
Abstract
Recent studies have shown that multichannel narrow-band speech separation achieves remarkable performance, while most successful deep learning-based studies directly work on the full-band spectrum of speech. Motivated by these two different but complementary trends, this paper proposes a multidimensional attention fusion network (MAF-Net) to automatically exploit and fuse narrow-band and full-band speech separation information, aiming at enhancing the performance of multichannel speech separation in a reverberation environment. Specifically, it extracts effective narrow-band and full-band information from three dimensions, temporal, spatial and channel, and dynamically integrates them through a feature fusion mechanism. First, the narrow-band feature extractor (NBFE) collects temporal information frame by frame to model context dependency, and it takes multichannel mixed signals of one frequency as input and generates a narrow-band feature map. Then, the multidimensional attention fusion module (MAFM) is proposed to adaptively fuse narrow-band and full-band information from spatial and channel dimensions. Finally, the arrangement of attention modules within the MAFM is designed to maximize the utilization of spatial and channel attention features, including the parallel MAFM (P-MAFM) and sequential MAFM (S-MAFM). Experimental results demonstrate that our proposed method outperforms other advanced methods.








Similar content being viewed by others
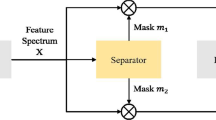
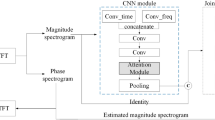
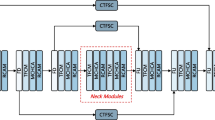
Data availability
The experimental data in this paper is based on the publicly available dataset WSJ0-2mix, and we do not provide data availability statement.
References
Haykin, S., Chen, Z.: The cocktail party problem. Neural Comput. 17, 1875–1902 (2005)
Cherry, E.C.: Some experiments on the recognition of speech, with one and with two ears. J. Acoust. Soc. Am. 25, 975–979 (1953)
Yilmaz, O., Rickard, S.: Blind separation of speech mixtures via time-frequency masking. IEEE Trans. Signal Process. 52, 1830–1847 (2004)
Hershey, J.R., Chen, Z., Le Roux, J., Watanabe, S.: Deep clustering: Discriminative embeddings for segmentation and separation. In: 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 31–35 (2016)
Yu, D., Kolbæk, M., Tan, Z.-H., Jensen, J.: Permutation invariant training of deep models for speaker-independent multi-talker speech separation. In: 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 241–245 (2017)
Kolbæk, M., Yu, D., Tan, Z.-H., Jensen, J.: Multitalker speech separation with utterance-level permutation invariant training of deep recurrent neural networks. IEEE/ACM Trans. Audio Speech Lang. Process. 25, 1901–1913 (2017)
Liu, Y., Wang, D.: Divide and conquer: A deep CASA approach to talker-independent monaural speaker separation. IEEE/ACM Trans. Audio Speech Lang. Process. 27, 2092–2102 (2019)
Erdogan, H., Hershey, J.R., Watanabe, S., Le Roux, J.: Phase-sensitive and recognition-boosted speech separation using deep recurrent neural networks. In: 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 708–712 (2015)
Williamson, D.S., Wang, Y., Wang, D.: Complex ratio masking for monaural speech separation. IEEE/ACM Trans. Audio Speech Lang. Process. 24, 483–492 (2015)
Luo, Y., Mesgarani, N.: Tasnet: time-domain audio separation network for real-time, single-channel speech separation. In: 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 696–700 (2018)
Luo, Y., Mesgarani, N.: Conv-tasnet: Surpassing ideal time–frequency magnitude masking for speech separation. IEEE/ACM trans. Audio Speech Lang. Process. 27, 1256–1266 (2019)
Stoller, D., Ewert, S., Dixon, S.: Wave-u-net: A multi-scale neural network for end-to-end audio source separation. Preprint at https://arXiv.org/arXiv:1806.03185 (2018)
Lam, M.W., Wang, J., Su, D., Yu, D.: Sandglasset: A light multi-granularity self-attentive network for time-domain speech separation. In: ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 5759–5763 (2021)
