
Abstract
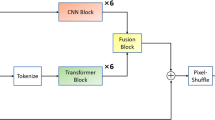
In recent years, deep learning has made remarkable breakthroughs in single-image super-resolution (SISR). However, the improvements often come with the increased network size, which is impractical for resource-constrained mobile devices. To alleviate this problem, an SISR method based on stepwise feedback training and multi-feature maps fusion (SFTMFM) is proposed in this paper, with fewer parameters amidst improved performance. Specifically, to better balance the performance and model parameters, a symmetrical CNN (SCNN) based on parameter sharing is constructed. In addition, to make up the deficiency of CNN module, the Swin Transformer layer (STL) is adopted to extract similar features over long distances. Lastly, to further improve the reconstruction ability of the model, a stepwise feedback training strategy is designed, which combines the cross-feature maps attention module as a feedback mechanism with the multi-feature maps fusion module to gradually reconstruct the model with higher-quality images. Under × 2 upscaling, our method achieves the PSNR(dB) of 38.10, 33.69, 32.25, 32.33, and 39.00 for SET5, SET14, BSD100, Urban100, and Managa109 datasets. Compared with the state-of-the-art lightweight SISR methods, our method shows better reconstruction performance and less computational cost.











Similar content being viewed by others


Data availability and access
The download address of DIV2K is https://data.vision.ee.ethz.ch/cvl/DIV2K/. The download address of Flickr2K is http://cv.snu.ac.kr/research/EDSR/Flickr2K.tar.
References
Dong, C., Loy, C.C., He, K., Tang, X.: Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 38(2), 295–307 (2016)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), pp. 770–778 (2016)
Kim, J., Lee, J.K., Lee, K.M.: Accurate image super-resolution using very deep convolutional networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), pp. 164–1654 (2016)
Lim, B., Son, S., Kim, H., Nah, S., Lee, K.M.: Enhanced deep residual networks for single image super-resolution. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops(CVPRW), pp. 136–144 (2017)
Kim, J., Lee, J.K., Lee, K.M.: Deeply-recursive convolutional network for image super-resolution. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), pp. 1637–1645 (2016)
Tai, Y., Yang, J., Liu, X.: Image super-resolution via deep recursive residual network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3147–3155 (2017)
Tai, Y., Yang, J., Liu, X., Xu, C.: Memnet: A persistent memory network for image restoration. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV), pp. 4539–4547 (2017)
Ahn, N., Kang, B., Sohn. K.A.: Fast, accurate, and lightweight super-resolution with cascading residual network. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 252–268 (2018)
Li, Z., Yang, J., Liu, Z., et al.: Feedback network for image super-resolution. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), PP. 3867–3876 (2019)
Zou, Y., Yang, X., Albertini, M.K., et al.: LMSN: a lightweight multi-scale network for single image super-resolution. Multimedia Syst. 27, 845–856 (2021)
Chen, Y., Xia, R., Yang, K., et al.: DGCA: high resolution image inpainting via DR-GAN and contextual attention. Multimedia Tools and Applications. Early Accepted (2023)
Chen, F., Zhang, H., Hu, K., et al.: Enhanced Training of Query-Based Object Detection via Selective Query Recollection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR), pp. 23756–23765 (2023)
Zhang, J., Huang. H., Jin, X., et al.: Siamese visual tracking based on criss-cross attention and improved head network. Multimedia Tools and Applications. Early Accepted (2023)
Zhang, J., Zheng, Z., Xie, X., et al.: ReYOLO: a traffic sign detector based on network reparameterization and features adaptive weighting. J Ambient Intell Smart Environ. 14(4), 1–18 (2022)
Zhang, Y., Chen, H., Chen, X., et al.: Data-free knowledge distillation for image super-resolution. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 7852–7861(2021)
Ma, C., Zhang, J., Zhou, J., et al.: Learning series-parallel lookup tables for efficient image super-resolution. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 305–321 (2022)
Chen, Y., Xia, R., Yang, K., et al.: MFFN: Image super-resolution via multi-level features fusion network. The Visual Computer. Early Accepted (2023)
Vaswani, A., Shazeer, N., Parmar, N., et al.: Attention is all you need. In: Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS) (2017)
Zhang, Y., Li, K., Li, K., et al.: Image super-resolution using very deep residual channel attention networks. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 286–301 (2018)
Chen, C., Gong, D., Wang, H., et al.: Learning spatial attention for face super-resolution. IEEE Trans. Image Process. 30, 1219–1231 (2020)
Liu, Z., Lin, Y., Cao, Y., et al.: Swin transformer: Hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF International Conference on Computer Vision(ICCV), pp. 10012–10022 (2021)
Dong, C., Loy, C.C., Tang, X.: Accelerating the super-resolution convolutional neural network. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 391–407 (2016)
