
Abstract
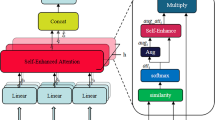
Automated image caption generation with attention mechanisms focuses on visual features including objects, attributes, actions, and scenes of the image to understand and provide more detailed captions, which attains great attention in the multimedia field. However, deciding which aspects of an image to highlight for better captioning remains a challenge. Most advanced captioning models utilize only one attention module to assign attention weights to visual vectors, but this may not be enough to create an informative caption. To tackle this issue, we propose an innovative and well-designed Guided Visual Attention (GVA) approach, incorporating an additional attention mechanism to re-adjust the attentional weights on the visual feature vectors and feed the resulting context vector to the language LSTM. Utilizing the first-level attention module as guidance for the GVA module and re-weighting the attention weights significantly enhances the caption’s quality. Recently, deep neural networks have allowed the encoder-decoder architecture to make use visual attention mechanism, where faster R-CNN is used for extracting features in the encoder and a visual attention-based LSTM is applied in the decoder. Extensive experiments have been implemented on both the MS-COCO and Flickr30k benchmark datasets. Compared with state-of-the-art methods, our approach achieved an average improvement of 2.4% on BLEU@1 and 13.24% on CIDEr for the MSCOCO dataset, as well as 4.6% on BLEU@1 and 12.48% on CIDEr score for the Flickr30K datasets, based on the cross-entropy optimization. These results demonstrate the clear superiority of our proposed approach in comparison to existing methods using standard evaluation metrics. The implementing code can be found here: (https://github.com/mdbipu/GVA).








Similar content being viewed by others

Data and materials
The MS COCO dataset is accessible at the website https://cocodataset.org/. To access the Flickr30k dataset, researchers can submit a request at https://shannon.cs.illinois.edu/DenotationGraph/. The code used to evaluate the metrics is publicly available on the GitHub repository https://github.com/tylin/coco-caption.
References
Yuan, A., Li, X., Lu, X.: 3G structure for image caption generation. Neurocomputing (2019). https://doi.org/10.1016/j.neucom.2018.10.059
Stefanini, M., Cornia, M., Baraldi, L., Cascianelli, S., Fiameni, G., Cucchiara, R.: From show to tell: a survey on deep learning-based image captioning. IEEE Trans. Pattern Anal. Mach. Intell. 45, 539–559 (2023). https://doi.org/10.1109/TPAMI.2022.3148210
Jiang, W., Ma, L., Jiang, Y.-G., Liu, W., Zhang, T.: Recurrent fusion network for image captioning. In: Proceedings of the European conference on computer vision (ECCV), pp. 499–515 (2018)
Wei, H., Li, Z., Zhang, C., Ma, H.: The synergy of double attention: combine sentence-level and word-level attention for image captioning. Comput. Vis. Image Underst. (2020). https://doi.org/10.1016/j.cviu.2020.103068
Vinyals, O., Toshev, A., Bengio, S., & Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE conference on computer vision and pattern recognition pp. 3156–3164 (2015).
Wang, K., Zhang, X., Wang, F., Wu, T.Y., Chen, C.M.: Multilayer dense attention model for image caption. IEEE Access (2019). https://doi.org/10.1109/ACCESS.2019.2917771
Sur, C.: MRRC: multiple role representation crossover interpretation for image captioning with R-CNN feature distribution composition (FDC). Multimed. Tools Appl. 80, 18413–18443 (2021). https://doi.org/10.1007/s11042-021-10578-9
Zhou, Y., Hu, Z., Zhac, Y., Liu, X., & Hong, R.: Enhanced text-guided attention model for image captioning. In 2018 IEEE fourth international conference on multimedia big data (BigMM) pp. 1–5 (2018)
Zhao, W., Wu, X., Luo, J.: Cross-domain image captioning via cross-modal retrieval and model adaptation. IEEE Trans. Image Process. (2021). https://doi.org/10.1109/TIP.2020.3042086
Al-Qatf, M., Wang, X., Hawbani, A., Abdusallam, A., Alsamhi, S.H.: Image captioning with novel topics guidance and retrieval-based topics re-weighting. IEEE Trans. Multimed. (2022). https://doi.org/10.1109/TMM.2022.3202690
Liu, X., Xu, Q.: Adaptive attention-based high-level semantic introduction for image caption. ACM Trans. Multimed. Comput. Commun. Appl. (2021). https://doi.org/10.1145/3409388
Cheng, L., Wei, W., Mao, X., Liu, Y., Miao, C.: Stack-VS: stacked visual-semantic attention for image caption generation. IEEE Access 8, 154953–154965 (2020). https://doi.org/10.1109/ACCESS.2020.3018752
Anderson, P., He, X., Buehler, C., Teney, D., Johnson, M., Gould, S., Zhang, L.: Bottom–up and top–down attention for image captioning and visual question answering. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6077–6086. IEEE (2018)
