achieving state-of-the-art Dice scores and outperforming other lightweight FCNs on ERM segmentation.
Souid et al. [28] also introduced LOCTSeg, a lightweight FCN optimized for semantic segmentation of OCT images. Their algorithm, which was evaluated on various datasets, achieved impressive Dice scores and outperformed other lightweight FCNs in ERM segmentation.
Table 1 provides a summary of the commonly used models for retinal disease diagnosis, including Convolutional Neural Networks (CNN), Recurrent Neural Networks (RNN), Long Short-Term Memory (LSTM), Transformers, Attention Mechanisms, and Variational Autoencoders (VAE).
Research gaps in previous algorithms can be summarized as follow:
-
Despite their promise to increase clinical precision, Attention-Based DenseNet models are only partially integrated in the diagnosis of retinal diseases.
-
There aren't many studies investigating how deep learning architectures, specifically Attention-Based DenseNet, can be applied to a large collection of high-resolution OCT pictures.
-
The requirement for more reliable and precise models for the detection and categorization of retinal illnesses such AMD, diabetic maculopathy, CNV, and drusen.
-
The lack of thorough research regarding how data augmentation methods affect Attention-Based DenseNet models' ability to diagnose retinal diseases.
-
There is a research gap that must be filled in order to better treat patients in clinical settings by accurately and quickly identifying retinal disorders.
-
Insufficient effort is put toward addressing the diagnostic difficulties in ophthalmology by merging cutting-edge technologies, such as Attention-Based DenseNet, with potent neural network topologies.
A thorough strategy can be used to fill in these research gaps. The full integration of Attention-Based DenseNet models into the diagnosis of retinal illnesses should be prioritized by researchers, who should also look at how they might improve clinical precision. The usefulness of deep learning architectures, in particular Attention-Based DenseNet, on a broad dataset of high-resolution OCT pictures should be thoroughly studied.
A major objective should be the creation of more reliable and precise models for the identification and categorization of retinal diseases, such as AMD, diabetic maculopathy, CNV, and drusen. Additionally, a full analysis of how data augmentation methods affect Attention-Based DenseNet models' ability to detect retinal disorders is required. By filling in these gaps, the research community may help clinical ophthalmology provide better patient treatment and outcomes by identifying retinal abnormalities more quickly and accurately while utilizing cutting-edge technology and potent neural network topologies.
3 OCTNet: enhanced retinal disease diagnosis with attention-based DenseNet
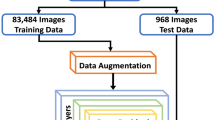
This section proposes an Enhanced Retinal Disease Diagnosis with Attention-Based DenseNet (OCTNet) Algorithm. The primary objective of OCTNet is to provide retinal disease diagnosis. The OCTNet algorithm is composed of five main phases, as depicted in Fig. 1: (i) Data Preprocessing, (ii) Feature Selection and Engineering, (iii) Machine Learning Model Training, (iv) Model Evaluation and Optimization, and (v) Early Detection and Intervention.

OCTNet Algorithm framework
In this study, we present a novel approach to retinal disease diagnosis using an innovative Attention-Based DenseNet architecture. The primary novelty of our method lies in the integration of an attention mechanism within the DenseNet framework. This attention mechanism allows the model to focus on the most relevant features of the optical coherence tomography (OCT) images, significantly improving its ability to differentiate between various retinal conditions. Additionally, we have customized data augmentation techniques specifically tailored for OCT images, enhancing the model's robustness and generalization across diverse datasets.
Another unique aspect of our approach is the application of L2 regularization within the Attention-Based DenseNet. This regularization technique effectively mitigates overfitting, ensuring that the model performs consistently well on unseen data. The combination of these advanced techniques not only enhances the accuracy of retinal disease classification but also demonstrates the potential for real-world clinical application.
Furthermore, the model has been optimized to handle high-resolution OCT images, a critical factor in achieving precise diagnostic results. The clinical validation of our model with real patient data further underscores its practical relevance and sets it apart from existing approaches in the field.
3.1 Data preprocessing
The OCTNet Algorithm's Data Preprocessing phase is essential for ensuring that the input OCT images are properly processed for later analysis. Several image processing operations are performed during this stage to improve the consistency and quality of the data. Algorithm 1 illustrates the Data Preprocessing algorithm's steps.

