
Abstract
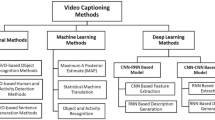
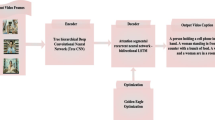
In recent times, active research is going on for bridging the gap between computer vision and natural language. In this paper, we attempt to address the problem of Hindi video captioning. In a linguistically diverse country like India, it is important to provide a means which can help in understanding the visual entities in native languages. In this work, we employ a hybrid attention mechanism by extending the soft temporal attention mechanism with a semantic attention to make the system able to decide when to focus on visual context vector and semantic input. The visual context vector of the input video is extracted using 3D convolutional neural network (3D CNN) and a Long Short-Term Memory (LSTM) recurrent network with attention module is used for decoding the encoded context vector. We experimented on a dataset built in-house for Hindi video captioning by translating \(MSR-VTT\) dataset followed by post-editing. Our system achieves 0.369 CIDEr score and 0.393 METEOR score and outperformed other baseline models including RMN (Reasoning Module Networks)-based model.






Similar content being viewed by others

Change history
17 July 2021
A Correction to this paper has been published: https://doi.org/10.1007/s00530-021-00834-1
Notes
[ ; ] indicates the concatenation.
References
Anne Hendricks, L., Venugopalan, S., Rohrbach, M., Mooney, R., Saenko, K., Darrell, T.: Deep compositional captioning: Describing novel object categories without paired training data. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016)
Ayers, D., Shah, M.: Monitoring human behavior from video taken in an office environment. Image Vis. Comput. 19(12), 833–846 (2001)
Brand, M.: “The inverse hollywood problem”: From video to scripts and storyboards via causal analysis. In: AAAI/IAAI, pp. 132–137. Citeseer (1997)
Carreira, J., Zisserman, A.: Quo vadis, action recognition? a new model and the kinetics dataset. In: proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6299–6308 (2017)
Chen, J., Pan, Y., Li, Y., Yao, T., Chao, H., Mei, T.: Temporal deformable convolutional encoder–decoder networks for video captioning. Proc. AAAI Conf. Artif. Intell. 33, 8167–8174 (2019)
Dhir, R., Mishra, S.K., Saha, S., Bhattacharyya, P.: A deep attention based framework for image caption generation in Hindi language. Computación y Sistemas 23(3) (2019)
Du, X., Yuan, J., Hu, L., Dai, Y.: Description generation of open-domain videos incorporating multimodal features and bidirectional encoder. Vis. Comput. 35(12), 1703–1712 (2019)
Gao, L., Guo, Z., Zhang, H., Xu, X., Shen, H.T.: Video captioning with attention-based LSTM and semantic consistency. IEEE Trans. Multimed. 19(9), 2045–2055 (2017)
Guadarrama, S., Krishnamoorthy, N., Malkarnenkar, G., Venugopalan, S., Mooney, R., Darrell, T., Saenko, K.: Youtube2text: Recognizing and describing arbitrary activities using semantic hierarchies and zero-shot recognition. In: Proceedings of the IEEE international conference on computer vision, pp. 2712–2719 (2013)
Jin, T., Huang, S., Chen, M., Li, Y., Zhang, Z.: Sbat: Video captioning with sparse boundary-aware transformer. In: Bessiere, C. (ed.) Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI-20, pp. 630–636. International Joint Conferences on Artificial Intelligence Organization (2020). https://doi.org/10.24963/ijcai.2020/88. Main track
Karpathy, A., Toderici, G., Shetty, S., Leung, T., Sukthankar, R., Fei-Fei, L.: Large-scale video classification with convolutional neural networks. In: Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pp. 1725–1732 (2014)
Kojima, A., Izumi, M., Tamura, T., Fukunaga, K.: Generating natural language description of human behavior from video images. In: Proceedings 15th International Conference on Pattern Recognition. ICPR-2000, vol. 4, pp. 728–731. IEEE (2000)
Kojima, A., Tamura, T., Fukunaga, K.: Natural language description of human activities from video images based on concept hierarchy of actions. Int. J. Comput. Vision 50(2), 171–184 (2002)
Kollnig, H., Nagel, H.H., Otte, M.: Association of motion verbs with vehicle movements extracted from dense optical flow fields. In: European Conference on Computer Vision, pp. 338–347. Springer (1994)
Li, Y., Yao, T., Pan, Y., Chao, H., Mei, T.: Jointly localizing and describing events for dense video captioning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 7492–7500 (2018)
Lin, C.Y.: Rouge: A package for automatic evaluation of summaries. In: Text summarization branches out, pp. 74–81 (2004)
Lu, J., Xiong, C., Parikh, D., Socher, R.: Knowing when to look: Adaptive attention via a visual sentinel for image captioning. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 375–383 (2017)
Oshita, M.: Generating animation from natural language texts and semantic analysis for motion search and scheduling. Vis. Comput. 26(5), 339–352 (2010)
Pan, Y., Mei, T., Yao, T., Li, H., Rui, Y.: Jointly modeling embedding and translation to bridge video and language. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 4594–4602 (2016)
Pan, Y., Yao, T., Li, H., Mei, T.: Video captioning with transferred semantic attributes. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 6504–6512 (2017)
Papineni, K., Roukos, S., Ward, T., Zhu, W.J.: Bleu: a method for automatic evaluation of machine translation. In: Proceedings of the 40th annual meeting on association for computational linguistics, pp. 311–318. Association for Computational Linguistics (2002)