Subakan, C., Ravanelli, M., Cornell, S., Bronzi, M., Zhong, J.: Attention is all you need in speech separation. In: ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 21–25 (2021)
Gannot, S., Vincent, E., Markovich-Golan, S., Ozerov, A.: A consolidated perspective on multimicrophone speech enhancement and source separation. IEEE/ACM Trans. Audio Speech Lang. Process. 25, 692–730 (2017)
Wang, D., Chen, J.: Supervised speech separation based on deep learning: An overview. IEEE/ACM Trans. Audio Speech Lang. Process. 26, 1702–1726 (2018)
Erdogan, H., Hershey, J.R., Watanabe, S., Mandel, M.I., Le Roux, J.: Improved mvdr beamforming using single-channel mask prediction networks. In: Interspeech, pp. 1981–1985 (2016)
Heymann, J., Drude, L., Chinaev, A., Haeb-Umbach, R.: BLSTM supported GEV beamformer front-end for the 3rd CHiME challenge. In: 2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), pp. 444–451 (2015)
Yoshioka, T., Ito, N., Delcroix, M., Ogawa, A., Kinoshita, K., Fujimoto, M., Yu, C., Fabian, W.J., Espi, M., Higuchi, T.: The NTT CHiME-3 system: Advances in speech enhancement and recognition for mobile multi-microphone devices. In: 2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), pp. 436–443 (2015)
Barker, J., Marxer, R., Vincent, E., Watanabe, S.: The third ‘CHiME’ speech separation and recognition challenge: Analysis and outcomes. Comput. Speech Lang. 46, 605–626 (2017)
Wang, Z.-Q., Le Roux, J., Hershey, J.R.: Multi-channel deep clustering: Discriminative spectral and spatial embeddings for speaker-independent speech separation. In: 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1–5 (2018)
Wang, Z.-Q., Wang, D.: Combining spectral and spatial features for deep learning based blind speaker separation. IEEE/ACM Trans. Audio Speech Lang. Process. 27, 457–468 (2018)
Yoshioka, T., Erdogan, H., Chen, Z., Alleva, F.: Multi-microphone neural speech separation for far-field multi-talker speech recognition. In: 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 5739–5743 (2018)
Wang, Z.-Q., Wang, P., Wang, D.: Multi-microphone complex spectral mapping for utterance-wise and continuous speech separation. IEEE/ACM Trans. Audio Speech Lang. Process. 29, 2001–2014 (2021)
Luo, Y., Han, C., Mesgarani, N., Ceolini, E., Liu, S.-C.: FaSNet: Low-latency adaptive beamforming for multi-microphone audio processing. In: 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), pp. 260–267 (2019)
Luo, Y., Chen, Z., Mesgarani, N., Yoshioka, T.: End-to-end microphone permutation and number invariant multi-channel speech separation. In: ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6394–6398 (2020)
Wang, Z.-Q., Zhang, X., Wang, D.: Robust speaker localization guided by deep learning-based time-frequency masking. IEEE/ACM Trans. Audio Speech Lang. Process. 27, 178–188 (2018)
Chakrabarty, S., Wang, D., Habets, E.A.: Time-frequency masking based online speech enhancement with multi-channel data using convolutional neural networks. In: 2018 16th International Workshop on Acoustic Signal Enhancement (IWAENC), pp. 476–480 (2018)
Winter, S., Kellermann, W., Sawada, H., Makino, S.: MAP-based underdetermined blind source separation of convolutive mixtures by hierarchical clustering and-norm minimization. EURASIP J. Adv. Signal Process. 2007, 1–12 (2006)
Boeddeker, C., Heitkaemper, J., Schmalenstroeer, J., Drude, L., Heymann, J., Haeb-Umbach, R.: Front-end processing for the CHiME-5 dinner party scenario. in CHiME5 Workshop, Hyderabad, India (2018)
Mandel, M.I., Weiss, R.J., Ellis, D.P.: Model-based expectation-maximization source separation and localization. IEEE Trans. Audio Speech Lang. Process. 18, 382–394 (2009)
Gannot, S., Burshtein, D., Weinstein, E.: Signal enhancement using beamforming and nonstationarity with applications to speech. IEEE Trans. Signal Process. 49, 1614–1626 (2001)
Makino, S., Lee, T.-W., Sawada, H.: Blind Speech Separation. Springer (2007)
Quan, C., Li, X.: Multi-channel narrow-band deep speech separation with full-band permutation invariant training. In: ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 541–545 (2022)
Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 7132–7141 (2018)