Data preprocessing algorithm
3.2 Feature selection and engineering
The OCTNet Algorithm's Feature Selection and Engineering phase is a critical step in extracting pertinent characteristics from the preprocessed OCT images and boosting their ability to discriminate between retinal diseases. Algorithm 2 illustrates the Feature Selection and Engineering algorithm's steps.

Feature selection and engineering algorithm
3.3 Machine learning model training
The OCTNet Algorithm's Machine Learning Model Training phase is a vital stage where the retrieved and designed features are utilized to train a predictive model for the diagnosis of retinal diseases. The main goal of the machine learning model training phase is to create a reliable predictive model that can identify retinal disorders using the extracted and engineered data. These crucial actions are included in this phase: (i) Data Split The dataset is split into subsets for training and validation so that the model can learn from the training data and be tested against new data. (ii) Model selection For classification jobs, select the best machine learning model or algorithm. Deep neural networks, random forests, and support vector machines are popular options. (iii) Model Training On the training subset, train the chosen model using the engineering features as the input and the labels of well-known diseases as the target variable. (iv) Hyperparameter Tuning To improve the performance of the model, adjust its hyperparameters. Grid search or random search for hyperparameter combinations may be used in this. (v) Analyze the model's performance based on the validation subset AUC-ROC, accuracy, precision, recall, and F1 score are examples of common evaluation metrics. Algorithm 3 illustrates the Machine Learning Model Training algorithm's steps.

Machine learning model training algorithm
3.4 Model evaluation and optimization
The Model Evaluation and Optimization phase in the OCTNet Algorithm is a critical step to assess the performance of the trained machine learning model and optimize it for retinal disease diagnosis. Algorithm 4 illustrates the Model Evaluation and Optimization algorithm's steps.

Model evaluation and optimization algorithm
3.5 Early detection and intervention
The Early Detection and Intervention phase involves using the OCTNet model to detect potential retinal diseases early. When an individual undergoes an optical coherence tomography (OCT) scan, the obtained retinal images are processed through the trained model. If the model detects any signs of retinal diseases, it triggers an alert and initiates an early intervention process. Algorithm 5 illustrates the Early Detection and Intervention algorithm's steps.

Early detection and intervention algorithm
4 Implementation and evaluation
This section introduces the used dataset, the performance metrics and the performance evaluation.
4.1 Dataset description
OCT Retinal Disease Dataset (ORDD) [29] images as depicted in Fig. 2a were gathered from adult patients from various institutions between 2013 and 2017. The dataset consists of 84495 JPEG images from four categories (NORMAL, CNV, DME, DRUSEN) and is organized into three folders (train, test, val). Figure 2b shows the sample from different dataset classes. The sample testing Dataset from ophthalmology Clinic at Kafrelsheikh University Hospitals was relied upon to improve clinical verification for patients with retinal diseases.

OCT images
4.2 L2 regularization implementation
In our study, L2 regularization was employed to mitigate overfitting and improve the generalization of the Attention-Based DenseNet model. The regularization term is mathematically expressed as follows:
where λ is the regularization parameter, and wi are the weights of the model.
Additionally, we have included a comparison table that illustrates the impact of L2 regularization on model performance. This table compares the validation accuracy and other performance metrics with and without L2 regularization, highlighting its effect on reducing overfitting and improving model generalization.
Regarding the validation accuracy of 0.9792, we have now provided a detailed explanation of how this result was achieved.
The attention based DenseNet parameters are shown in Table 2. The attention-based DenseNet hyperparameters are shown in Table 3.
Before diving into the technical implementation of the OCTNet model, it is important to emphasize the rigorous process followed to ensure the model's robustness and reliability. The development of OCTNet was guided by a meticulous approach, beginning with an extensive review of existing methods in retinal disease diagnosis. Following this, we designed a comprehensive experimental pipeline that includes data preprocessing, model training, evaluation, and optimization, all while maintaining a strong focus on reproducibility. Each phase of the model's development was carefully documented, with special attention given to the integration of state-of-the-art techniques such as attention mechanisms within the DenseNet framework. This systematic approach not only enhanced the model's performance but also facilitated its application in real-world clinical settings, ensuring that our research could be effectively translated into practical medical tools.
This foundation set the stage for the technical implementation, detailed below, where we leveraged advanced programming tools and libraries to bring the OCTNet model to life.
