
Abstract
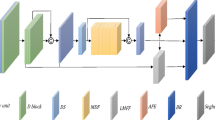
Semantic segmentation of street scenes is important for the vision-based application of autonomous driving. Recently, high-accuracy networks based on deep learning have been widely applied to semantic segmentation, but their inference speeds are slow. In order to achieve faster speed, most popular real-time network architectures adopt stepwise downsampling operation in the backbone to obtain features with different sizes. However, they ignore the misalignment between feature maps from different levels, and their simple feature aggregation using element-wise addition or channel-wise concatenation may submerge the useful information in a large number of useless information. To deal with these problems, we propose a gated feature aggregation and alignment network (GFAANet) for real-time semantic segmentation of street scenes. In GFAANet, a feature alignment aggregation module is developed to effectively align and aggregate the feature maps from different levels. And we present a gated feature aggregation module to selectively aggregate and refine effective information from multi-stage features of the backbone network using gates. Furthermore, a depthwise separable pyramid pooling module based on low-resolution feature maps is designed as a context extractor to expand the effective receptive fields and fuse multi-scale contexts. Experimental results on two challenging street scene benchmark datasets show that GFAANet achieves highest accuracy in real-time semantic segmentation of street scenes, as compared with the state-of-the-art. We conclude that our GFAANet can quickly and effectively segment street scene images, which may provide technical support for autonomous driving.








Similar content being viewed by others


Explore related subjects
Discover the latest articles and news from researchers in related subjects, suggested using machine learning.Data availability
Cityscapes [36] and CamVid [37] datasets are used during the current study, where Cityscapes dataset is available at https://www.cityscapes-dataset.com/, and CamVid dataset is available at http://mi.eng.cam.ac.uk/research/projects/VideoRec/CamVid/.
References
Zhang, X., Cao, X., Wang, J., et al.: G-unext: a lightweight mlp-based network for reducing semantic gap in medical image segmentation. Multimed. Syst. 29(6), 3431–3446 (2023)
Kampffmeyer, M., Salberg, AB., Jenssen, R.: Semantic segmentation of small objects and modeling of uncertainty in urban remote sensing images using deep convolutional neural networks. In: IEEE conference on computer vision and pattern recognition workshops, pp 680–688 (2016)
Xu, H., Gao, Y., Yu, F., et al.: End-to-end learning of driving models from large-scale video datasets. In: IEEE conference on computer vision and pattern recognition, pp 2174–2182 (2017)
Long, J., Shelhamer, E., Darrell, T.: Fully convolutional networks for semantic segmentation. In: IEEE conference on computer vision and pattern recognition, pp 3431–3440 (2015)
Yu, F., Koltun, V.: Multi-scale context aggregation by dilated convolutions. In: International Conference on Learning Representations, pp 2–4 (2016)
Chen, L.C., Papandreou, G., Kokkinos, I., et al.: Deeplab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 40(4), 834–848 (2017)
Zhao, H., Shi, J., Qi, X., et al.: Pyramid scene parsing network. In: IEEE conference on computer vision and pattern recognition, pp 2881–2890 (2017)
Chen, LC., Zhu, Y., Papandreou, G., et al.: Encoder-decoder with atrous separable convolution for semantic image segmentation. In: European conference on computer vision, pp 801–818 (2018)
Pang, Y., Li, Y., Shen, J., et al.: Towards bridging semantic gap to improve semantic segmentation. In: IEEE/CVF International Conference on Computer Vision, pp 4230–4239 (2019)
Huang, Z., Wang, X., Huang, L., et al.: Ccnet: Criss-cross attention for semantic segmentation. In: IEEE/CVF international conference on computer vision, pp 603–612 (2019)
Fu, J., Liu, J., Tian, H., et al.: Dual attention network for scene segmentation. In: IEEE/CVF conference on computer vision and pattern recognition, pp 3146–3154 (2019)
Chen, W., Zhu, X., Sun, R., et al.: Tensor low-rank reconstruction for semantic segmentation. In: European conference on computer vision, pp 52–69 (2020)
Liu, Y., Chen, Y., Lasang, P., et al.: Covariance attention for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 44(4), 1805–1818 (2020)
Yuan, Y., Chen, X., Wang, J.: Object-contextual representations for semantic segmentation. In: European conference on computer vision, pp 173–190 (2020)
Ji, J., Shi, R., Li, S., et al.: Encoder-decoder with cascaded crfs for semantic segmentation. IEEE Trans. Circ. Syst. Video Technol. 31(5), 1926–1938 (2020)
Hou Q, Zhang L, Cheng MM, et al.: Strip pooling: rethinking spatial pooling for scene parsing. In: IEEE/CVF conference on computer vision and pattern recognition, pp 4003–4012 (2020)
Li, L., Zhou, T., Wang, W., et al.: Deep hierarchical semantic segmentation. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 1246–1257 (2022)