Deorukhkar, K., Ket, S.: A detailed review of prevailing image captioning methods using deep learning techniques. Multimed. Tools Appl. (2022). https://doi.org/10.1007/s11042-021-11293-1
Rennie, S.J., Marcheret, E., Mroueh, Y., Ross, J., Goel, V.: Self-critical sequence training for image captioning. In: Proceedings—30th IEEE Conference on Computer Vision and Pattern Recognition. CVPR (2017)
do Carmo Nogueira, T., Vinhal, C.D.N., da Cruz Júnior, G., Ullmann, M.R.D., Marques, T.C.: A reference-based model using deep learning for image captioning. Multimed. Syst. (2022). https://doi.org/10.1007/s00530-022-00937-3
Wang, S., Lan, L., Zhang, X., Luo, Z.: GateCap: gated spatial and semantic attention model for image captioning. Multimed. Tools Appl. 79, 11531–11549 (2020). https://doi.org/10.1007/s11042-019-08567-0
Xiao, F., Xue, W., Shen, Y., Gao, X.: A new attention-based LSTM for image captioning. Neural. Process. Lett. 54, 3157–3171 (2022). https://doi.org/10.1007/s11063-022-10759-z
Zhao, D., Yang, R., Wang, Z., Qi, Z.: A cooperative approach based on self-attention with interactive attribute for image caption. Multimed. Tools Appl. 82, 1223–1236 (2023). https://doi.org/10.1007/s11042-022-13279-z
Sasibhooshan, R., Kumaraswamy, S., Sasidharan, S.: Image caption generation using visual attention prediction and contextual spatial relation extraction. J. Big Data (2023). https://doi.org/10.1186/s40537-023-00693-9
Zhou, D., Yang, J., Zhang, C., Tang, Y.: Joint Science Network and attention-guided for image captioning. In: Proceedings—IEEE International Conference on Data Mining. ICDM (2021)
Pan, Y., Yao, T., Li, Y., Mei, T.: X-Linear attention networks for image captioning. In: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pp. 10968–10977. IEEE Computer Society (2020)
Wang, Z., Shi, S., Zhai, Z., Wu, Y., Yang, R.: ArCo: attention-reinforced transformer with contrastive learning for image captioning. Image Vis. Comput. (2022). https://doi.org/10.1016/j.imavis.2022.104570
Wu, J., Chen, T., Wu, H., Yang, Z., Luo, G., Lin, L.: Fine-grained image captioning with global-local discriminative objective. IEEE Trans. Multimed. 23, 2413–2427 (2021). https://doi.org/10.1109/TMM.2020.3011317
Fang, Z., Wang, J., Hu, X., Liang, L., Gan, Z., Wang, L., Yang, Y., Liu, Z.: Injecting semantic concepts into end-to-end image captioning. In: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition pp. 18009–18019 (2022)
Karpathy, A., Fei-Fei, L.: Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 3128–3137 (2015)
Ren, S., He, K., Girshick, R., Sun, J.: Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. (2017). https://doi.org/10.1109/TPAMI.2016.2577031
Chen, L., Zhang, H., Xiao, J., Nie, L., Shao, J., Liu, W., Chua, T.-S.: SCA-CNN: Spatial and channel-wise attention in convolutional networks for image captioning. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6298–6306. IEEE (2017)
Zhang, H., Ma, C., Jiang, Z., Lian, J.: Image caption generation using contextual information fusion with Bi-LSTM-s. IEEE Access 11, 134–143 (2023). https://doi.org/10.1109/ACCESS.2022.3232508
Naqvi, N., Ye, Z.F.: Image captions: global-local and joint signals attention model (GL-JSAM). Multimed. Tools Appl. (2020). https://doi.org/10.1007/s11042-020-09128-6
Sharma, H., Srivastava, S.: Multilevel attention and relation network based image captioning model. Multimed. Tools Appl. (2022). https://doi.org/10.1007/s11042-022-13793-0
Jiang, W., Wang, W., Hu, H.: Bi-directional co-attention network for image captioning. ACM Trans. Multimed. Comput. Commun. Appl. 17, 1–20 (2021). https://doi.org/10.1145/3460474
Zhong, X., Nie, G., Huang, W., Liu, W., Ma, B., Lin, C.W.: Attention-guided image captioning with adaptive global and local feature fusion. J. Vis. Commun. Image Represent. (2021). https://doi.org/10.1016/j.jvcir.2021.103138
Xu, K., Ba, J.L., Kiros, R., Cho, K., Courville, A., Salakhutdinov, R., Zemel, R.S., Bengio, Y.: Show, attend and tell: neural image caption generation with visual attention. In: 32nd International Conference on Machine Learning. ICML (2015)
Li, J., Wang, Y., Zhao, D.: Layer-wise enhanced transformer with multi-modal fusion for image caption. Multimed. Syst. (2022). https://doi.org/10.1007/s00530-022-01036-z
Wang, J., Wang, W., Wang, L., Wang, Z., Feng, D.D., Tan, T.: Learning visual relationship and context-aware attention for image captioning. Pattern Recognit. (2020). https://doi.org/10.1016/j.patcog.2019.107075
Wang, S., Lan, L., Zhang, X., Dong, G., Luo, Z.: Cascade semantic fusion for image captioning. IEEE Access 7, 66680–66688 (2019). https://doi.org/10.1109/ACCESS.2019.2917979