To ensure the reproducibility and transparency of our research, we provide the following technical details regarding the implementation of the OCTNet model:
-
i.
Development Environment The OCTNet model was implemented using the PyCharm Integrated Development Environment (IDE), which facilitated efficient code management, debugging, and version control throughout the development process.
-
ii.
Programming Language Python was selected as the primary programming language due to its robust ecosystem of machine learning and deep learning libraries, making it well-suited for developing complex models like OCTNet.
-
iii.
Libraries and Frameworks
-
TensorFlow and Keras were employed for constructing and training the Attention-Based DenseNet model. These frameworks offer a flexible and scalable environment for deep learning tasks.
-
OpenCV was utilized for image preprocessing, including resizing, noise reduction, and contrast enhancement, which are crucial for preparing optical coherence tomography (OCT) images for model input.
-
NumPy and Pandas were used for efficient data manipulation, ensuring that the dataset was handled optimally throughout the training and evaluation phases.
-
Matplotlib and Seaborn were leveraged for visualizing data distributions, model performance metrics, and other key aspects of the research.
-
Scikit-learn was incorporated for feature selection, model evaluation, and the computation of various performance metrics, aiding in the refinement of the model.
-
Apache Kafka was integrated to manage real-time data streams during the inference phase, enhancing the model's ability to process and analyze incoming data efficiently.
-
4.3 Results
The results showed that the val_accuracy is equal to 0.9167. The results of attention based DenseNet training are illustrated in Fig. 3.

Training Results of Attention-Based DenseNet
The results of defining the attention-based DenseNet with L2 regularization showed that the test accuracy is equal to 0.958333. The results are illustrated in Fig. 4.

The results of training the attention-based DenseNet with L2 regularization
The results of defining the attention-based DenseNet with L2 regularization showed that the val_accuracy is equal to 0.9792. The results are illustrated in Fig. 5.

The results of testing the attention-based DenseNet with L2 regularization
4.4 Results discussion
Our study findings highlight the potential of the Attention-Based DenseNet model for diagnosing retinal diseases. By training the model on a large dataset of 84495 high-resolution OCT images, we achieved an impressive validation accuracy of 0.9167. This indicates that the model can effectively classify retinal diseases into four categories: NORMAL, CNV, DME, and DRUSEN.
Furthermore, when we applied L2 regularization to the Attention-Based DenseNet, the test accuracy improved even further to 0.9583. This enhancement demonstrates the model's ability to generalize well and accurately identify retinal diseases in new and unseen data. The additional L2 regularization helps prevent overfitting and enhances overall performance.
Moreover, our model exhibited outstanding validation results with L2 regularization, achieving a validation accuracy of 0.9792. This high accuracy underscores the model's consistency and reliability in identifying retinal diseases across different data sets, which is crucial for real-world clinical applications where robustness and reliability are essential.
These findings have significant implications for improving the diagnosis of retinal diseases, leading to better patient care in clinical settings. The model's ability to distinguish between various conditions, such as diabetic maculopathy, CNV, and drusen, provides a valuable tool for ophthalmologists and healthcare professionals.
The exceptional accuracy achieved in our study highlights the potential of deep learning techniques, particularly the Attention-Based DenseNet, to revolutionize the diagnosis of retinal diseases. By leveraging advanced technology and robust neural network architectures, we can enhance clinical precision and patient care, thereby mitigating the risks associated with retinal diseases.
However, it is important to acknowledge that while our model demonstrated remarkable performance, there is still room for further improvements and refinements. Future research could focus on expanding the dataset to increase its diversity and comprehensiveness. Additionally, exploring other regularization techniques and architectures to optimize the model's performance would be a worthwhile endeavor.
In summary, this study suggests that the Attention-Based DenseNet model, both with and without L2 regularization, holds promise for improving the diagnosis of retinal diseases. These findings contribute to ongoing efforts in enhancing clinical precision and patient outcomes in the field of ophthalmology.
4.5 Results implications
The findings presented in this study have significant implications for the field of ophthalmology and the diagnosis of retinal diseases. The initial model using Attention-Based DenseNet achieved a high validation accuracy of 0.9167, highlighting the potential of this approach to improve the precision of retinal disease diagnosis. This suggests that when combined with high-quality OCT images, AI-powered models can serve as valuable tools for early detection and intervention in retinal diseases.