Zhang, Y., Pang, B., Lu, C.: Semantic segmentation by early region proxy. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 1258–1268 (2022)
Badrinarayanan, V., Kendall, A., Cipolla, R.: Segnet: a deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 39(12), 2481–2495 (2017)
Romera, E., Alvarez, J.M., Bergasa, L.M., et al.: Erfnet: efficient residual factorized convnet for real-time semantic segmentation. IEEE Trans. Intell. Transp. Syst. 19(1), 263–272 (2017)
Mehta, S., Rastegari, M., Caspi, A., et al.: Espnet: Efficient spatial pyramid of dilated convolutions for semantic segmentation. In: European conference on computer vision, pp 552–568 (2018)
Zhao, H., Qi, X., Shen, X., et al.: Icnet for real-time semantic segmentation on high-resolution images. In: European conference on computer vision, pp 405–420 (2018)
Yu, C., Wang, J., Peng, C., et al.: Bisenet: Bilateral segmentation network for real-time semantic segmentation. In: European conference on computer vision, pp 325–341 (2018)
Lo, SY., Hang, HM., Chan, SW., et al.: Efficient dense modules of asymmetric convolution for real-time semantic segmentation. In: ACM multimedia Asia, pp 1–6 (2019)
Wang, Y., Zhou, Q., Liu, J., et al.: Lednet: a lightweight encoder-decoder network for real-time semantic segmentation. In: IEEE international conference on image processing, pp 1860–1864 (2019)
Orsic, M., Kreso, I., Bevandic, P., et al.: In defense of pre-trained imagenet architectures for real-time semantic segmentation of road-driving images. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 12607–12616 (2019)
Li, H., Xiong, P., Fan, H., et al.: Dfanet: Deep feature aggregation for real-time semantic segmentation. In: IEEE/CVF conference on computer vision and pattern recognition, pp 9522–9531 (2019)
Jiang, W., Xie, Z., Li, Y., et al.: Lrnnet: a light-weighted network with efficient reduced non-local operation for real-time semantic segmentation. In: IEEE international conference on multimedia and expo workshops, pp 1–6 (2020)
Yu, C., Gao, C., Wang, J., et al.: Bisenet v2: bilateral network with guided aggregation for real-time semantic segmentation. Int. J. Comput. Vis. 129, 3051–3068 (2021)
Nirkin, Y., Wolf, L., Hassner, T.: Hyperseg: Patch-wise hypernetwork for real-time semantic segmentation. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 4061–4070 (2021)
Wu, Y., Jiang, J., Huang, Z., et al.: Fpanet: feature pyramid aggregation network for real-time semantic segmentation. Appl. Intell. 52(3), 3319–3336 (2022)
Lu, M., Chen, Z., Liu, C., et al.: Mfnet: multi-feature fusion network for real-time semantic segmentation in road scenes. IEEE Trans. Intell. Transp. Syst. 23(11), 20991–21003 (2022)
Mazzini, D.: Guided upsampling network for real-time semantic segmentation. In: British Machine Vision Conference, pp 117–125 (2018)
Li, X., You, A., Zhu, Z., et al.: Semantic flow for fast and accurate scene parsing. In: European conference on computer vision, pp 775–793 (2020)
Huang, Z., Wei, Y., Wang, X., et al.: Alignseg: feature-aligned segmentation networks. IEEE Trans. Pattern Anal. Mach. Intell. 44(1), 550–557 (2021)
Cordts, M., Omran, M., Ramos, S., et al: The cityscapes dataset for semantic urban scene understanding. In: IEEE conference on computer vision and pattern recognition, pp 3213–3223 (2016)
Brostow, G.J., Fauqueur, J., Cipolla, R.: Semantic object classes in video: a high-definition ground truth database. Pattern Recog. Lett. 30(2), 88–97 (2009)
He, K., Zhang, X., Ren, S., et al: Deep residual learning for image recognition. In: IEEE conference on computer vision and pattern recognition, pp 770–778 (2016)
Chollet, F.: Xception: deep learning with depthwise separable convolutions. In: IEEE conference on computer vision and pattern recognition, pp 1251–1258 (2017)
Sandler, M., Howard, A., Zhu, M., et al: Mobilenetv2: inverted residuals and linear bottlenecks. In: IEEE conference on computer vision and pattern recognition, pp 4510–4520 (2018)
Funding
This work was fully supported by National Natural Science Foundation of China under Project no. 61903195.
Author information
Authors and Affiliations
Contributions
Qian Liu: conceptualization, methodology, supervision, writing—original draft, writing—review and editing. Zhensheng Li: Formal analysis, software, investigation, validation, visualization, writing—original draft, writing—review and editing. Youwei Qi: Resources. Cunbao Wang: Data Curation.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no Conflict of interest.
Research involving human participants and/or animals
This article does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Communicated by Pietro Pala.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Liu, Q., Li, Z., Qi, Y. et al. Gated feature aggregate and alignment network for real-time semantic segmentation of street scenes. Multimedia Systems 30, 213 (2024). https://doi.org/10.1007/s00530-024-01429-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00530-024-01429-2