
Abstract
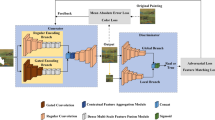
Thangka, as a precious heritage of painting art, holds irreplaceable research value due to its richness in Tibetan history, religious beliefs, and folk culture. However, it is susceptible to partial damage and form distortion due to natural erosion or inadequate conservation measures. Given the complexity of textures and rich semantics in thangka images, existing image inpainting methods struggle to recover their original artistic style and intricate details. In this paper, we propose a novel approach combining discrete codebook learning with a transformer for image inpainting, tailored specifically for thangka images. In the codebook learning stage, we design an improved network framework based on vector quantization (VQ) codebooks to discretely encode intermediate features of input images, yielding a context-rich discrete codebook. The second phase introduces a parallel transformer module based on a cross-shaped window, which efficiently predicts the index combinations for missing regions under limited computational cost. Furthermore, we devise a multi-scale feature guidance module that progressively fuses features from intact areas with textural features from the codebook, thereby enhancing the preservation of local details in non-damaged regions. We validate the efficacy of our method through qualitative and quantitative experiments on datasets including Celeba-HQ, Places2, and a custom thangka dataset. Experimental results demonstrate that compared to previous methods, our approach successfully reconstructs images with more complete structural information and clearer textural details.










Similar content being viewed by others


Data availability
For publicly accessible data resources, our study employed the [Celeba-HQ dataset] and the [Places2 dataset]; further details can be found in references [48] and [49], respectively. Moreover, the [Thangka dataset] used in this research was independently constructed by the authors. Due to the sensitivity of the data and considerations for the continuity of upcoming research projects, this self-made Thangka dataset is presently not available for public access. We recognize the importance of data sharing in facilitating scientific validation and progress; hence, we are willing to discuss the potential for data sharing with scholars who have particular research requirements.
References
Bertalmio, M., Sapiro, G., Caselles, V., Ballester, C.: Image inpainting. In: Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques, pp. 417–424 (2000)
Chan, T.F., Shen, J.: Nontexture inpainting by curvature-driven diffusions. J. Vis. Commun. Image Represent. 12(4), 436–449 (2001)
Komodakis, N., Tziritas, G.: Image completion using efficient belief propagation via priority scheduling and dynamic pruning. IEEE Trans. Image Process. 16(11), 2649–2661 (2007)
Cui, Y., Ren, W., Cao, X., Knoll, A.: Image restoration via frequency selection. IEEE Trans. Pattern Anal. Mach. Intell. 46(2), 1093–1108 (2023)
Pathak, D., Krahenbuhl, P., Donahue, J., Darrell, T., Efros, A. A.: Context encoders: feature learning by inpainting. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2536–2544 (2016)
Iizuka, S., Simo-Serra, E., Ishikawa, H.: Globally and locally consistent image completion. ACM Trans. Graph. 36(4), 1–14 (2017)
Wang, Y., Tao, X., Qi, X., Shen, X., Jia, J.: Image inpainting via generative multi-column convolutional neural networks. Adv. Neural Inf. Process. Syst. 31 (2018)
Cui, Y., Ren, W., Yang, S., Cao, X., Knoll, A.: Irnext: rethinking convolutional network design for image restoration. In: International Conference On Machine Learning (2023)
Yu, J., Lin, Z., Yang, J., Shen, X., Lu, X., Huang, T. S.: Generative image inpainting with contextual attention. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5505–5514 (2018)
Sagong, M. C., Shin, Y. G., Kim, S. W., Park, S., Ko, S. J.: Pepsi: Fast image inpainting with parallel decoding network. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11360–11368 (2019)