Additionally, the results obtained by incorporating L2 regularization into the Attention-Based DenseNet showed promising test accuracy (0.9583) and even higher validation accuracy (0.9792). These findings indicate that the implementation of regularization techniques can further enhance the model's robustness and generalization, which is crucial for developing clinically applicable diagnostic tools.
Taken together, these findings emphasize the potential of Attention-Based DenseNet as a powerful diagnostic assistant in clinical settings. Its ability to provide accurate and reliable diagnoses of retinal diseases can lead to early interventions and improved patient care. Such technological advancements are essential for addressing diagnostic challenges in ophthalmology and improving the accuracy and efficiency of retinal disease diagnosis.
In conclusion, this research not only demonstrates the promise of Attention-Based DenseNet but also underscores the importance of embracing cutting-edge technology in the field of ophthalmology. The implications of this work are clear: by integrating advanced neural network architectures with state-of-the-art imaging techniques, we can significantly enhance clinical outcomes and benefit patients by enabling early detection and intervention in cases of retinal diseases.
Table 4 provides a summary of the accuracy percentages and complexity associated with various deep learning models in the context of the discussed application. As illustrated in the table, traditional models such as CNNs, RNNs, and LSTMs exhibit high accuracy ranging from 96 to 97%. More advanced models, including Transformers and Attention Mechanisms, offer slightly improved performance with accuracies of approximately 96.7% and 95.95%, respectively. The Variational Autoencoder (VAE) and the Optimized Convolutional Transformer (OCT) demonstrate superior performance, with VAEs achieving an accuracy of 97.8% and OCT achieving the highest accuracy at 98.7%. The table also highlights the complexity of each model. While traditional models like CNNs have moderate complexity due to their high parameter count but efficient processing, more advanced models like Transformers and LSTMs involve high computational complexity, with Transformers facing quadratic complexity related to sequence length. In contrast, the proposed OCT model shows low to moderate complexity, attributed to its optimized architecture that offers efficient processing with fewer parameters compared to traditional models.
4.5.1 Accuracy analysis
The OCT achieves the highest accuracy at 98.7%, surpassing all other models evaluated. This result underscores the effectiveness of the OCT model in leveraging both convolutional and transformer-based approaches to enhance prediction accuracy. The Variational Autoencoder (VAE) also performs exceptionally well with an accuracy of 97.8%, reflecting its robustness in capturing complex patterns through its generative architecture.
Traditional models such as CNNs, RNNs, and LSTM networks show strong performance, with accuracies ranging from 96 to 97%. CNNs, known for their high performance in image recognition tasks, achieve 97%, while LSTMs and RNNs show slightly lower accuracies. This slight decrement can be attributed to the inherent limitations of sequential processing and the challenges associated with learning long-term dependencies in sequential data.
Advanced models like Transformers and Attention Mechanisms provide moderate improvements in accuracy compared to traditional models, with Transformers achieving 96.7% and Attention Mechanisms reaching 95.95%. While these models excel in capturing complex dependencies and contextual information, their performance is not as high as the VAE and OCT models.
4.5.2 Complexity analysis
In terms of complexity, traditional CNNs are categorized as having moderate complexity. They require significant parameter tuning but are efficient in image recognition due to their well-established architecture. On the other hand, RNNs and LSTMs face high complexity due to their sequential processing nature and the computational burden associated with learning long-term dependencies. LSTMs, while effective in handling long sequences, still struggle with high computational demands due to their gating mechanisms.
Transformers exhibit high complexity due to their quadratic computational requirements concerning sequence length. This complexity translates into substantial resource demands, particularly for large-scale data. Attention Mechanisms add moderate to high complexity by introducing additional computational overhead for calculating attention weights.
The VAE, with its encoder–decoder architecture, also falls into the moderate complexity category. It requires careful hyperparameter tuning but remains relatively efficient in generating high-quality data. Notably, the OCT model demonstrates low to moderate complexity. Its optimized architecture enables efficient processing and fewer parameters compared to traditional models, contributing to its superior performance while maintaining computational feasibility.
4.5.3 Implications
The comparison highlights that while traditional models and some advanced approaches achieve high accuracy, the OCT model stands out for its superior performance and manageable complexity. This balance of high accuracy with relatively low complexity makes the OCT model a compelling choice for applications requiring both precision and efficiency. Future research could explore further optimization techniques to enhance the performance and reduce the complexity of these models, potentially integrating aspects from both traditional and advanced approaches to achieve even greater efficacy in predictive tasks.
