
Abstract
People process things and express feelings through actions, action recognition has been able to be widely studied, yet under-explored. Traditional self-supervised skeleton-based action recognition focus on joint point features, ignoring the inherent semantic information of body structures at different scales. To address this problem, we propose a multi-scale Motion Contrastive Learning of Visual Representations (MsMCLR) model. The model utilizes the Multi-scale Motion Attention (MsM Attention) module to divide the skeletal features into three scale levels, extracting cross-frame and cross-node motion features from them. To obtain more motion patterns, a combination of strong data augmentation is used in the proposed model, which motivates the model to utilize more motion features. However, the feature sequences generated by strong data augmentation make it difficult to maintain identity of the original sequence. Hence, we introduce a dual distributional divergence minimization method, proposing a multi-scale motion loss function. It utilizes the embedding distribution of the ordinary augmentation branch to supervise the loss computation of the strong augmentation branch. Finally, the proposed method is evaluated on NTU RGB+D 60, NTU RGB+D 120, and PKU-MMD datasets. The accuracy of our method is 1.4–3.0% higher than the frontier models.








Similar content being viewed by others
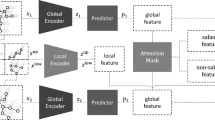

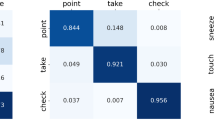
Data availability
Data is openly available in a public repository. The NTU RGB+D 60 and NTU RGB+D 120 datasets that support the findings of this study are openly available in Rose Lab at https://doi.org/10.48550/arXiv.1604.02808; and https://doi.org/10.1109/TPAMI.2019.2916873. The PKU-MMD dataset that supports the findings of this study is openly available in PKU-NIP-Lab at https://doi.org/10.48550/arXiv.1703.07475.
References
Qin, Z., Liu, Y., Perera, M., Gedeon, T., Ji, P., Kim, D., Anwar, S.: Anubis: Skeleton action recognition dataset, review, and benchmark. arXiv preprint arXiv:2211.09590. (2022)
Khan, M.A., Mittal, M., Goyal, L.M., Roy, S.: A deep survey on supervised learning based human detection and activity classification methods. Multimed. Tools and Appl. 80(18), 27867–27923 (2021)
Varshney, N., Bakariya, B., Kushwaha, A.K.S.: Human activity recognition using deep transfer learning of cross position sensor based on vertical distribution of data. Multimed. Tools Appl. 81(16), 22307–22322 (2022)
Guo, Z., Hou, Y., Xiao, R., Li, C., Li, W.: Motion saliency based hierarchical attention network for action recognition. Multimed. Tools Appl. 82(3), 4533–4550 (2023)
Gao, J., Zhang, T., Xu, C.: I know the relationships: zero-shot action recognition via two-stream graph convolutional networks and knowledge graphs. Proc. AAAI Conf. Artif. Intell. 33(1), 8303–8311 (2019)
Gao, J., Chen, M., Xu, C.: Vectorized evidential learning for weakly-supervised temporal action localization. IEEE transactions on pattern analysis and machine intelligence (2023)
Tran, D., Bourdev, L., Fergus, R., Torresani, L., Paluri, M.: Learning spatiotemporal features with 3D convolutional networks. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 4489–4497 (2015)
Jalal, A., Kim, Y.H., Kim, Y.J., Kamal, S., Kim, D.: Robust human activity recognition from depth video using spatiotemporal multi-fused features. Pattern Recognit. 61, 295–308 (2017)
Akula, A., Shah, A.K., Ghosh, R.: Deep learning approach for human action recognition in infrared images. Cogn. Syst. Res. 50, 146–154 (2018)
Yan, S., Xiong, Y., Lin, D.: Spatial temporal graph convolutional networks for skeleton-based action recognition. In: Proceedings of the AAAI Conference on Artificial Intelligence (2018)
Zhang, Z., Lan, C., Zeng, W., Chen, Z.: Densely semantically aligned person re-identification. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 667–676 (2019)
Karianakis, N., Liu, Z., Chen, Y., Soatto, S.: Reinforced temporal attention and split-rate transfer for depth-based person re-identification. In: Proceedings of the European Conference on Computer Vision, pp. 715–733 (2018)
Ge, Y., Zhu, F., Chen, D., Zhao, R., Li, H.: Self-paced contrastive learning with hybrid memory for domain adaptive object re-id. In: Proceedings of the Annual Conference on Neural Information Processing Systems (2020)