Xiong, W., Yu, J., Lin, Z., Yang, J., Lu, X., Barnes, C., Luo, J.: Foreground-aware image inpainting. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5840–5848 (2019)
Guo, X., Yang, H., Huang, D.: Image inpainting via conditional texture and structure dual generation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 14134–14143 (2021)
Dong, Q., Cao, C., Fu, Y.: Incremental transformer structure enhanced image inpainting with masking positional encoding. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11358–11368 (2022)
Bai, J., Fan, Y., Zhao, Z., Zheng, L.: Image inpainting technique incorporating edge prior and attention mechanism. Comput. Mater. Contin. 78(1) (2024)
Song, Y., Yang, C., Shen, Y., Wang, P., Huang, Q., Kuo, C. C. J.: Spg-net: segmentation prediction and guidance network for image inpainting. arXiv preprint arXiv:1805.03356 (2018)
Liao, L., Xiao, J., Wang, Z., Lin, C. W., Satoh, S.I.: Guidance and evaluation: semantic-aware image inpainting for mixed scenes. In: Computer Vision–ECCV 2020: 16th European Conference, pp. 683–700. Springer, Berlin (2020)
Chen, M., Radford, A., Child, R., Wu, J., Jun, H., Luan, D., Sutskever, I.: Generative pretraining from pixels. In: International Conference on Machine Learning, pp. 1691–1703 (2020)
Chen, Y., Dai, X., Chen, D., Liu, M., Dong, X., Yuan, L., Liu, Z.: Mobile-former: Bridging mobilenet and transformer. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5270–5279 (2022)
Yu, Z., Li, X., Sun, L., Zhu, J., Lin, J.: A composite transformer-based multi-stage defect detection architecture for sewer pipes. Computers, Materials & Continua 78(1) (2024)
Peng, Y., Zhang, Y., Xiong, Z., Sun, X., Wu, F.: GET: group event transformer for event-based vision. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 6038–6048 (2023)
Wan, Z., Zhang, J., Chen, D., Liao, J.: High-fidelity pluralistic image completion with transformers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 4692–4701 (2021)
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J.: Attention is all you need. Adv. Neural Inf. Process. Syst. 30, 5998–6008 (2017)
Esser, P., Rombach, R., Ommer, B.: Taming transformers for high-resolution image synthesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12873–12883 (2021)
Zhu, Z., Feng, X., Chen, D., Bao, J., Wang, L., Chen, Y.: Designing a better asymmetric vqgan for stablediffusion. arXiv preprint arXiv:2306.04632 (2023)
Zheng, C., Vuong, T.L., Cai, J., Phung, D.: Movq: Modulating quantized vectors for high-fidelity image generation. Adv. Neural. Inf. Process. Syst. 35, 23412–23425 (2022)
Yoo, Y., Choi, J.: Topic-VQ-VAE: leveraging latent codebooks for flexible topic-guided document generation. In: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38, pp. 19422–19430 (2024)
Liu, Q., Tan, Z., Chen, D., Chu, Q., Dai, X., Chen, Y.: Reduce information loss in transformers for pluralistic image inpainting. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11347–11357 (2022)
Zheng, C., Song, G., Cham, T. J., Cai, J., Phung, D., Luo, L.: High-quality pluralistic image completion via code shared vqgan. arXiv preprint arXiv:2204.01931 (2022)
Van Den Oord, A., Vinyals, O.: Neural discrete representation learning. Adv. Neural Inf. Process. Syst. 30, 6309–6318 (2017)
Cui, Y., Ren, W., Knoll, A.: Omni-kernel network for image restoration. In: Proceedings of the AAAI Conference on Artificial Intelligence, pp. 1426–1434 (2024)
Cui, Y., Tao, Y., Bing, Z., Ren, W., Gao, X., Cao, X., Knoll, A.: Selective frequency network for image restoration. In: The Eleventh International Conference on Learning Representations (2023)
Cui, Y., Ren, W., Cao, X., Knoll, A.: Focal network for image restoration. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 13001–13011 (2023)
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D.: An image is worth 16x16 words: transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
Ho, J., Kalchbrenner, N., Weissenborn, D., Salimans, T.: Axial attention in multidimensional transformers. arXiv preprint arXiv:1912.12180 (2019)