Shi, W., Caballero, J., Huszár, F., et al.: Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1874–1883 (2016)
Agustsson, E., Timofte, R.: Ntire 2017 challenge on single image super-resolution: Dataset and study. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pp. 126–135 (2017)
Hui, Z., Wang, X., Gao, X.: Fast and accurate single image super-resolution via information distillation network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 723–731 (2018)
Haris, M., Shakhnarovich, G., Ukita, N.: Deep back-projection networks for super-resolution. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1664–1673 (2018)
Creswell, A., White, T., Dumoulin, V., et al.: Generative adversarial networks: an overview. IEEE Signal Process. Mag. 35(1), 53–65 (2018)
Shamsolmoali, P., Zareapoor, M., Wang, R., et al.: G-GANISR: gradual generative adversarial network for image super resolution. Neurocomputing 366, 140–153 (2019)
Hore, A., Ziou, D.: Image quality metrics: PSNR vs. SSIM. In: Proceedings of the 2010 20th international conference on pattern recognition, pp. 2366–2369 (2010)
Hui, Z., Gao, X., Yang, Y., et al.: Lightweight image super-resolution with information multi-distillation network. In: Proceedings of the 27th ACM International Conference on Multimedia, pp. 2024–2032 (2019)
Liu, J., Tang, J., Wu, G.: Residual feature distillation network for lightweight image super-resolution. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 41–55 (2020)
Zhang, K., Danelljan, M., Li, Y., et al.: Aim 2020 challenge on efficient super-resolution: Methods and results. In Proceedings of the European Conference on Computer Vision (ECCV), pp. 5–40 (2020)
Tian, L., Gao, S., Tu, G.: Lightweight feature separation, fusion and optimization networks for accurate image super-resolution. Multimedia Syst. 28, 611–622 (2022)
Liu, Y., Yang, D., Zhang, F., et al.: Deep recurrent residual channel attention network for single image super-resolution. The Visual Computer. Early Accepted (2023)
Zeng, H., Wu, Q., Zhang, J., et al.: Lightweight subpixel sampling network for image super-resolution. The Visual Compute. Early Accepted (2023)
Liang, J., Cao, J., Sun, G., et al.: Swinir: Image restoration using swin transformer. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp. 1833–1844 (2021)
Zou, W., Ye, T., Zheng, W., et al.: Self-calibrated efficient transformer for lightweight super-resolution. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 930–939 (2022).
Lu, Z., Li, J., Liu, H., et al.: Transformer for single image super-resolution. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 457–466 (2022)
Gu, J., Lu, H., Zuo, W., et al.: Blind super-resolution with iterative kernel correction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1604–1613 (2019)
Bevilacqua, M., Roumy, A., Guillemot, C., et al.: Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In: Proceedings of the British Machine Vision Conference (BMVC) (2012)
Zeyde, R., Elad, M., Protter, M.: On single image scale-up using sparse-representations. In: Proceedings of the International Conference on Curves and Surfaces, pp. 711–730 (2012)
Martin, D., Fowlkes, C., Tal, D., et al.: A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp. 416–423 (2001)
Huang, J.B., Singh, A., Ahuja, N.: Single image super-resolution from transformed self-exemplars. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5197–5206 (2015)
Matsui, Y., Ito, K., Aramaki, Y., et al.: Sketch-based manga retrieval using manga109 dataset. Multimedia Tools Appl. 76, 21811–21838 (2017)
Wang, Z., Bovik, A.C., Sheikh, H.R., et al.: Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process. 13(4), 600–612 (2004)
Li, W., Zhou, K., Qi, L., et al.: Best-buddy gans for highly detailed image super-resolution. In: Proceedings of the AAAI Conference on Artificial Intelligence, pp. 36(2): 1412–1420 (2022)
Song, J., Yi, H., Xu, W., et al.: Gram-GAN: image super-resolution based on gram matrix and discriminator perceptual loss. Sensors. 23(4): 2098 (2023)
Acknowledgements
This work was supported by the Beijing Natural Science Foundation (No. 4232012) and National Science Foundation of China (No. 62172029).
Author information
Authors and Affiliations
Contributions
XY contributed to conceptualization, formal analysis, investigation, methodology, roles/writing—original draft, and software. HC contributed to conceptualization, formal analysis, funding acquisition, investigation, and methodology, supervision, and writing—review and editing. YL was involved in funding acquisition, methodology, and writing—review and editing. JS was involved in writing—review and editing. JW provided software.
Corresponding author
Ethics declarations
Conflict of interest
All authors disclosed no relevant relationships.
Ethical and informed consent for data used
DIV2K and Flickr2K are public datasets that can be used by researchers as test set.
Additional information
Communicated by Y. Zhang.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Yao, X., Chen, H., Li, Y. et al. Lightweight image super-resolution based on stepwise feedback mechanism and multi-feature maps fusion. Multimedia Systems 30, 39 (2024). https://doi.org/10.1007/s00530-023-01242-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00530-023-01242-3