
Abstract
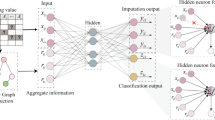
Missing values exist widely in real-world datasets, which restrict the performance of data mining. In this paper, we propose a joint optimization framework to mine attribute associations and category structures in incomplete datasets, aiming to impute missing values with a full understanding of the data structure. Considering the differences in attribute correlations among different sample categories, we partition incomplete data into fuzzy subsets by fuzzy clustering. Within each subset, a tracking-removed autoencoder is constructed as a submodel to fit the regression relationships among attributes. Due to the mutual influence between fuzzy clustering and regression modeling, we further propose a missing value variable-based training scheme to iteratively optimize these two processes. Our proposed framework offers the advantage of decomposing the complex imputation task into simpler sub-tasks by fuzzy clustering where the attribute associations are more explicit. Moreover, the proposed training scheme activates the complementary nature of clustering and regression processes to reduce imputation errors. The experimental results on artificial and real datasets illustrate the effectiveness of our proposed framework.







Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Data availability
My manuscript has associated data in a data repository.
References
Austin PC, White IR, Lee DS, van Buuren S (2021) Missing data in clinical research: a tutorial on multiple imputation. Can J Cardiol 37:1322–1331
Zhang T, Zhang D, Yan H, Qiu J, Gao J (2021) A new method of data missing estimation with FNN-based tensor heterogeneous ensemble learning for internet of vehicle. Neurocomputing 420:98–110
Li L, Du B, Wang Y, Qin L, Tan H (2020) Estimation of missing values in heterogeneous traffic data: Application of multimodal deep learning model. Knowl Based Syst 194:105592
Lustig N (2020) The “missing rich” in household surveys: causes and correction approaches, Working Paper 75 Commitment to Equity (CEQ) Institute. Tulane University, Louisiana
Bertsimas D, Pawlowski C, Zhuo YD (2018) From predictive methods to missing data imputation: An optimization approach. J Mach Learn Res 18:1–39
Luo Y, Cai X, Zhang Y, Xu J (2018) Multivariate time series imputation with generative adversarial networks. In: Advances in Neural Information Processing Systems. Curran Associates, pp 1596–1607.
Muzellec B, Josse J, Boyer C, Cuturi M (2020) Missing data imputation using optimal transport. In: Proceedings of the 37th International Conference on Machine Learning. PMLR, pp 7130–7140
Tsai C-F, Chang F-Y (2016) Combining instance selection for better missing value imputation. J Syst Softw 122:63–71
Liu Z, Pan Q, Dezert J, Martin A (2016) Adaptive imputation of missing values for incomplete pattern classification. Pattern Recognit 52:85–95
Lin W-C, Tsai C-F (2020) Missing value imputation: A review and analysis of the literature (2006–2017). Artif Intell Rev 53:1487–1509
Taylor S, Ponzini M, Wilson M, Kim K (2021) Comparison of imputation and imputation-free methods for statistical analysis of mass spectrometry data with missing data. Brief Bioinform 23:bbab353
Aydilek IB, Arslan A (2013) A hybrid method for imputation of missing values using optimized fuzzy c-means with support vector regression and a genetic algorithm. Inf Sci 233:25–35
Di Nuovo AG (2011) Missing data analysis with fuzzy c-means: A study of its application in a psychological scenario. Expert Syst Appl 38:6793–6797
Luengo J, Sáez JA, Herrera F (2012) Missing data imputation for fuzzy rule-based classification systems. Soft Comput 16:863–881
Hasan MdK, Alam MdA, Roy S, Dutta A, Jawad MT, Das S (2021) Missing value imputation affects the performance of machine learning: A review and analysis of the literature (2010–2021). Inform Med Unlocked 27:100799
van Buuren S, Groothuis-Oudshoorn K (2011) Mice: Multivariate imputation by chained equations in R. J Stat Softw 45:1–67
Abdella M, Marwala T (2005) The use of genetic algorithms and neural networks to approximate missing data in database. In: International Conference on Computational Cybernetics, IEEE, pp 207–212
Gautam C, Ravi V (2015) Counter propagation auto-associative neural network based data imputation. Inf Sci 325:288–299
Miranda V, Krstulovic J, Keko H, Moreira C, Pereira J (2012) Reconstructing missing data in state estimation with autoencoders. IEEE Trans Power Syst 27:604–611
Krstulovic J, Miranda V, Simões Costa AJA, Pereira J (2013) Towards an auto-associative topology state estimator. IEEE Trans Power Syst 28:3311–3318
Ghezelbash R, Maghsoudi A, Shamekhi M, Pradhan B, Daviran M (2023) Genetic algorithm to optimize the SVM and k-means algorithms for mapping of mineral prospectivity. Neural Comput Appl 35:719–733
Mohammadrezapour O, Kisi O, Pourahmad F (2020) Fuzzy c-means and k-means clustering with genetic algorithm for identification of homogeneous regions of groundwater quality. Neural Comput Appl 32:3763–3775
Lai X, Wu X, Zhang L, Lu W, Zhong C (2019) Imputations of missing values using a tracking-removed autoencoder trained with incomplete data. Neurocomputing 366:54–65
Ghosh TK, Hasan MdK, Roy S, Alam MA, Hossain E, Ahmad M (2021) Multi-class probabilistic atlas-based whole heart segmentation method in cardiac CT and MRI. IEEE Access 9:66948–66964
Schneider T (2001) Analysis of incomplete climate data: Estimation of mean values and covariance matrices and imputation of missing values. J Clim 14:853–871
Castillo I, Schmidt-Hieber J, van der Vaart A (2015) Bayesian linear regression with sparse priors. Ann Stat 43:1986–2018
Sengupta N, Udell M, Srebro N, Evans J (2023) Sparse data reconstruction, missing value and multiple imputation through matrix factorization. Sociol Methodol 53(1):72–114
Yuan L (2022) Evaluating the state of the art in missing data imputation for clinical data. Brief Bioinform.