Dong, X., Bao, J., Chen, D., Zhang, W., Yu, N., Yuan, L.: Cswin transformer: a general vision transformer backbone with cross-shaped windows. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12124–12134 (2022)
Zheng, C., Cham, T. J., Cai, J., Phung, D.: Bridging global context interactions for high-fidelity image completion. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11512–11522 (2022)
Razavi, A., Van den Oord, A., Vinyals, O.: Generating diverse high-fidelity images with vq-vae-2. Adv. Neural Inf. Process. Syst. 32, 14866–14876 (2019)
Chen, C., Shi, X., Qin, Y., Li, X., Han, X., Yang, T., Guo, S.: Real-world blind super-resolution via feature matching with implicit high-resolution priors. In: Proceedings of the 30th ACM International Conference on Multimedia, pp. 1329–1338 (2022)
Johnson, J., Alahi, A., Fei-Fei, L.: Perceptual losses for real-time style transfer and super-resolution. In: Computer Vision–ECCV 2016: 14th European Conference, pp. 694–711. Springer (2016)
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B.: Generative adversarial networks. Commun. ACM 63(11), 139–144 (2020)
Gatys, L. A., Ecker, A. S., Bethge, M.: Image style transfer using convolutional neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2414–2423 (2016)
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014)
Bengio, Y., Léonard, N., Courville, A.: Estimating or propagating gradients through stochastic neurons for conditional computation. arXiv preprint arXiv:1308.3432 (2013)
Suvorov, R., Logacheva, E., Mashikhin, A., Remizova, A.: Resolution-robust large mask inpainting with Fourier convolutions. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 2149–2159 (2022)
Guo, M.H., Lu, C.Z., Liu, Z.N., Cheng, M.M., Hu, S.M.: Visual attention network. Computational Visual. Media 9(4), 733–752 (2023)
Zhang, B., Sennrich, R.: Root mean square layer normalization. Adv. Neural Inf. Process. Syst. 32, 12360–12371 (2019)
Ramachandran, P., Zoph, B., Le, Q. V.: Searching for activation functions. arXiv preprint arXiv:1710.05941 (2017)
Karras, T., Aila, T., Laine, S., Lehtinen, J.: Progressive growing of gans for improved quality, stability, and variation. arXiv preprint arXiv:1710.10196 (2017)
Zhou, B., Lapedriza, A., Khosla, A., Oliva, A., Torralba, A.: Places: a 10 million image database for scene recognition. IEEE Trans. Pattern Anal. Mach. Intell. 40(6), 1452–1464 (2017)
Liu, G., Reda, F. A., Shih, K. J., Wang, T. C., Tao, A., Catanzaro, B.: Image inpainting for irregular holes using partial convolutions. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 85–100 (2018)
Nazeri, K., Ng, E., Joseph, T., Qureshi, F. Z., Ebrahimi, M.: Edgeconnect: generative image inpainting with adversarial edge learning. arXiv preprint arXiv:1901.00212 (2019)
Li, W., Lin, Z., Zhou, K., Qi, L., Wang, Y., Jia, J.: Mat: Mask-aware transformer for large hole image inpainting. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10758–10768 (2022)
Funding
This work was funded by the National Natural Science Foundation of China (No. 62062061, No. 62263028) and the Xizang Minzu University Internal Research Project (No. 324132400307).
Author information
Authors and Affiliations
Contributions
JB: Literature search, experimentation, data analysis, and drafting of the manuscript. YF: Conceptualization of the study, design of methods, overall supervision, rigorous review, and editing. ZZ: Study design, data acquisition, and modification of methods. All authors reviewed and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Ethical approval
Not applicable, as the research did not involve human subjects, animals, or the collection of personal data.
Additional information
Communicated by Yongdong Zhang.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Bai, J., Fan, Y. & Zhao, Z. Discrete codebook collaborating with transformer for thangka image inpainting. Multimedia Systems 30, 238 (2024). https://doi.org/10.1007/s00530-024-01439-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00530-024-01439-0