Wang, Q., Wu, B., Zhu, P., Li, P., Zuo, W., Hu, Q.: ECA-Net: Efficient channel attention for deep convolutional neural networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11534–11542 (2020)
Woo, S., Park, J., Lee, J.-Y., Kweon, I.S.: Cbam: Convolutional block attention module. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 3–19 (2018)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
He, K., Zhang, X., Ren, S., Sun, J.: Identity mappings in deep residual networks. In: Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part IV 14, pp. 630-645 (2016)
Xie, S., Girshick, R., Dollár, P., Tu, Z., He, K.: Aggregated residual transformations for deep neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1492–1500 (2017)
Zagoruyko, S., Komodakis, N.: Wide residual networks. Preprint at https://arXiv.org/arXiv:1605.07146 (2016)
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M.: Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 115, 211–252 (2015)
Zhang, Z., Xu, Y., Yu, M., Zhang, S.-X., Chen, L., Williamson, D.S., Yu, D.: Multi-channel multi-frame ADL-MVDR for target speech separation. IEEE/ACM Trans. Audio Speech Lang. Process. 29, 3526–3540 (2021)
Fu, Y., Wu, J., Hu, Y., Xing, M., Xie, L.: Desnet: A multi-channel network for simultaneous speech dereverberation, enhancement and separation. In: 2021 IEEE Spoken Language Technology Workshop (SLT), pp. 857–864 (2021)
Xiang, X., Zhang, X., Chen, H.: A nested u-net with self-attention and dense connectivity for monaural speech enhancement. IEEE Signal Process. Lett. 29, 105–109 (2021)
Li, X., Wang, W., Hu, X., Yang, J.: Selective kernel networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 510–519 (2019)
Zhang, H., Wu, C., Zhang, Z., Zhu, Y., Lin, H., Zhang, Z., Sun, Y., He, T., Mueller, J., Manmatha, R.: Resnest: Split-attention networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2736–2746 (2022)
Dai, Y., Gieseke, F., Oehmcke, S., Wu, Y., Barnard, K.: Attentional feature fusion. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 3560–3569 (2021)
Le Roux, J., Wisdom, S., Erdogan, H., Hershey, J.R.: SDR–half-baked or well done? In: ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 626–630 (2019)
Vincent, E., Gribonval, R., Févotte, C.: Performance measurement in blind audio source separation. IEEE Trans. Audio Speech Lang. Process. 14, 1462–1469 (2006)
Rix, A.W., Beerends, J.G., Hollier, M.P., Hekstra, A.P.: Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs. In: 2001 IEEE international conference on acoustics, speech, and signal processing. Proceedings (Cat. No. 01CH37221), pp. 749–752 (2001)
Doclo, S., Gannot, S., Moonen, M., Spriet, A., Haykin, S., Liu, K.R.: Acoustic beamforming for hearing aid applications. In: Handbook on Array Processing and Sensor Networks, pp. 269–302. Wiley, Hoboken (2010)
Chen, H., Yi, Y., Feng, D., Zhang, P.: Beam-Guided TasNet: An iterative speech separation framework with multi-channel output. Preprint at https://arXiv.org/arXiv:2102.02998 (2021)
Gu, R., Wu, J., Zhang, S.-X., Chen, L., Xu, Y., Yu, M., Su, D., Zou, Y., Yu, D.: End-to-end multi-channel speech separation. Preprint at https://arXiv.org/arXiv:1905.06286 (2019)
Funding
The funding was supported by National Natural Science Foundation of China, 61571279.
Author information
Authors and Affiliations
Contributions
Conceptualization, HL and QH; methodology, HL and QH; software, HL; validation, HL and QH; formal analysis, QH; investigation, HL; resources, QH; data curation, HL; writing—original draft preparation, HL; writing—review and editing, HL and QH; visualization, HL; supervision, QH; project administration, QH; funding acquisition, QH. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflicts of interest.
Additional information
Communicated by J. Gao.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Li, H., Huang, Q. MAF-Net: multidimensional attention fusion network for multichannel speech separation. Multimedia Systems 29, 3703–3720 (2023). https://doi.org/10.1007/s00530-023-01155-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00530-023-01155-1