Wang, Y., Li, M., Cai, H., Chen, W., Han, S.: Lite pose: Efficient architecture design for 2d human pose estimation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 13126–13136 (2022)
Zhou, Y., Li, C., Cheng, Z.Q., Geng, Y., Xie, X., Keuper, M.: Hypergraph transformer for skeleton-based action recognition. arXiv preprint arXiv:2211.09590 (2022)
Zhang, J., Lin, L., Liu, J.: Hierarchical consistent contrastive learning for skeleton-based action recognition with growing augmentations. Proc. AAAI Conf. Artif. Intell. 37(3), 3427–3435 (2023)
Peng, K., Yin, C., Zheng, J., Liu, R., Schneider, D., Zhang, J., Yang, K., Saquib Sarfraz, M., Stiefelhagen, R., Roitberg, A.: Navigating open set scenarios for skeleton-based action recognition. Proc. AAAI Conf. Artif. Intell. 38(5), 4487–4496 (2024)
Chen, Y., Zhang, Z., Yuan, C., Li, B., Deng, Y., Hu, W.: Channel-wise topology refinement graph convolution for skeleton-based action recognition. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 13359–13368 (2021)
Chi, H., Ha, M.H., Chi, S., Lee, S.W., Huang, Q., Ramani, K.: Infogcn: Representation learning for human skeleton-based action recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 20186–20196 (2022)
Ye, F., Pu, S., Zhong, Q., Li, C., Xie, D., Tang, H.: Dynamic gcn: Context-enriched topology learning for skeleton-based action recognition. In: Proceedings of the 28th ACM international conference on multimedia, pp. 55–63 (2020)
Zhang, P., Lan, C., Zeng, W., Xing, J., Xue, J., Zheng, N.: Semantics-guided neural networks for efficient skeleton-based human action recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1112–1121 (2020)
Chen, Z., Li, S., Yang, B., Li, Q., Liu, H.: Multi-scale spatial temporal graph convolutional network for skeleton-based action recognition. In: Proceedings of the AAAI Conference on Artificial Intelligence, pp. 1113–1122 (2021)
Kim, B., Chang, H.J., Kim, J., Choi, J.Y.: Global-local motion transformer for unsupervised skeleton-based action learning. In: Proceedings of the European Conference on Computer Vision, pp. 209–225 (2022)
Su, K., Liu, X., Shlizerman, E.: Predict cluster: Unsupervised skeleton based action recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 9631–9640 (2020)
Yang, S., Liu, J., Lu, S., Er, M.H., Kot, A.C.: Skeleton cloud colorization for unsupervised 3d action representation learning. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 13423–13433 (2021)
Zheng, N., Wen, J., Liu, R., Long, L., Dai, J., Gong, Z.: Unsupervised representation learning with long-term dynamics for skeleton based action recognition. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 32, no. 1 (2018)
Wu, W., Hua, Y., Zheng, C., Wu, S., Chen, C., Lu, A.: Skeletonmae: Spatial-temporal masked autoencoders for self-supervised skeleton action recognition. In: Proceedings of the IEEE International Conference on Multimedia and Expo Workshops, pp. 224–229 (2023)
Rao, H., Xu, S., Hu, X., Cheng, J., Hu, B.: Augmented skeleton based contrastive action learning with momentum lstm for unsupervised action recognition. Inf. Sci. 569, 90–109 (2021)
Guo, T., Liu, H., Chen, Z., Liu, M., Wang, T., Ding, R.: Contrastive learning from extremely augmented skeleton sequences for self-supervised action recognition. Inf. Sci. 36(1), 762–770 (2022)
Dang, L., Nie, Y., Long, C., Zhang, Q., Li, G.: Msr-gcn: Multi-scale residual graph convolution networks for human motion prediction. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 11467–11476 (2021)
Rao, H., Miao, C.: Skeleton prototype contrastive learning with multi-level graph relation modeling for unsupervised person re-identification. arXiv preprint arXiv:2208.11814. (2022)
Xu, B., Shu, X.: Pyramid self-attention polymerization learning for semi-supervised skeleton-based action recognition. arXiv preprint arXiv:2302.02327 (2023)
Jiang, S., Sun, B., Wang, L., Bai, Y., Li, K., Fu, Y.: Skeleton aware multi-modal sign language recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3413–3423 (2021)
Li, L., Wang, M., Ni, B., Wang, H., Yang, J., Zhang, W.: 3d human action representation learning via cross-view consistency pursuit. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4741–4750 (2021)
Chen, Z., Liu, H., Guo, T., Chen, Z., Song, P., Tang, H.: Contrastive learning from spatio-temporal mixed skeleton sequences for self-supervised skeleton-based action recognition. arXiv preprint arXiv:2207.03065 (2022)