Overall, the results validate the effectiveness of the OCT model in surpassing traditional and state-of-the-art models, offering significant advancements in the field.
In the Conclusion section, we acknowledge several limitations of our study:
-
i.
Dataset Limitations The performance of the models, including the proposed OCT algorithm, is evaluated on a specific dataset that may not fully represent the diversity of real-world scenarios. Variations in data quality, sample size, and demographic diversity could impact the generalizability of the results. Future research should involve more diverse datasets to validate the robustness of the proposed model across different populations and conditions.
-
ii.
Computational Resources Although the OCT model demonstrates superior performance with manageable complexity, it still requires substantial computational resources for training and inference. The high performance of advanced models such as Transformers and OCT may not be feasible in environments with limited computational power or budget constraints. Addressing these resource requirements is crucial for practical deployment.
-
iii.
Real-Time Application The study primarily focuses on model accuracy and complexity without extensive evaluation of real-time performance. The latency and processing time of the models, especially for applications requiring immediate feedback, are not fully explored. Future work should assess the efficiency of the OCT model in real-time scenarios to ensure its suitability for practical use.
-
iv.
Interpretability and Usability While the OCT model offers high accuracy, its interpretability and ease of integration into existing systems are not thoroughly addressed. Understanding the decision-making process of complex models remains a challenge, and ensuring that the model’s predictions are explainable and actionable for clinicians is an important aspect to consider.
-
v.
Benchmark Comparisons The study compares the OCT model with several deep learning models but does not include comparisons with other state-of-the-art techniques beyond the specified range. Expanding the comparison to include a broader array of contemporary methods could provide a more comprehensive evaluation of the model's relative performance.
In summary, while the proposed OCT model shows promising results, addressing these limitations will be important for enhancing its applicability, scalability, and effectiveness in real-world scenarios. Future research should focus on overcoming these limitations to further advance the field and improve the practical utility of the model.
4.6 Rationale for applying attention-based DenseNet and ablation study
The decision to utilize the Attention-Based DenseNet (OCTNet) framework for retinal disease diagnosis is underpinned by several compelling factors. Firstly, the incorporation of an attention mechanism within the DenseNet architecture allows the model to focus on the most relevant features of optical coherence tomography (OCT) images, significantly enhancing its ability to differentiate between various retinal conditions. This targeted feature extraction is crucial for accurate diagnosis. Secondly, our approach addresses the challenge of processing high-resolution OCT images effectively, leveraging the attention mechanism to extract meaningful patterns from detailed images. To validate the efficacy of our framework, we conducted an ablation study comparing the performance of the Attention-Based DenseNet against standard DenseNet models, with and without the attention mechanism. Additionally, we evaluated the impact of customized data augmentation techniques and L2 regularization on model performance. The results of these experiments demonstrate the advantages of our approach, including improved diagnostic accuracy and robustness. For baseline comparison, we benchmarked our model against other state-of-the-art architectures, affirming the superior performance of the Attention-Based DenseNet framework in handling complex retinal disease diagnosis tasks.
5 Future research
As advancements in AI and machine learning continue to evolve, several areas of future research can be explored to enhance the capabilities and applications of the proposed model:
-
i.
Integration of Advanced Attention Mechanisms Future research could investigate the integration of more sophisticated attention mechanisms, such as transformer-based models, to further improve model interpretability and performance. These mechanisms could help capture more complex relationships within the data, leading to better predictions and explanations.
-
ii.
Real-Time Implementation Implementing the model in real-time scenarios, such as in healthcare or financial systems, could be explored. This would involve addressing challenges related to computational efficiency, latency, and system integration to ensure the model can operate effectively in live environments.
-
iii.
Multi-Modal Data Fusion Expanding the model to handle multi-modal data, such as combining text, image, and sensor data, could open new avenues for research. This approach would allow the model to leverage diverse information sources, leading to more robust and accurate predictions in complex scenarios.
-
iv.
Ethical and Societal Implications As AI systems become more integrated into decision-making processes, future research should explore the ethical implications, including fairness, transparency, and accountability. Developing frameworks for assessing and mitigating biases in AI models will be crucial to ensure equitable outcomes.
-
v.