Wu, C., Yuan, S., Cao, H., Wei, Y., Wang, L.: Hierarchical attention-based fusion for image caption with multi-grained rewards. IEEE Access 8, 57943–57951 (2020). https://doi.org/10.1109/ACCESS.2020.2981513
Li, X., Jiang, S.: Know more say less: image captioning based on scene graphs. IEEE Trans. Multimed. 21, 2117–2130 (2019). https://doi.org/10.1109/TMM.2019.2896516
Zhou, L., Zhang, Y., Jiang, Y.G., Zhang, T., Fan, W.: Re-caption: saliency-enhanced image captioning through two-phase learning. IEEE Trans. Image Process. 29, 694–709 (2020). https://doi.org/10.1109/TIP.2019.2928144
Yan, C., Hao, Y., Li, L., Yin, J., Liu, A., Mao, Z., Chen, Z., Gao, X.: Task-adaptive attention for image captioning. IEEE Trans. Circuits Syst. Video Technol. 32, 43–51 (2022). https://doi.org/10.1109/TCSVT.2021.3067449
Lu, J., Xiong, C., Parikh, D., Socher, R.: Knowing when to look: adaptive attention via a visual sentinel for image captioning. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3242–3250. IEEE (2017)
Gao, L., Li, X., Song, J., Shen, H.T.: Hierarchical LSTMs with adaptive attention for visual captioning. IEEE Trans. Pattern Anal. Mach. Intell. (2020). https://doi.org/10.1109/TPAMI.2019.2894139
Tan, Y.H., Chan, C.S.: Phrase-based image caption generator with hierarchical LSTM network. Neurocomputing (2019). https://doi.org/10.1016/j.neucom.2018.12.026
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition pp. 770-778 (2016)
Parvin, H., Naghsh-Nilchi, A.R., Mohammadi, H.M.: Transformer-based local-global guidance for image captioning. Expert Syst. Appl. 223, 119774 (2023). https://doi.org/10.1016/j.eswa.2023.119774
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft COCO: Common objects in context. In: Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) pp. 740-755 (2014)
Plummer, B.A., Wang, L., Cervantes, C.M., Caicedo, J.C., Hockenmaier, J., Lazebnik, S.: Flickr30k entities: collecting region-to-phrase correspondences for richer image-to-sentence models. Int. J. Comput. Vis. (2017). https://doi.org/10.1007/s11263-016-0965-7
Papineni, K., Roukos, S., Ward, T., Zhu, W.: BLEU: a method for automatic evaluation of machine translation. In: Computational Linguistics pp. 311-318 (2002)
Lavie, A., Agarwal, A.: METEOR: An automatic metric for MT evaluation with high levels of correlation with human judgments. In: Proceedings of the Second Workshop on Statistical Machine Translation (2007)
Lin, C.Y.: Rouge: a package for automatic evaluation of summaries. Proceedings of the workshop on text summarization branches out (WAS 2004) pp. 74-81 (2004)
Vedantam, R., Zitnick, C.L., Parikh, D.: CIDEr: consensus-based image description evaluation. In: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition pp. 4566-4575 (2015)
Anderson, P., Fernando, B., Johnson, M., & Gould, S.: Spice: Semantic propositional image caption evaluation. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part V 14 pp. 382-398 (2016).
Kingma, D.P., Ba, J.L.: Adam: a method for stochastic optimization. In: 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings (2015) arXiv preprint arXiv:1412.6980.
Cohen, E., Beck, J.C.: Empirical analysis of beam search performance degradation in neural sequence models. In: 36th International Conference on Machine Learning, ICML 2019 pp. 1290-1299 (2019)
Zhang, Z., Wu, Q., Wang, Y., Chen, F.: High-quality image captioning with fine-grained and semantic-guided visual attention. IEEE Trans. Multimed. (2019). https://doi.org/10.1109/TMM.2018.2888822
Abdussalam, A., Ye, Z., Hawbani, A., Al-Qatf, M., Khan, R.: NumCap: a number-controlled multi-caption image captioning network. ACM Trans. Multimed. Comput. Commun. Appl. 19, 1–24 (2023). https://doi.org/10.1145/3576927
Li, X., Yuan, A., Lu, X.: Multi-modal gated recurrent units for image description. Multimed. Tools Appl. (2018). https://doi.org/10.1007/s11042-018-5856-1
Acknowledgements
This work is supported by the CAS-TWAS President’s Fellowship for Ph.D. program.
Author information
Authors and Affiliations
Contributions
MBH: conceptualized and designed the core concept, contributed to paper writing, revisions, and conducted experiments. AA: Contributed to the conceptualization to build the core idea and revisions. MIH: modify the introduction and revised the full manuscript. ZY supervised and gave constructive suggestions to improve the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Hossen, M.B., Ye, Z., Abdussalam, A. et al. GVA: guided visual attention approach for automatic image caption generation. Multimedia Systems 30, 50 (2024). https://doi.org/10.1007/s00530-023-01249-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00530-023-01249-w