Salakhutdinov R, Mnih A (2008) Bayesian probabilistic matrix factorization using markov chain monte carlo. In: International Conference on Machine Learning. Association for Computing Machinery, pp 880–887
Chen X, He Z, Sun L (2019) A Bayesian tensor decomposition approach for spatiotemporal traffic data imputation. Transp Res Part C Emerg Technol 98:73–84
Kreindler DM, Lumsden CJ (2016) The effects of the irregular sample and missing data in time series analysis. Nonlinear Dynamical Systems Analysis for the Behavioral Sciences Using Real Data. CRC Press, Florida, pp 149–172
Soley-Bori M (2013) Dealing with missing data: Key assumptions and methods for applied analysis. Boston University, Boston
Shi Z, Wang S, Yue L, Pang L, Zuo X, Zuo W, Li X (2021) Deep dynamic imputation of clinical time series for mortality prediction. Inf Sci 579:607–622
Feng R, Grana D, Balling N (2021) Imputation of missing well log data by random forest and its uncertainty analysis. Comput Geosci 152:104763
Khan SI, Hoque ASML (2020) SICE: An improved missing data imputation technique. J Big Data 7:1–21
Thomas T, Rajabi E (2021) A systematic review of machine learning-based missing value imputation techniques. Data Technol Appl 55:558–585
Jung S, Moon J, Park S, Rho S, Baik SW, Hwang E (2020) Bagging ensemble of multilayer perceptrons for missing electricity consumption data imputation. Sensors 20:1772
Sharpe PK, Solly RJ (1995) Dealing with missing values in neural network-based diagnostic systems. Neural Comput Appl 3:73–77
Choudhury SJ, Pal NR (2019) Imputation of missing data with neural networks for classification. Knowl Based Syst 182:104838
Razavi-Far R, Cheng B, Saif M, Ahmadi M (2020) Similarity-learning information-fusion schemes for missing data imputation. Knowl Based Syst 187:104805
Shang Q, Yang Z, Gao S, Tan D (2018) An imputation method for missing traffic data based on fcm optimized by pso-svr. J Adv Transp 2018:1–21
Lim C-P, Leong J-H, Kuan M-M (2005) A hybrid neural network system for pattern classification tasks with missing features. IEEE Trans Pattern Anal Mach Intell 27:648–653
Raja PS, Sasirekha K, Thangavel K (2020) A novel fuzzy rough clustering parameter-based missing value imputation. Neural Comput Appl 32:10033–10050
Tang F, Ishwaran H (2017) Random forest missing data algorithms. Stat Anal Data Min 10:363–377
Dua D, Graff C (2017) UCI machine learning repository. University of California, Irvine, School of Information and Computer Sciences,http://archive.ics.uci.edu/ml
Alcalá-Fdez J, Fernández A, Luengo J, Derrac J, García S, Sánchez L, Herrera F (2011) KEEL data-mining software tool: Data set repository, integration of algorithms and experimental analysis framework. J Mult Valued Logic Soft Comput 17(2):255–287. https://sci2s.ugr.es/keel/datasets.php
Funding
This work is supported by the National Natural Science Foundation of China (62076050, 62073056), the National Key R&D Program of China (2022YFF0610900) and the Fundamental Research Funds for the Central Universities (DUT22LAB129).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Human and animal rights
This article does not contain any studies with human or animal subjects performed by any of the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Lai, X., Zhang, Z., Zhang, L. et al. Incomplete data modeling based on alternate update of clustering and autoencoder for missing value imputation. Neural Comput & Applic 37, 1523–1540 (2025). https://doi.org/10.1007/s00521-024-10646-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-024-10646-9