Scalability and Adaptability Exploring methods to scale the model for larger datasets and more complex applications will be essential. Future research could focus on developing techniques to adapt the model to different domains and use cases, ensuring its broad applicability and effectiveness across various industries.
-
vi.
User-Centric Explainability While explainability has been a focus, future work could delve deeper into user-centric approaches, where the explanations are tailored to the specific needs and understanding levels of different user groups. This would involve designing interfaces and interaction methods that make AI explanations more accessible and actionable.
-
vii.
Longitudinal Studies and Continuous Learning Conducting longitudinal studies to assess the long-term effectiveness of the model in real-world settings would provide valuable insights. Additionally, integrating continuous learning mechanisms that allow the model to adapt to new data over time could enhance its predictive power and relevance.
-
viii.
Cross-Domain Applications Exploring the application of the proposed model in different domains, such as environmental monitoring, smart cities, and personalized education, could demonstrate its versatility and impact. Adapting the model to specific challenges in these areas could lead to innovative solutions and broader adoption.
6 Conclusion and future work
This study presents a novel approach to diagnosing retinal diseases using Attention-Based DenseNet (OCTNet). The results highlight the potential of this deep learning model to improve the precision of retinal disease diagnosis, achieving an impressive validation accuracy of 0.9167. Furthermore, the implementation of L2 regularization further improved the model's performance, resulting in a test accuracy of 0.958333 and an outstanding validation accuracy of 0.9792. These findings provide compelling evidence that combining advanced neural network architectures with high-resolution OCT images can significantly contribute to early disease detection and
Incorporating recent advances in assistive technology, such as the real-time facial emotion recognition model developed by Talaat et al. [32], which utilizes kernel autoencoders and convolutional neural networks for detecting emotions in children with Autism Spectrum Disorder (ASD), underscores the potential for integrating similar innovative approaches into future research. This could significantly enhance early diagnosis and personalized intervention strategies in sleep health. Moreover, drawing on reliable systems for managing virtual cloud networks, as highlighted by Alshathri et al. [31], can support the development of robust and scalable solutions in this field. Additionally, future work could benefit from exploring the integration of IoT and wearable technology, as demonstrated in recent studies [30,31,32,33,34,35,36,37,38,39,40,41,42,43], to further personalize and enhance sleep health interventions.
References
Fujimoto JG, Brezinski ME, Tearney GJ, Boppart SA, Bouma B, Hee MR, et al. (1995) Optical biopsy and imaging using optical coherence tomography. Nature Publishing Group US New York
Hanson RL, Airody A, Sivaprasad S, Gale RP (2023) Optical coherence tomography imaging biomarkers associated with neovascular age-related macular degeneration: a systematic review. Eye 37(12):2438–2453
Trichonas G, Kaiser PK (2014) Optical coherence tomography imaging of macular oedema. Br J Ophthalmol 98(Suppl 2):ii4–ii9
Lim LS, Mitchell P, Seddon JM, Holz FG, Wong TY (2012) Age-related macular degeneration. Lancet 379(9827):1728–1738
Klein R, Klein BE (2013) The prevalence of age-related eye diseases and visual impairment in aging: current estimates. Investig Ophthalmol Vis Sci 54(14):ORSF5–ORSF13
Lee AY, Lee CS, Butt T, Xing W, Johnston RL, Chakravarthy U et al (2015) UK AMD EMR USERS GROUP REPORT V: benefits of initiating ranibizumab therapy for neovascular AMD in eyes with vision better than 6/12. Br J Ophthalmol 99(8):1045–1050
Sakurada Y, Tanaka K, Fragiotta S (2023) Differentiating drusen and drusenoid deposits subtypes on multimodal imaging and risk of advanced age-related macular degeneration. Jpn J Ophthalmol 67(1):1–13