Pascanu, R., Gulcehre, C., Cho, K., Bengio, Y.: How to construct deep recurrent neural networks. arXiv:1312.6026 (2013)
Perez-Martin, J., Bustos, B., Perez, J.: Improving video captioning with temporal composition of a visual-syntactic embedding. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 3039–3049 (2021)
Ren, S., He, K., Girshick, R., Sun, J.: Faster r-cnn: towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 39(6), 1137–1149 (2016)
Sah, S., Nguyen, T., Ptucha, R.: Understanding temporal structure for video captioning. Pattern Anal. Appl. 23(1), 147–159 (2020)
Sanayai Meetei, L., Singh, T.D., Bandyopadhyay, S.: WAT2019: English-Hindi translation on Hindi visual genome dataset. In: Proceedings of the 6th Workshop on Asian Translation, pp. 181–188. Association for Computational Linguistics, Hong Kong, China (2019). https://doi.org/10.18653/v1/D19-5224. https://www.aclweb.org/anthology/D19-5224
Shetty, R., Laaksonen, J.: Video captioning with recurrent networks based on frame-and video-level features and visual content classification. arXiv:1512.02949 (2015)
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. arXiv:1409.1556 (2014)
Singh, A., Meetei, L.S., Singh, T.D., Bandyopadhyay, S.: Generation and evaluation of hindi image captions of visual genome. In: Proceedings of the International Conference on Computing and Communication Systems: I3CS 2020, NEHU, Shillong, India, vol. 170, p. 65. Springer Nature (2021). https://doi.org/10.1007/978-981-33-4084-8_7
Singh, A., Singh, T.D., Bandyopadhyay, S.: Nits-vc system for vatex video captioning challenge 2020. arXiv:2006.04058 (2020)
Singh, A., Thounaojam, D.M., Chakraborty, S.: A novel automatic shot boundary detection algorithm: robust to illumination and motion effect. Signal, Image and Video Processing 1–9 (2019)
Szegedy, C., Ioffe, S., Vanhoucke, V., Alemi, A.: Inception-v4, inception-resnet and the impact of residual connections on learning. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 31 (2017)
Tan, G., Liu, D., Wang, M., Zha, Z.J.: Learning to discretely compose reasoning module networks for video captioning. arXiv:2007.09049 (2020)
Tran, D., Bourdev, L., Fergus, R., Torresani, L., Paluri, M.: Learning spatiotemporal features with 3d convolutional networks. In: Proceedings of the IEEE international conference on computer vision, pp. 4489–4497 (2015)
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. In: Advances in neural information processing systems, pp. 5998–6008 (2017)
Vedantam, R., Lawrence Zitnick, C., Parikh, D.: Cider: Consensus-based image description evaluation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 4566–4575 (2015)
Venugopalan, S., Rohrbach, M., Donahue, J., Mooney, R., Darrell, T., Saenko, K.: Sequence to sequence-video to text. In: Proceedings of the IEEE international conference on computer vision, pp. 4534–4542 (2015)
Venugopalan, S., Xu, H., Donahue, J., Rohrbach, M., Mooney, R., Saenko, K.: Translating videos to natural language using deep recurrent neural networks. arXiv:1412.4729 (2014)
Vinyals, O., Toshev, A., Bengio, S., Erhan, D.: Show and tell: A neural image caption generator. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 3156–3164 (2015)
Wang, B., Ma, L., Zhang, W., Jiang, W., Wang, J., Liu, W.: Controllable video captioning with pos sequence guidance based on gated fusion network. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 2641–2650 (2019)
Wang, X., Wu, J., Chen, J., Li, L., Wang, Y.F., Wang, W.Y.: Vatex: A large-scale, high-quality multilingual dataset for video-and-language research. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 4581–4591 (2019)
Xu, J., Mei, T., Yao, T., Rui, Y.: Msr-vtt: A large video description dataset for bridging video and language. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 5288–5296 (2016)
Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A., Salakhudinov, R., Zemel, R., Bengio, Y.: Show, attend and tell: Neural image caption generation with visual attention. In: International conference on machine learning, pp. 2048–2057 (2015)
Yao, L., Torabi, A., Cho, K., Ballas, N., Pal, C., Larochelle, H., Courville, A.: Describing videos by exploiting temporal structure. In: Proceedings of the IEEE international conference on computer vision, pp. 4507–4515 (2015)
Yu, H., Wang, J., Huang, Z., Yang, Y., Xu, W.: Video paragraph captioning using hierarchical recurrent neural networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 4584–4593 (2016)
Zheng, Q., Wang, C., Tao, D.: Syntax-aware action targeting for video captioning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13096–13105 (2020)
Acknowledgements
This work is supported by Scheme for Promotion of Academic and Research Collaboration (SPARC) Project Code: P995 of No: SPARC/2018-2019/119/SL (IN) under MHRD, Govt of India.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that there are no conflicts of interest regarding the publication of this paper.
Additional information
Communicated by T. Yao.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Singh, A., Singh, T.D. & Bandyopadhyay, S. Attention based video captioning framework for Hindi. Multimedia Systems 28, 195–207 (2022). https://doi.org/10.1007/s00530-021-00816-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00530-021-00816-3