R., V., Chellapa, R.: Rolling rotations for recognizing human actions from 3d skeletal data. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4471–4479 (2016)
Chen, X., Fan, H., Girshick, R., He, K.: Improved baselines with momentum contrastive learning. arXiv preprint arXiv:2003.04297 (2020)
Oord, A., Li, Y., Vinyals, O.: Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748 (2018)
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser., Polosukhin, I.: Attention is all you need. In: Proceedings of the Advances in Neural Information Processing Systems, 30 (2017)
Khan, S., Naseer, M., Hayat, M., Zamir, S.W., Khan, F.S., Shah, M.: Transformers in vision: a survey. ACM Comput. Surv. 54(10s), 1–41 (2021)
Li, M., Chen, S., Zhao, Y., Zhang, Y., Wang, Y., Tian, Q.: Dynamic multi-scale graph neural networks for 3d skeleton based human motion prediction. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 214–223 (2020)
Gebotys, B., Wong, A., Clausi, D.A.: M2a: Motion aware attention for accurate video action recognition. In: Proceedings of the 19th IEEE Conference on Robots and Vision, pp. 83–89 (2022)
Wang, X., Qi, G.J.: Contrastive learning with stronger augmentations. IEEE Trans. Pattern Anal. Mach. Intell. 45(5), 5549–5560 (2022)
Yoon, Y., Yu, J., Jeon, M.: Predictively encoded graph convolutional network for noise-robust skeleton-based action recognition. Appl. Intell. 52, 2317–2331 (2022)
Shorten, C., Khoshgoftaar, T.M.: A survey on image data augmentation for deep learning. J. Big Data 6(1), 60 (2019)
Shahroudy, A., Liu, J., Ng, T.T., Wang, G.: Ntu rgb+d: A large scale dataset for 3D human activity analysis. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1010–1019 (2016)
Liu, J., Shahroudy, A., Perez, M.L., Wang, G., Duan, L.Y., Chichung, A.K.: Ntu rgb+d 120: A large-scale benchmark for 3D human activity understanding. In: IEEE transactions on pattern analysis and machine intelligence (2019)
Liu, C., Hu, Y., Li, Y., Song, S., Liu, J.: Pku-mmd: A large scale benchmark for skeleton-based human action understanding. In: Proceedings of the Workshop on Visual Analysis in Smart and Connected Communities, pp. 1–8 (2017)
Lin, L., Song, S., Yang, W., Liu, J.: Ms2l: Multi-task self-supervised learning for skeleton based action recognition. In: Proceedings of the 28th ACM International Conference on Multimedia, pp. 2490–2498 (2020)
Nie, Q., Liu, Z.W., Liu, Y.H.: Unsupervised 3d human pose representation with viewpoint and pose disentanglement. In: Proceedings of the European Conference on Computer Vision, pp. 102–118 (2020)
Zhou, Y., Duan, H., Rao, A., Su, B., Wang, J.: Self-supervised action representation learning from partial spatio-temporal skeleton sequences. Proc. AAAI Conf. Artif. Intell. 37(3), 3825–3833 (2023)
Thoker, F.M., Doughty, H., Snoek, C.G.M.: Skeleton-contrastive 3D action representation learning. In: Proceedings of the 29th ACM International Conference on Multimedia, pp. 1655–1663 (2021)
Zhang, P., Lan, C., Xing, J., Zeng, W., Xue, J., Zheng, N.: View adaptive neural networks for high performance skeleton-based human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 41(8), 1963–1978 (2019)
Van Der Maaten, L., Hinton, G.: Visualizing data using t-sne. J. Mach. Learn. Res. 9(11), 2579–2605 (2008)
Acknowledgements
The authors would like to thank the reviewers and editor for their valuable comments and suggestions.
Funding
This research was supported in part by the Guangxi Natural Science Foundation (2024GXNSFAA010493), National Natural Science Foundation of China (61862015, 62371350), Science and Technology Project of Guangxi (AD23023002, AD21220114), Guangxi Key Research and Development Program (AB17195025).
Author information
Authors and Affiliations
Contributions
Y. W. conceived the original idea and wrote the paper; M. Y. collected and tested skeleton-based motion recognition; Z. X., T. T., R. M., and Z. W. analyzed the data and revised the paper. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no Conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Wu, Y., Xu, Z., Yuan, M. et al. Multi-scale motion contrastive learning for self-supervised skeleton-based action recognition. Multimedia Systems 30, 267 (2024). https://doi.org/10.1007/s00530-024-01463-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00530-024-01463-0