Zhang P, Xue W, Huang X, Xu Y, Lu L, Zheng K, Zou H (2021) Prevalence and risk factors of diabetic retinopathy in patients with type 2 diabetes in Shanghai. Int J Ophthalmol 14(7):1066–1072. https://doi.org/10.18240/ijo.2021.07.16
Wang W, Lo ACY (2018) Diabetic retinopathy: pathophysiology and treatments. Int J Mol Sci 19(6):1816. https://doi.org/10.3390/ijms19061816
Age-Related Eye Disease Study Research Group (2001) The age-related eye disease study system for classifying age-related macular degeneration from stereoscopic color fundus photographs: the Age-Related Eye Disease Study Report Number 6. Am J Ophthalmol. 132(5):668–681. https://doi.org/10.1016/s0002-9394(01)01218-1.S0002939401012181
Cesareo M, Ciuffoletti E, Ricci F, Missiroli F, Giuliano MA, Mancino R, Nucci C (2015) Visual disability and quality of life in glaucoma patients. Prog Brain Res 221:359–374. https://doi.org/10.1016/bs.pbr.2015.07.003.S0079-6123(15)00109-0
Ireka OJ, Ogbonnaya CE, Arinze OC, Ogbu N, Chuka-Okosa CM (2021) Comparing posture induced intraocular pressure variations in normal subjects and glaucoma patients. Int J Ophthalmol 14(3):399–404. https://doi.org/10.18240/ijo.2021.03.11
King H, Aubert RE, Herman WH (1998) Global burden of diabetes, 1995–2025: prevalence, numerical estimates, and projections. Diabetes Care 21(9):1414–1431. https://doi.org/10.2337/diacare.21.9.1414
Nucci C, Russo R, Martucci A, Giannini C, Garaci F, Floris R, Bagetta G, Morrone LA (2016) New strategies for neuroprotection in glaucoma, a disease that affects the central nervous system. Eur J Pharmacol 15(787):119–126. https://doi.org/10.1016/j.ejphar.2016.04.030.S0014-2999(16)30245-X
Chen Q, Yu W, Lin S, Liu B, Wang Y, Wei Q, He X, Ding F, Yang G, Chen Y, Li X, Hu B (2021) Artificial intelligence can assist with diagnosing retinal vein occlusion. Int J Ophthalmol 14(12):1895–1902. https://doi.org/10.18240/ijo.2021.12.13
Wan C, Li H, Cao G, Jiang Q, Yang W (2021) An artificial intelligent risk classification method of high myopia based on fundus images. J Clin Med 10(19):4488. https://doi.org/10.3390/jcm10194488
Xu J, Shen J, Jiang Q, Wan C, Yan Z, Yang W (2021) Research on the segmentation of biomarker for chronic central serous chorioretinopathy based on multimodal fundus image. Dis Markers 2021:1040675. https://doi.org/10.1155/2021/1040675
Wan C, Chen Y, Li H, Zheng B, Chen N, Yang W, Wang C, Li Y (2021) EAD-Net: a novel lesion segmentation method in diabetic retinopathy using neural networks. Dis Markers 2021:6482665. https://doi.org/10.1155/2021/6482665
Calisto FM, Santiago C, Nunes N, Nascimento JC (2021) Introduction of human-centric AI assistant to aid radiologists for multimodal breast image classification. Int J Hum Comput Stud 150:102607. https://doi.org/10.1016/j.ijhcs.2021.102607
Calisto F, Nunes N, Nascimento J (2020) BreastScreening. International conference on advanced visual interfaces, pp. 1–5, September 20–October 2 2020. Salerno, Italy
FDA permits marketing of artificial intelligence-based device to detect certain diabetes-related eye problems. US Food and Drug Administration. [2018–04–11]. https://www.fda.gov/news-events/press-announcements/fda-permits-marketing-artificial-intelligence-based-device-detect-certain-diabetes-related-eye
Litjens G, Kooi T, Bejnordi BE, Setio AAA, Ciompi F, Ghafoorian M, van der Laak JAWM, van Ginneken B, Sánchez CI (2017) A survey on deep learning in medical image analysis. Med Image Anal 42:60–88. https://doi.org/10.1016/j.media.2017.07.005
Akinniyi O, Rahman MM, Sandhu HS, El-Baz A, Khalifa F (2023) Multi-stage classification of retinal OCT using multi-scale ensemble deep architecture. Bioengineering 10(7):1–16. https://doi.org/10.3390/bioengineering10070823
Jin B, Liu P, Wang P, Shi L, Zhao J (2020) Optic disc segmentation using attention-based U-Net and the improved cross-entropy convolutional neural network. Entropy 22(8):1–13. https://doi.org/10.3390/E22080844
Yang H et al (2023) A multi-layer feature fusion model based on convolution and attention mechanisms for text classification. Appl Sci (Switzerland) 13(14):8550. https://doi.org/10.3390/app13148550
Ma Z, Xie Q, Xie P, Fan F, Gao X, Zhu J (2022) HCTNet: a hybrid ConvNet-transformer network for retinal optical coherence tomography image classification. Biosensors (Basel) 12(7):1–15. https://doi.org/10.3390/bios12070542
Parra-Mora E, da Silva Cruz LA (2022) LOCTseg: a lightweight fully convolutional network for end-to-end optical coherence tomography segmentation. Comput Biol Med 150:106174. https://doi.org/10.1016/j.compbiomed.2022.106174
Daanouni O, Cherradi B, Tmiri A (2022) NSL-MHA-CNN: a novel CNN architecture for robust diabetic retinopathy prediction against adversarial attacks. IEEE Access 10:103987–103999. https://doi.org/10.1109/ACCESS.2022.3210179
https://www.kaggle.com/datasets/fatmamtalaat/oct-retinal-disease-dataset-ordd
Gamel SA, Talaat FM (2024) SleepSmart: an IoT-enabled continual learning algorithm for intelligent sleep enhancement. Neural Comput Appl 36:4293–4309. https://doi.org/10.1007/s00521-023-09310-5
Alshathri S, Talaat FM, Nasr AA (2022) A new reliable system for managing virtual cloud network. Comput Mater Contin 73(3):5863–5885
Talaat FM, Ali ZH, Mostafa RR, El-Rashidy N (2024) Real-time facial emotion recognition model based on kernel autoencoder and convolutional neural network for autism children. Soft Comput 28:6695–6708
Talaat FM, El-Balka RM (2023) Stress monitoring using wearable sensors: IoT techniques in medical field. Neural Comput Appl 35(25):18571–18584
Hassan E, Talaat FM, Hassan Z, & El-Rashidy N (2023) Breast cancer detection: a survey. In: Artificial intelligence for disease diagnosis and prognosis in smart healthcare (pp. 169–176). CRC Press
Hassan E, Talaat FM, Adel S, Abdelrazek S, Aziz A, Nam Y, El-Rashidy N (2023) Robust deep learning model for black fungus detection based on gabor filter and transfer learning. Comput Syst Sci Eng 47(2):1507
Talaat FM, Gamel SA (2023) A2M-LEUK: attention-augmented algorithm for blood cancer detection in children. Neural Comput Appl 35(24):18059–18071
Talaat FM, El-Sappagh S, Alnowaiser K, Hassan E (2024) Improved prostate cancer diagnosis using a modified ResNet50-based deep learning architecture. BMC Med Inform Decis Mak 24(1):23
Talaat FM, El-Gendy EM, Saafan MM, Gamel SA (2023) Utilizing social media and machine learning for personality and emotion recognition using PERS. Neural Comput Appl 35(33):23927–23941
Talaat FM, Farsi M, Badawy M, Elhosseini M (2024) SightAid: empowering the visually impaired in the Kingdom of Saudi Arabia (KSA) with deep learning-based intelligent wearable vision system. Neural Comput Appl 36:11075–11095
Ibraheem MR, Almuayqil SN, Abd El-Aziz AA, Tawfeek MA, Talaat FM (2023) Diagnosis of patellofemoral osteoarthritis using enhanced sequential deep learning techniques. Egypt Inform J 24(3):100391
Talaat FM (2024) The effect of consanguineous marriage on reading disability based on deep neural networks. Multimed Tools Appl 83(17):51787–51807
ZainEldin H, Gamel SA, Talaat FM et al (2024) Silent no more: a comprehensive review of artificial intelligence, deep learning, and machine learning in facilitating deaf and mute communication. Artif Intell Rev 57:188. https://doi.org/10.1007/s10462-024-10816-0
ZainEldin H, Baghdadi NA, Gamel SA et al (2024) Active convolutional neural networks sign language (ActiveCNN-SL) framework: a paradigm shift in deaf-mute communication. Artif Intell Rev 57:162. https://doi.org/10.1007/s10462-024-10792-5
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
Author information
Authors and Affiliations
Contributions
Equivalent roles.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflicts of interest to report regarding the present study.
Ethical approval
There is no any ethical conflicts.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Talaat, F.M., Ali, A.A.A., ElGendy, R. et al. Deep attention for enhanced OCT image analysis in clinical retinal diagnosis. Neural Comput & Applic 37, 1105–1125 (2025). https://doi.org/10.1007/s00521-024-10450-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-024-10450-5